

Praneeta Mallela. 13 de octubre. KDnuggets. MEDIUM
Se observa un aumento en el uso de modelos LLM y fundamentales (solo API) preentrenados para diversos servicios y aplicaciones. Estos modelos son especialmente útiles cuando el objetivo es demostrar el funcionamiento de un sistema antes de conceptualizarlo por completo. Pero ¿cómo se verifica su eficacia para un caso de uso específico cuando el modelo es inamovible?
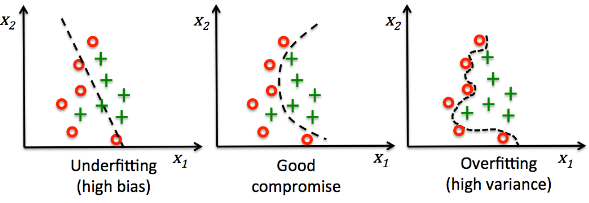
En tales casos, la atención se centra en la ingeniería rápida, la regularización a través de datos y el ajuste con las API disponibles.
En mi artículo anterior , expliqué cómo se añade la regularización directamente a un modelo mediante técnicas conocidas como la regularización L1/L2 y la desintegración de pesos. En este artículo, analizaremos cómo se puede lograr la regularización sin modificar el modelo, manipulando los datos.
Pero ¿qué datos se pueden manipular realmente? La regularización mediante datos es mucho más que simplemente aumentarlos. Al analizar los «datos» en general, vemos que existe la entrada que proporciona la característica, la etiqueta que fija la verdad fundamental y, opcionalmente, una indicación que contiene el contexto y define reglas o instrucciones. Todos estos datos se pueden modificar para mejorar el aprendizaje y la generalización.
A continuación se muestra una lista de técnicas que logran la regularización a través de datos:
- Aumento de datos
- Inyección de ruido
- Suavizado de etiquetas
- Remuestreo o reponderación de datos
- Aprendizaje curricular
- Generación de muestras contrastivas
Aumento de datos e inyección de ruido
Estas técnicas se aplican a los datos de entrada para generar variabilidad en la distribución de entrada. Ambas promueven predicciones de salida uniformes y estables en presencia de ruido. Esto se logra porque el modelo aprende de señales más allá de las perturbaciones de entrada fáciles de aprender, logrando así la regularización.
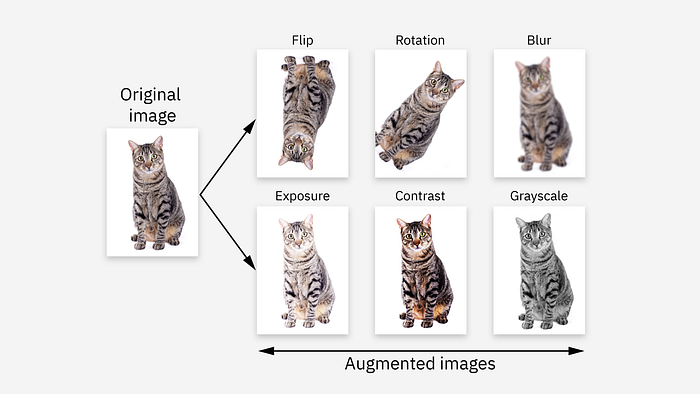
Aumento de datos
El aumento de datos agrega variabilidad al aplicar transformaciones amigables con el tipo de entrada a los datos mientras mantiene la consistencia de las etiquetas.
En visión artificial, esto incluye transformaciones geométricas como giros horizontales/verticales, rotaciones, traslaciones y transformaciones afines. Es fundamental que tanto la imagen como su realidad fundamental (p. ej., máscaras de segmentación, cuadros delimitadores, etc.) se sometan a las mismas transformaciones para preservar la precisión. Ejemplo:
En PNL y LLM, el aumento de texto puede ocurrir en múltiples niveles:
- Aumentos de texto: reemplazar palabras con sus sinónimos o realizar una traducción inversa (traducir a otro idioma y luego al original). Ejemplos: «médico» -> «doctor», «estudiar» -> «aprender», «enfermero» -> «cuidador».
- Aumento de indicaciones: reestructurar instrucciones o sustituir frases conservando la intención original. Ejemplos: «resumir» -> «breve resumen», «resumir» -> «en pocas palabras», «breve resumen» -> «en menos de 200 palabras».
Inyección de ruido
La inyección de ruido aplica perturbaciones estocásticas en lugar de transformaciones estructuradas. En visión artificial, se puede añadir ruido gaussiano o uniforme a los valores de los píxeles. En PLN, la omisión y el enmascaramiento de tokens inyectan ruido en la representación o incrustación de entrada (nota: no en la entrada de texto sin procesar).
Al generar datos desde un simulador, es importante introducir las entradas aumentadas o con ruido en el propio simulador en lugar de posprocesarlas. Esto garantiza que las salidas correspondientes reflejen las perturbaciones inyectadas.
