
Fareed Khan. MEDIUM Septiembre 2023
Entiendo que la arquitectura del transformador puede parecer aterradora y es posible que hayas encontrado varias explicaciones en YouTube o en blogs. Sin embargo, en mi blog haré un esfuerzo por aclararlo proporcionando un ejemplo numérico completo. Al hacerlo, espero simplificar la comprensión de la arquitectura del transformador.
¡Un agradecimiento a HeduAI por brindar explicaciones claras que me han ayudado a aclarar mis propios conceptos!
¡Empecemos!
Entradas y codificación posicional
Resolvamos la parte inicial donde determinaremos nuestras entradas y calcularemos la codificación posicional para ellas.
Paso 1 (Definir los datos)
El paso inicial es definir nuestro conjunto de datos (corpus) .

En nuestro conjunto de datos, hay 3 frases (diálogos) tomadas del programa de televisión Juego de Tronos. Aunque este conjunto de datos puede parecer pequeño, su tamaño en realidad nos ayuda a encontrar los resultados utilizando las próximas ecuaciones matemáticas.
Paso 2 (Encontrar el tamaño del vocabulario)
Para determinar el tamaño del vocabulario, necesitamos identificar la cantidad total de palabras únicas en nuestro conjunto de datos. Esto es crucial para la codificación (es decir, convertir los datos en números).
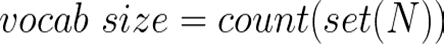
donde N es una lista de todas las palabras y cada palabra es un único token. Dividiremos nuestro conjunto de datos en una lista de tokens, es decir, encontraremos N.

Después de obtener la lista de tokens, denominada N, podemos aplicar una fórmula para calcular el tamaño del vocabulario.

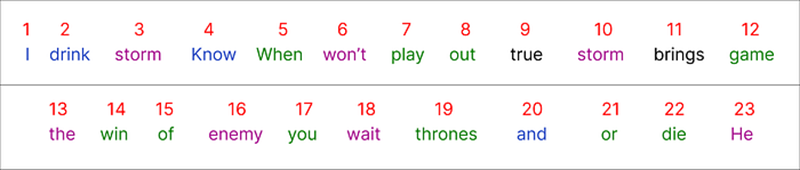
usar una operación de conjunto ayuda a eliminar duplicados y luego podemos contar las palabras únicas para determinar el tamaño del vocabulario. Por lo tanto, el tamaño del vocabulario es 23, ya que hay 23 palabras únicas en la lista dada.
Paso 3 (Codificación e incrustación)
Bien asignamos un número entero a cada palabra única de nuestro conjunto de datos.
Después de codificar todo nuestro conjunto de datos, es hora de seleccionar nuestra entrada. Elegiremos una frase de nuestro corpus para empezar:
“Cuando juegas juego de tronos”
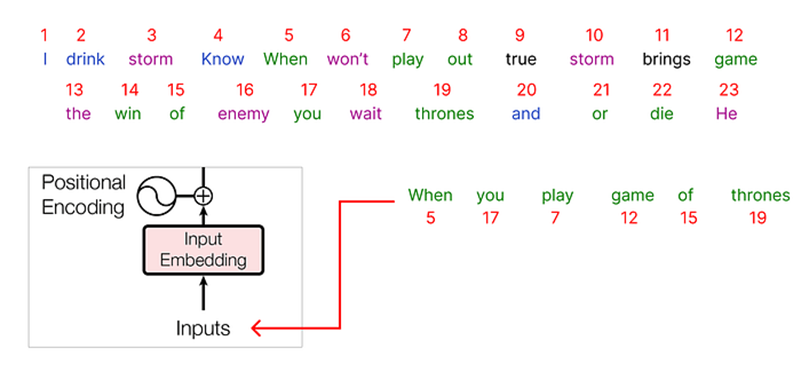
Cada palabra pasada como entrada se representará como un número entero codificado, y cada valor entero correspondiente tendrá una incrustación asociada.
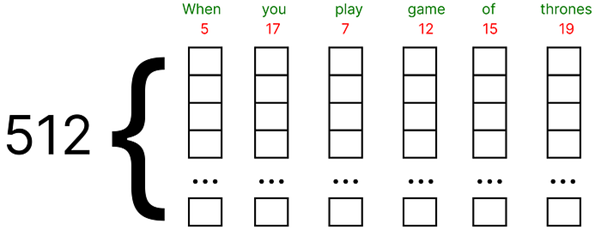
- Estas incrustaciones se pueden encontrar usando Google Word2vec (representación vectorial de la palabra). En nuestro ejemplo numérico, supondremos un vector incrustado para cada palabra llena de valores aleatorios entre (0 y 1).
- Además, el artículo original utiliza 512 dimensiones del vector de incrustación, consideraremos una dimensión muy pequeña, es decir, 5 por ejemplo numérico.
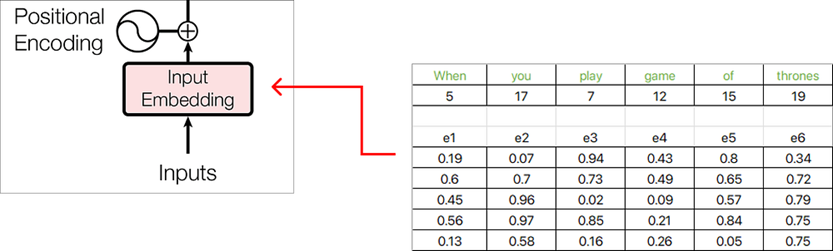
Cada incrustación de palabras ahora está representada por un vector de incrustación de dimensión 5 , y los valores se completan con números aleatorios usando la función de Excel RAND() .
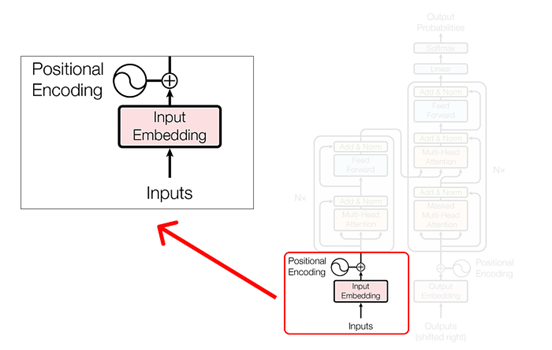
Paso 4 (Incrustación posicional)
Consideremos la primera palabra, es decir, «Cuándo» y calculemos el vector de incrustación posicional para ella.
Hay dos fórmulas para la incrustación posicional:
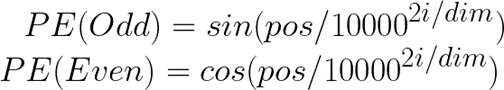
El valor POS para la primera palabra, «Cuando», será cero ya que corresponde al índice inicial de la secuencia. Además, el valor de i , ya sea par o impar, determina qué fórmula utilizar para calcular los valores de PE. El valor de dimensión representa la dimensionalidad de los vectores de incrustación y, en este caso, es 5.
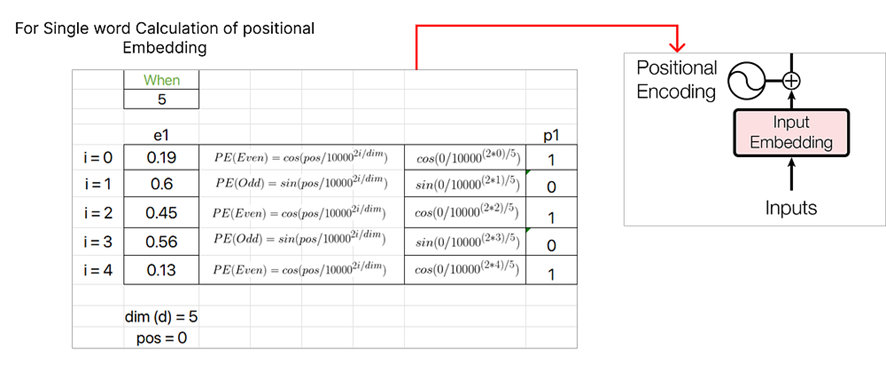
Continuando con el cálculo de incrustaciones posicionales, asignaremos un valor pos de 1 para la siguiente palabra, «usted» , y continuaremos incrementando el valor pos para cada palabra posterior en la secuencia.
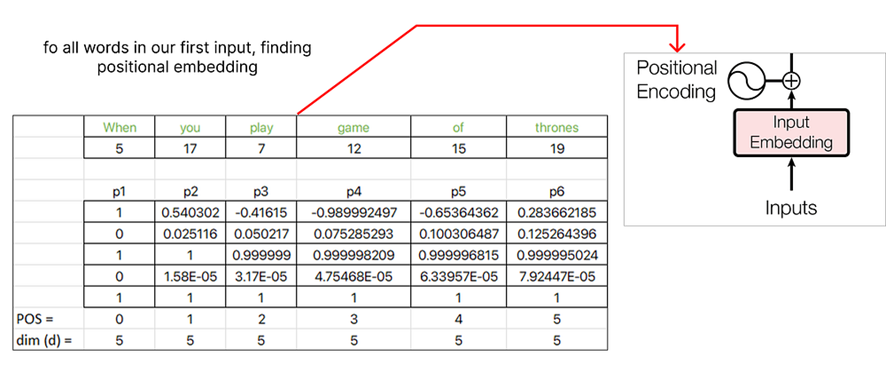
Después de encontrar la incrustación posicional, podemos concatenarla con la palabra incrustada original.
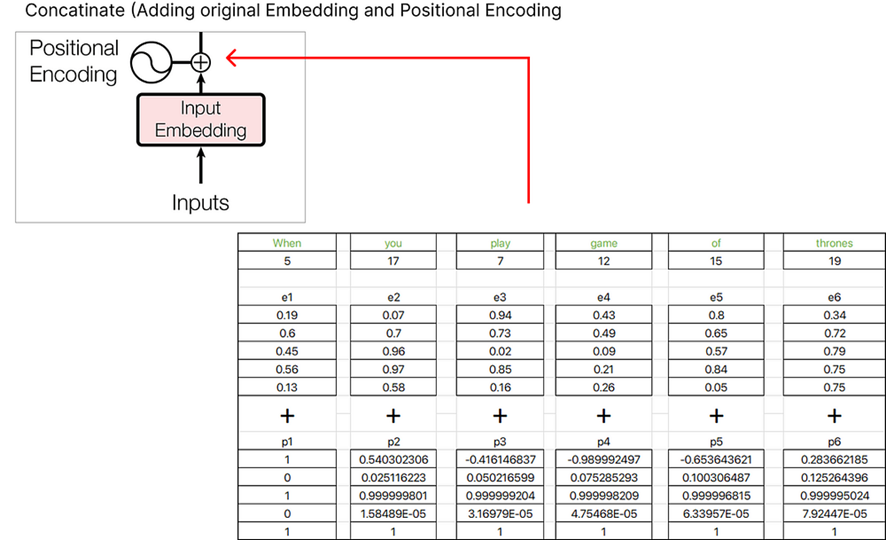
El vector resultante que obtenemos es la suma de e1+p1, e2+p2, e3+p3, etc.
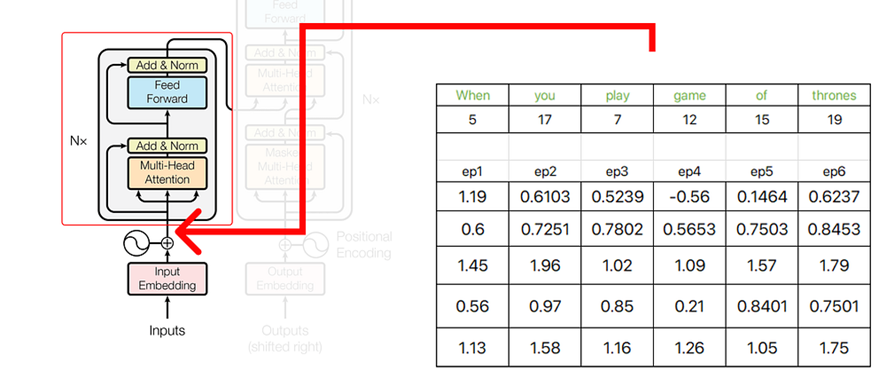
La salida de la parte inicial de nuestra arquitectura de transformador sirve como entrada al codificador.
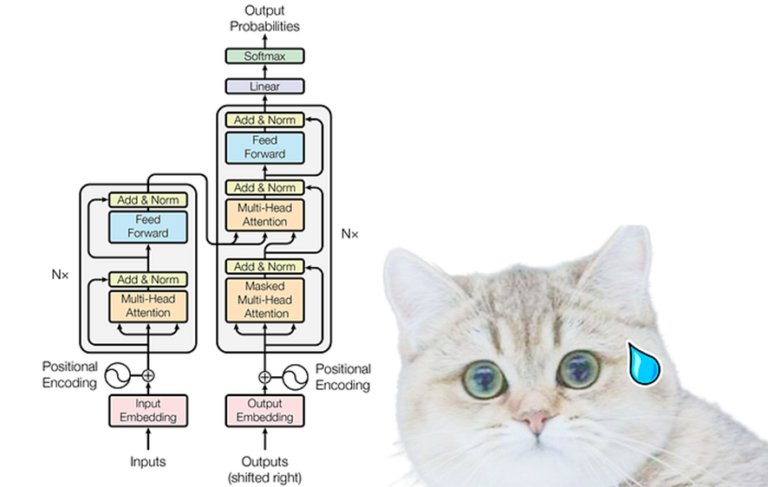
Codificador
En el codificador, realizamos operaciones complejas que involucran matrices de consultas, claves y valores. Estas operaciones son cruciales para transformar los datos de entrada y extraer representaciones significativas.
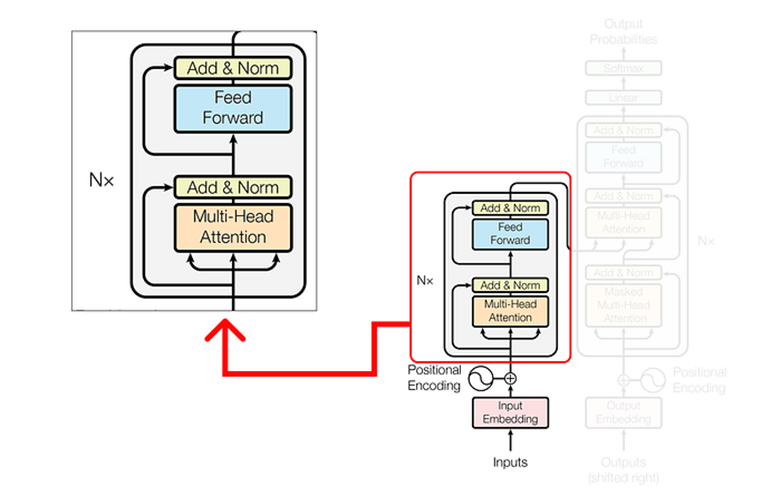
Dentro del mecanismo de atención de múltiples cabezales, una única capa de atención consta de varios componentes clave. Estos componentes incluyen:
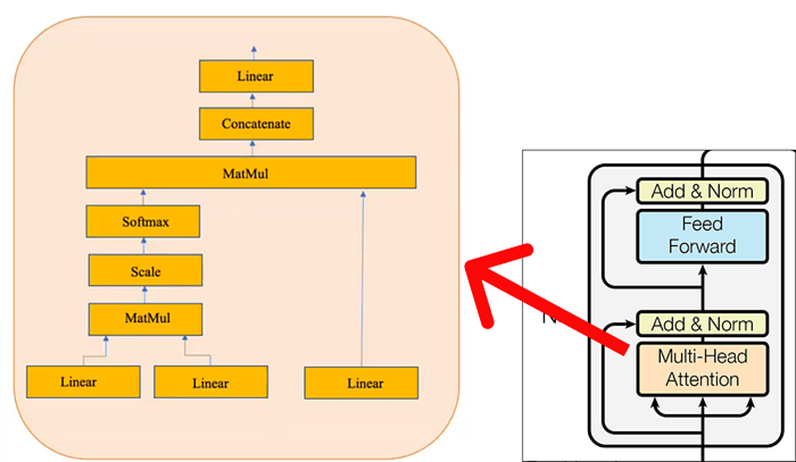
Tenga en cuenta que el cuadro amarillo representa un mecanismo de atención único. Lo que la convierte en una atención de múltiples cabezas es la presencia de múltiples cuadros amarillos. Para los propósitos de este ejemplo numérico, consideraremos sólo uno (es decir, atención de una sola cabeza) como se muestra en el diagrama anterior.
Paso 1 (Realizar la atención con una sola cabeza)
Hay tres entradas en la capa de atención:
- Consulta
- Llave
- Valor

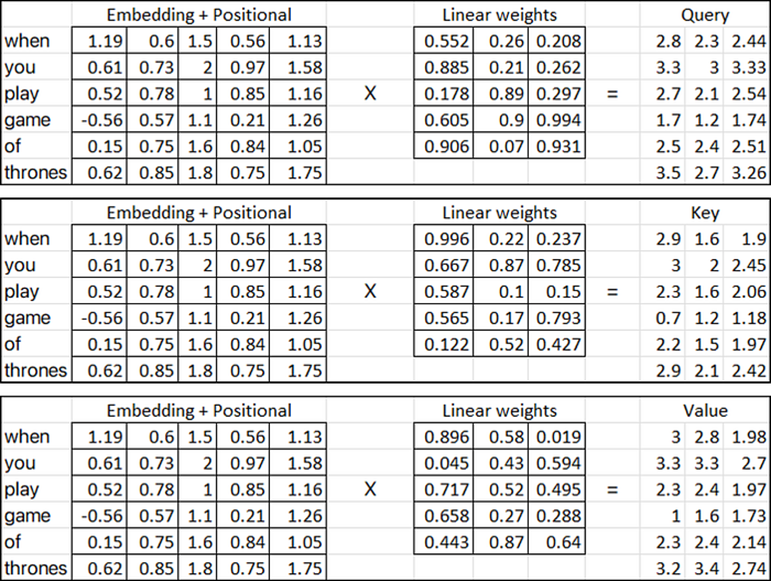
En el diagrama proporcionado anteriormente, las tres matrices de entrada (matrices rosas) representan la salida transpuesta obtenida del paso anterior de agregar las incrustaciones de posición a la matriz de incrustación de palabras.
Por otro lado, las matrices de pesos lineales (amarilla, azul y roja) representan el peso utilizado en el mecanismo de atención. Estas matrices pueden tener cualquier número de dimensiones con respecto a las columnas, pero el número de filas debe ser el mismo que el número de columnas en las matrices de entrada para la multiplicación.
En nuestro caso, asumiremos que las matrices lineales (amarilla, azul y roja) contienen pesos aleatorios. Estos pesos generalmente se inicializan aleatoriamente y luego se ajustan durante el proceso de entrenamiento mediante técnicas como la retropropagación y el descenso de gradiente.
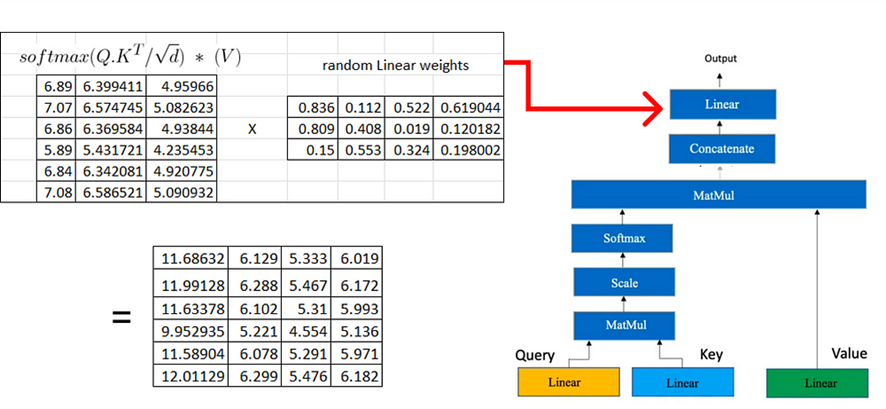
Entonces, calculemos (métricas de consulta, clave y valor):
Una vez que tenemos las matrices de consulta, clave y valor en el mecanismo de atención, procedemos con multiplicaciones de matrices adicionales.
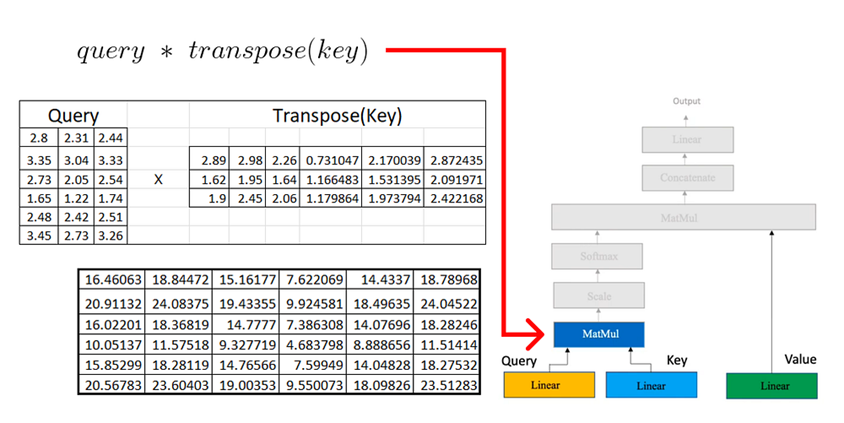

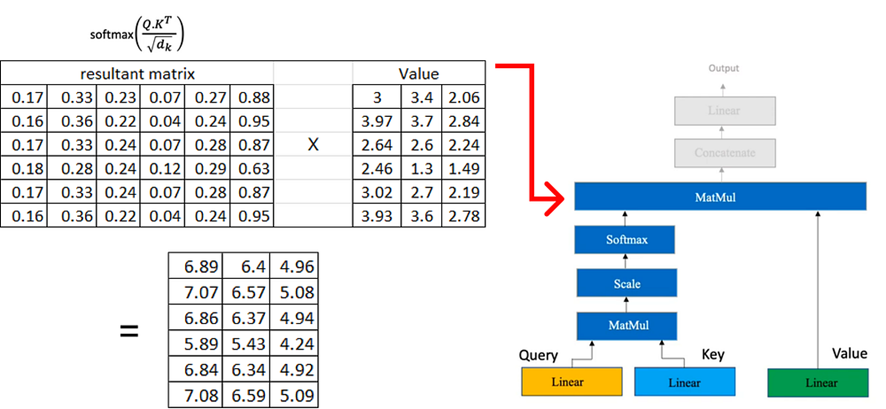
Ahora multiplicamos la matriz resultante por la matriz de valores que calculamos anteriormente:
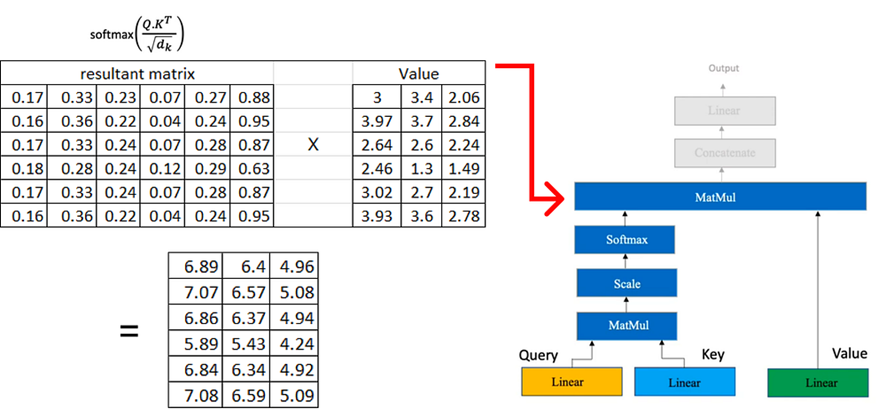
Si tenemos varias atenciones principales, cada una de las cuales produce una matriz de dimensión (6×3), el siguiente paso consiste en concatenar estas matrices.
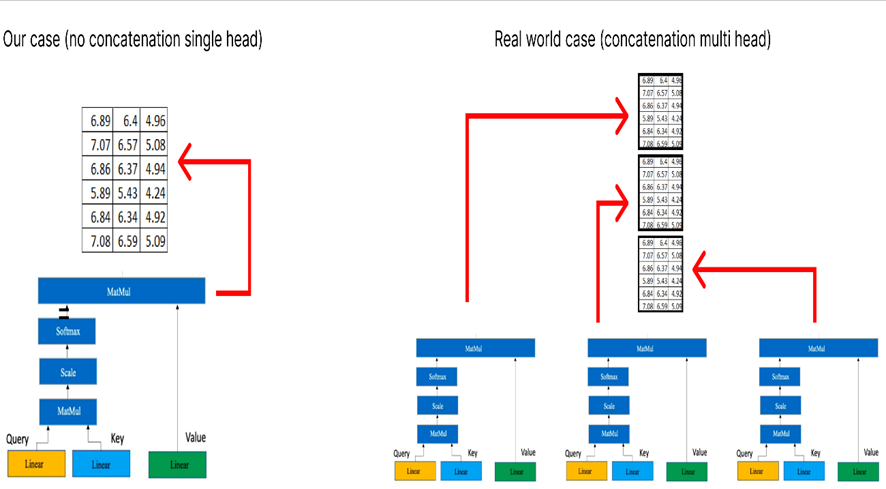
En el siguiente paso, volveremos a realizar una transformación lineal similar al proceso utilizado para obtener las matrices de consulta, clave y valor. Esta transformación lineal se aplica a la matriz concatenada obtenida de las múltiples atenciones principales.
Como el blog ya se está volviendo extenso, en la siguiente parte cambiaremos nuestro enfoque para discutir los pasos involucrados en la arquitectura del codificador.
Si tienes alguna consulta no dudes en preguntarme!
·Escritor para GoPenAI
Fareed Khan aquí
https://medium.com/@fareedkhandev?source=post_page—–a7809015150a——————————–