Suavizado de etiquetas y remuestreo de datos
Estas técnicas se aplican al espacio objetivo, no al espacio de entrada. Una modifica las etiquetas y la otra, la frecuencia de aparición de ciertos objetivos . Ambas solucionan el problema del exceso de confianza y el sesgo hacia clases sobrerrepresentadas, lo que genera regularización.
Suavizado de etiquetas
El suavizado de etiquetas ayuda a corregir el exceso de confianza al suavizar las codificaciones one-hot. En lugar de asignar un valor estricto de 1.0 a la clase verdadera y 0.0 a las demás, una pequeña probabilidad de la clase verdadera se redistribuye entre las incorrectas, creando etiquetas más suaves. La fórmula:
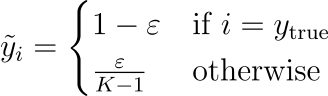
Se utiliza habitualmente en tareas de clasificación o cualquier tarea que involucre probabilidades softmax. Ejemplo:
Etiqueta: [1.0, 0.0, 0.0]
Después del suavizado de etiquetas: [0,95, 0,025, 0,025]
Remuestreo de datos (o reponderación)
El remuestreo de datos se utiliza para corregir el desequilibrio de clases en los datos de entrenamiento. Existen dos estrategias de muestreo para solucionarlo:
- Submuestreo: reducción de muestras a partir de muestras sobrerrepresentadas
- Sobremuestreo: aumento de muestras o amplificación sintética de muestras subrepresentadas
Esto se traduce efectivamente en un aumento de la influencia de las clases subrepresentadas. Equivale a aplicar una mayor ponderación o penalización de pérdida a estas clases durante el entrenamiento mediante un proceso llamado reponderación de datos. Mientras que el remuestreo de datos modifica la distribución de datos que observa el modelo, la reponderación de datos diseña la contribución de pérdida por clase sin modificar los datos. Ambos métodos ayudan a evitar el sesgo hacia las clases mayoritarias y a impulsar al modelo a aprender límites de decisión equilibrados.
Aprendizaje curricular y generación de muestras contrastivas
Estas técnicas controlan la trayectoria de aprendizaje del modelo controlando cómo y en qué orden se le presentan los datos. Al estructurar el propio proceso de entrenamiento, introducen una forma de regularización procedimental basada en datos; es decir, el modelo aprende de forma progresiva y robusta en lugar de memorizar patrones prematuramente.
Aprendizaje curricular
El aprendizaje curricular organiza los datos en un orden basado en tareas o dificultad, comenzando con los datos más sencillos y progresando gradualmente hacia los más complejos. De ahí el nombre «curriculum». Este método mejora la velocidad de convergencia, estabiliza el entrenamiento inicial y mejora la generalización del modelo al aprender rutas de optimización más fluidas (que de otro modo podrían ser inestables). Ejemplos:
- En visión artificial, un modelo se entrena para detectar primero objetos antes de aprender el reconocimiento de escenas.
- En el aprendizaje de refuerzo, los agentes pueden ser entrenados para aprender a caminar antes de realizar tareas más complejas, como evitar obstáculos o patear una pelota.
Generación de muestras contrastivas
El aprendizaje contrastivo se regulariza en el espacio de incrustación al enseñar al modelo qué muestras son similares y cuáles son diferentes. Se utiliza cuando los datos etiquetados son escasos o no están disponibles. Las etiquetas se generan implícitamente y el modelo se optimiza para agrupar las muestras positivas y separar las negativas de las positivas en el espacio de incrustación. Esto configura el espacio de representación, lo que permite al modelo aprender características robustas y generalizables. Ejemplos:
- SimCLR o MoCo ( consulte mi artículo sobre MoCo ) en visión por computadora: las imágenes positivas son versiones aumentadas de la misma imagen y las negativas son cualquier otra imagen.
- En PNL: contrastar el aprendizaje de paráfrasis de oraciones con oraciones no relacionadas.
En la práctica, se utilizan varias de estas técnicas para obtener el mejor rendimiento. Por ejemplo, usar el aprendizaje curricular en un conjunto de datos aumentados o aplicar el suavizado de etiquetas con reponderación de clases puede generar beneficios.
Conclusión
La regularización mediante datos es una herramienta fundamental en el conjunto de herramientas de entrenamiento, especialmente para modelos basados únicamente en API, cuya arquitectura está congelada. Esto destaca que existen otros aspectos clave del entrenamiento que se basan en la filosofía de cómo se componen y presentan los datos al modelo.
Ya sea a través de aumento, ruido controlado, suavizado de etiquetas, reponderación de datos o estrategias de presentación estructurada como el aprendizaje curricular y contrastivo, cada uno de estos métodos ayuda a guiar el modelo hacia una mejor generalización.
Ajustar los pesos o modificar las arquitecturas de los modelos no son las únicas maneras de mejorar la generalización. Es importante recordar que contar con buenas prácticas de regularización de datos puede traducirse en una buena enseñanza.
¡Gracias por leer! Si te interesa leer más artículos sobre aprendizaje automático, sígueme o lee mi publicación » La intuición del aprendizaje automático «.
Aquí hay algunos otros artículos que mencioné en esta publicación:


