

¿Y cómo puedes hacer lo mismo con tus documentos?
Jacob Marks, 3 de marzo de 2025. MEDIUM

Durante los últimos seis meses, he estado trabajando en la startup de serie A Voxel51, y creadora del kit de herramientas de visión artificial de código abierto FiftyOne . Como ingeniero de aprendizaje automático y evangelista de desarrolladores, mi trabajo es escuchar a nuestra comunidad de código abierto y brindarles lo que necesitan: nuevas funciones, integraciones, tutoriales, talleres, lo que sea.
Hace unas semanas, agregamos soporte nativo para motores de búsqueda de vectores y consultas de similitud de texto a FiftyOne, para que los usuarios puedan encontrar las imágenes más relevantes en sus conjuntos de datos (a menudo masivos, que contienen millones o decenas de millones de muestras) a través de simples consultas en lenguaje natural.
Esto nos colocó en una posición curiosa: ahora era posible que las personas que usaban FiftyOne de código abierto buscaran fácilmente conjuntos de datos con consultas en lenguaje natural, pero usar nuestra documentación aún requería la búsqueda tradicional de palabras clave.
Contamos con mucha documentación, lo que tiene sus pros y sus contras. Como usuario, a veces descubro que, dada la gran cantidad de documentación, encontrar exactamente lo que busco requiere más tiempo del que me gustaría.
No iba a dejar que esto saliera adelante… así que construí esto en mi tiempo libre:
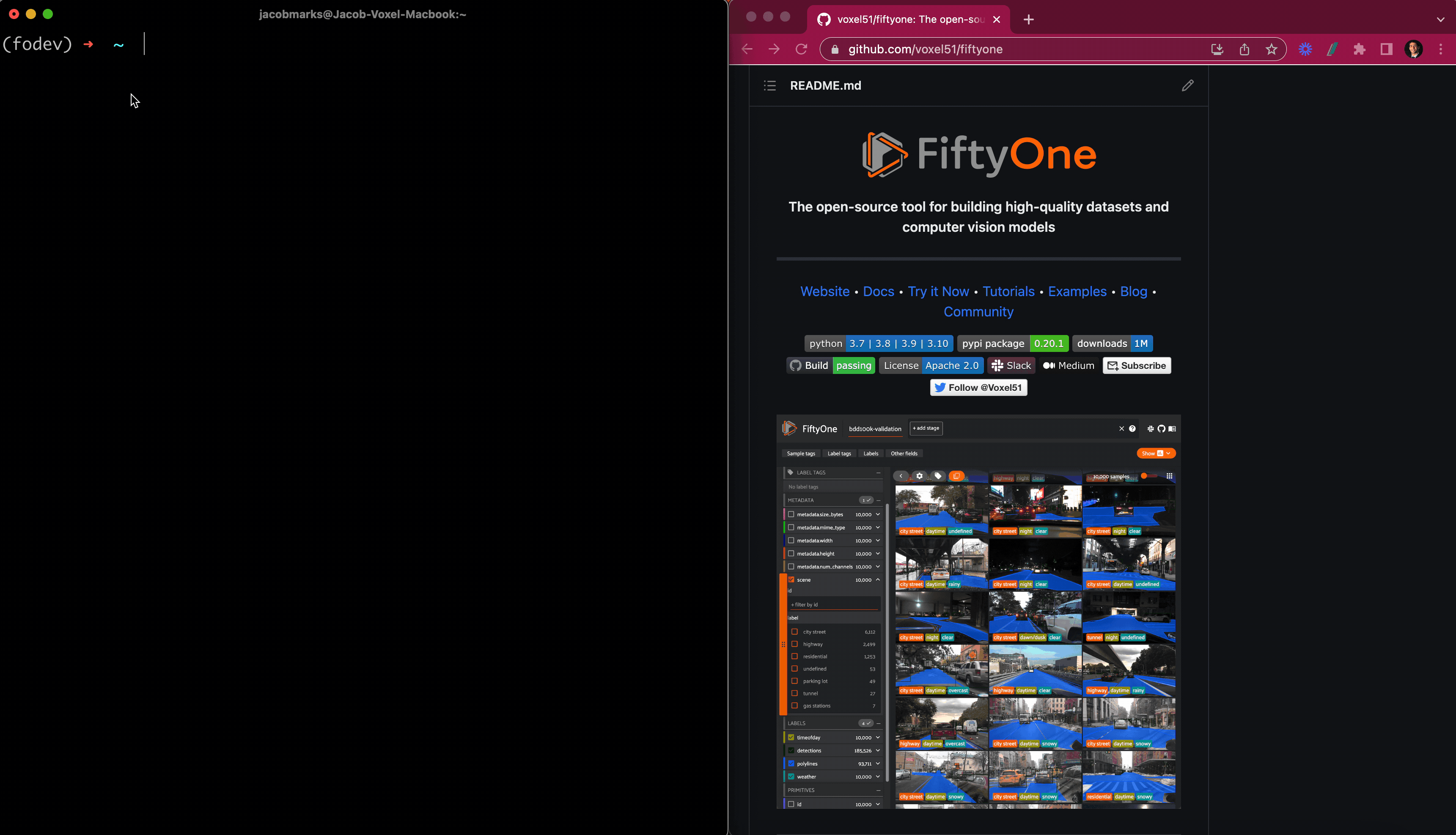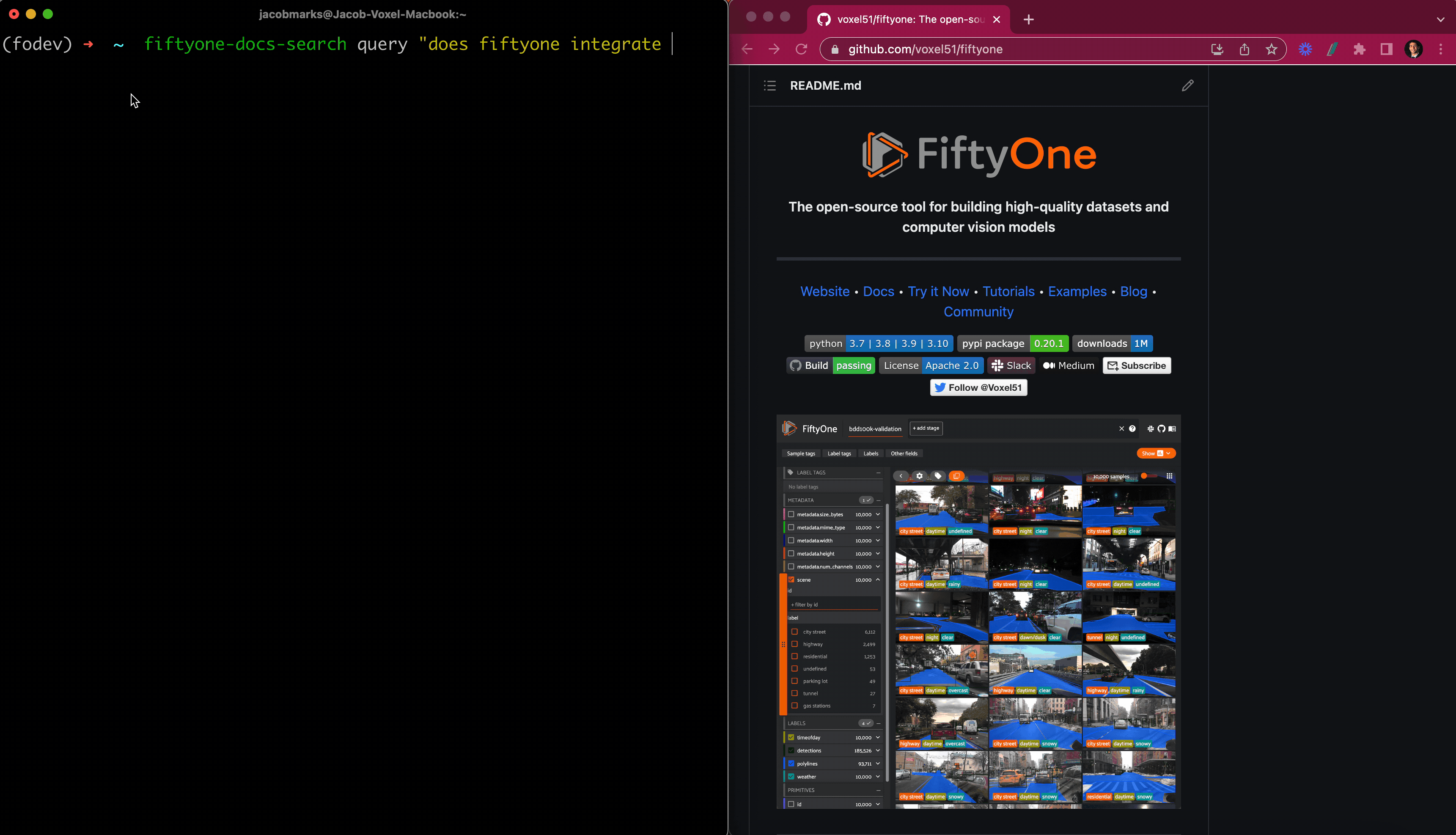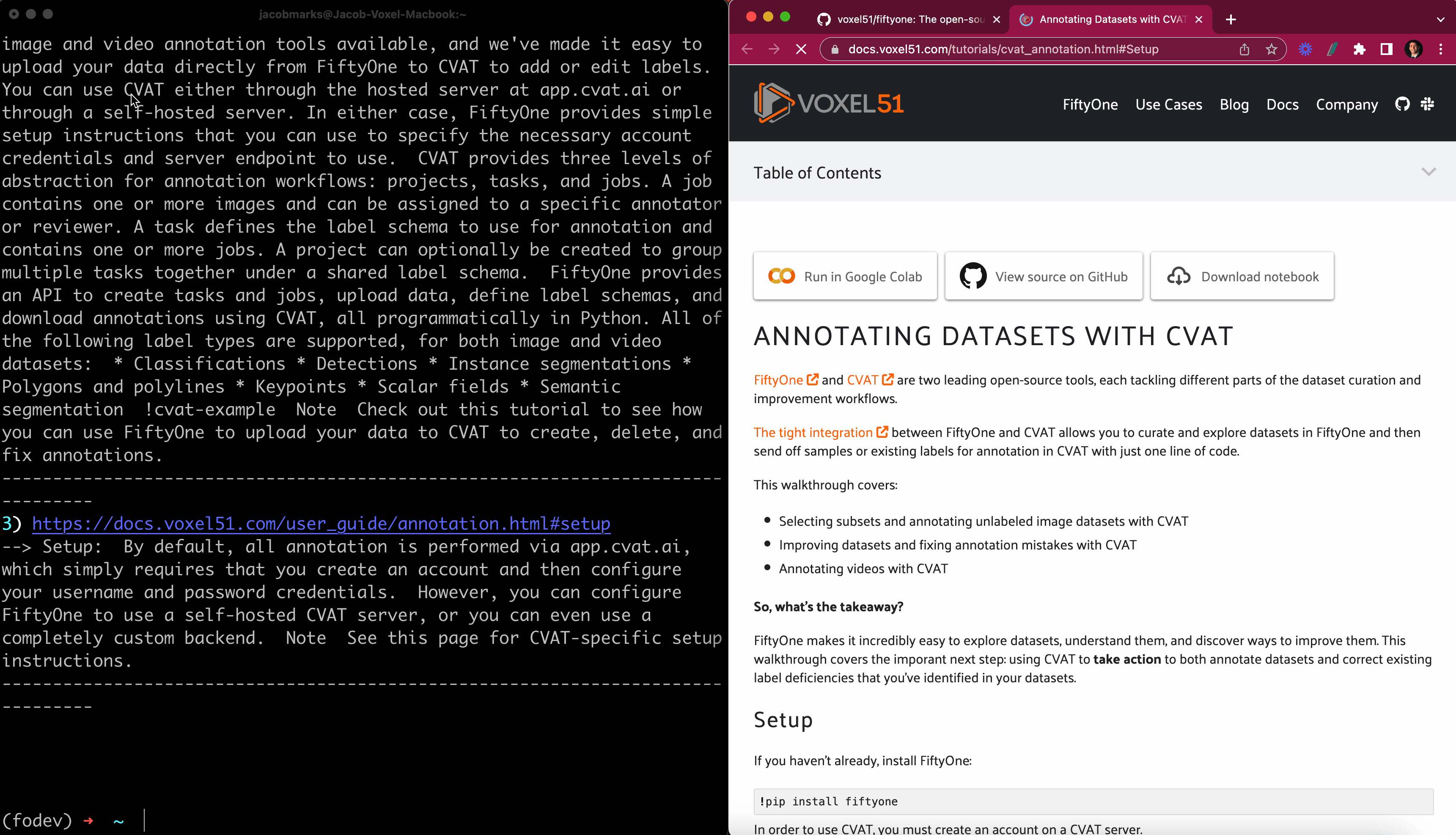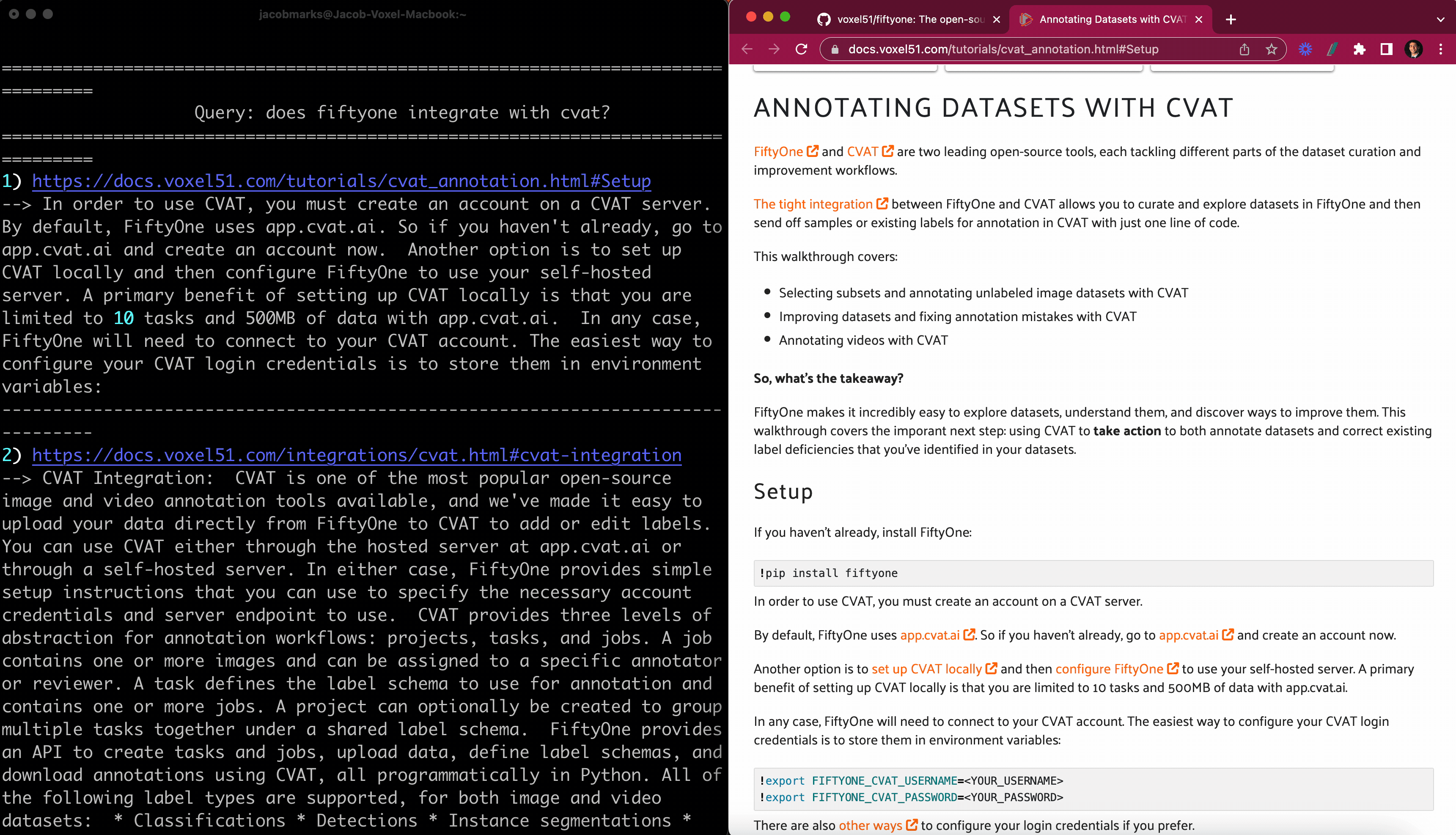
Así es como convertí nuestros documentos en una base de datos vectorial con capacidad de búsqueda semántica:
- Convirtió todos los documentos a un formato unificado
- Dividí los documentos en bloques y agregué una limpieza automática
- Incrustaciones calculadas para cada bloque
- Se generó un índice vectorial a partir de estas incrustaciones.
- Se definió la consulta de índice
- Lo envolví todo en una interfaz de línea de comandos fácil de usar y una API de Python.
Puede encontrar todo el código para esta publicación en el repositorio voxel51/fiftyone-docs-search , y es fácil instalar el paquete localmente en modo de edición con pip install -e ..
Mejor aún, si quieres implementar la búsqueda semántica en tu propio sitio web con este método, ¡puedes seguir los pasos! Estos son los ingredientes que necesitarás:
- Instale el paquete Python openai y cree una cuenta: utilizará esta cuenta para enviar sus documentos y consultas a un punto final de inferencia, que devolverá un vector de incrustación para cada fragmento de texto.
- Instale el paquete de Python qdrant-client y ejecute un servidor Qdrant a través de Docker : utilizará Qdrant para crear un índice vectorial alojado localmente para los documentos, en el que se ejecutarán las consultas. El servicio Qdrant se ejecutará dentro de un contenedor Docker.
Convertir los documentos a un formato unificado
Todos los documentos de mi empresa están alojados como documentos HTML en https://docs.voxel51.com . Un punto de partida natural hubiera sido descargar estos documentos con la biblioteca de solicitudes de Python y analizar el documento con Beautiful Soup .
Sin embargo, como desarrollador (y autor de muchos de nuestros documentos), pensé que podía hacerlo mejor. Ya tenía un clon funcional del repositorio de GitHub en mi computadora local que contenía todos los archivos sin procesar utilizados para generar los documentos HTML. Algunos de nuestros documentos están escritos en Sphinx ReStructured Text (RST) , mientras que otros, como los tutoriales, se convierten a HTML desde cuadernos Jupyter.
Pensé (erróneamente) que cuanto más me acercara al texto sin procesar de los archivos RST y Jupyter, más simples serían las cosas.
Primera vez
En los documentos RST, las secciones se delimitan mediante líneas que constan únicamente de cadenas de caracteres =, -o _. Por ejemplo, aquí hay un documento de la Guía del usuario de FiftyOne que contiene los tres delimitadores:
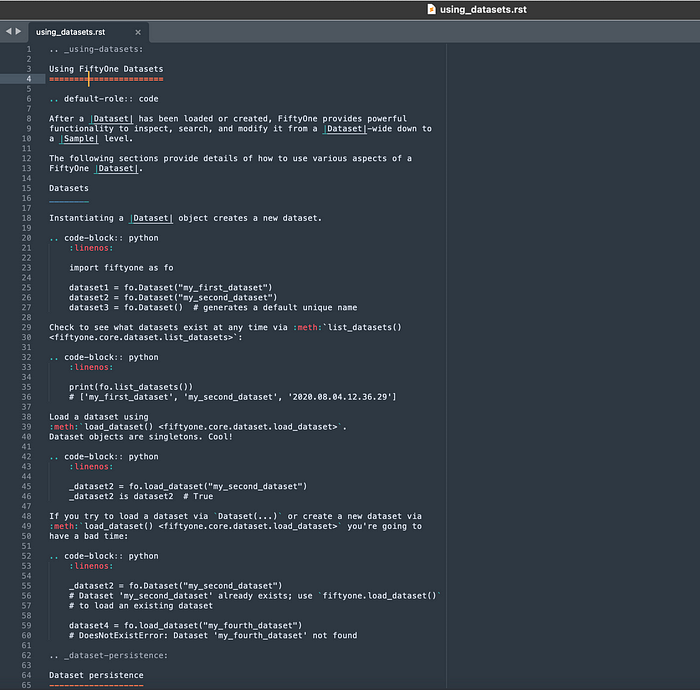
Luego pude eliminar todas las palabras clave RST, como toctree, code-block, y button_link(había muchas más), así como :, ::, y ..que acompañaban a una palabra clave, el inicio de un nuevo bloque o descriptores de bloque.
Los enlaces también fueron fáciles de cuidar:
sin_enlaces_sección = re.sub( r"<[^>]+>_?" , "" , sección)
Las cosas empezaron a complicarse cuando quise extraer los anclajes de sección de los archivos RST. Muchas de nuestras secciones tenían anclajes especificados explícitamente, mientras que otros se dejaron para que se infirieran durante la conversión a HTML.
He aquí un ejemplo:
.. _brain-embeddings-visualization:
Visualización de incrustaciones
______________________
FiftyOne Brain ofrece un potente
método :meth:`compute_visualization() <fiftyone.brain.compute_visualization>`
que puede utilizar para generar representaciones de baja dimensión de las muestras
o de los objetos individuales en sus conjuntos de datos.
Estas representaciones se pueden visualizar de forma nativa en el
:ref:`Panel de incrustaciones <app-embeddings-panel>` de la aplicación, donde puede
seleccionar puntos de interés de forma interactiva y ver las muestras o etiquetas de interés correspondientes
en el :ref:`Panel de muestras <app-samples-panel>`, y viceversa.
.. image:: /images/brain/brain-mnist.png
:alt: mnist
:align: center
Hay dos componentes principales para una visualización de incrustaciones: el método utilizado
para generar las incrustaciones y el método de reducción de dimensionalidad utilizado para
calcular una representación de baja dimensión de las incrustaciones.
Métodos de incrustación
-----------------
Los parámetros `embeddings` y `model` de
:meth:`compute_visualization() <fiftyone.brain.compute_visualization>`
admiten una variedad de formas de generar incrustaciones para sus datos:
En el archivo brain.rst de nuestros documentos de la Guía del usuario (del que se reproduce una parte arriba), la sección Visualización de incrustaciones tiene un ancla #brain-embeddings-visualizationespecificado por .. _brain-embeddings-visualization:. Sin embargo, la subsección Métodos de incrustación que sigue inmediatamente después tiene un ancla generado automáticamente.
Otra dificultad que pronto apareció fue cómo manejar las tablas en RST. Las tablas de lista eran bastante sencillas. Por ejemplo, aquí hay una tabla de lista de nuestra hoja de referencia de View Stages:
.. lista-tabla::
* - :meth:`match() <cincuenta.colecciones.core.SampleCollection.match>`
* - :meth:`match_frames() <cincuenta.colecciones.core.SampleCollection.match_frames>`
* - :meth:`match_labels() <cincuenta.colecciones.core.SampleCollection.match_labels>`
* - :meth:`match_tags() <cincuenta.colecciones.core.SampleCollection.match_tags>`
Por otro lado, las tablas de cuadrícula pueden volverse desordenadas rápidamente. Brindan a los escritores de documentos una gran flexibilidad, pero esta misma flexibilidad hace que analizarlas sea una molestia. Tome esta tabla de nuestra hoja de referencia de filtrado:
+-----------------------------------------+-----------------------------------------------------------------------+
| Operación | Comando |
+==============================================+=====================================================================================+
| La ruta del archivo comienza con "/Users" | .. code-block:: |
| |
| | ds.match(F("filepath").starts_with("/Users")) |
+-----------------------------------------+-----------------------------------------------------------------------+
| La ruta del archivo termina con "10.jpg" o "10.png" | .. code-block:: |
| | |
| | ds.match(F("filepath").ends_with(("10.jpg", "10.png")) |
+------------------------------------------+-----------------------------------------------------------------------+
| La etiqueta contiene la cadena "be" | .. code-block:: |
| | |
| | ds.filter_labels( |
| | "predicciones", |
| | F("label").contains_str("be"), | |
| ) |
+------------------------------------------+-----------------------------------------------------------------------+
| La ruta del archivo contiene "088" y es JPEG | .. code-block:: |
| | |
| | ds.match(F("filepath").re_match("088*.jpg")) |
+------------------------------------------+-----------------------------------------------------------------------+
Dentro de una tabla, las filas pueden ocupar una cantidad arbitraria de líneas y las columnas pueden variar en ancho. Los bloques de código dentro de las celdas de una tabla de cuadrícula también son difíciles de analizar, ya que ocupan espacio en varias líneas, por lo que su contenido se intercala con el contenido de otras columnas. Esto significa que los bloques de código en estas tablas deben reconstruirse de manera efectiva durante el proceso de análisis.
No es el fin del mundo, pero tampoco es lo ideal.
Jupyter
Los cuadernos Jupyter resultaron ser relativamente sencillos de analizar. Pude leer el contenido de un cuaderno Jupyter en una lista de cadenas, con una cadena por celda:
importar json
ifile = "my_notebook.ipynb"
con open (ifile, "r" ) como f:
contenido = f.read()
contenido = json.loads(contenido)[ "celdas" ]
contenido = [( " " .join(c[ "fuente" ]), c[ 'cell_type' ] para c en contenido]
Además, las secciones fueron delimitadas por celdas Markdown que comenzaban con #.
Sin embargo, dados los desafíos que plantea RST, decidí recurrir a HTML y tratar todos nuestros documentos por igual.
HTML
Creé los documentos HTML desde mi instalación local con bash generate_docs.bashy comencé a analizarlos con Beautiful Soup. Sin embargo, pronto me di cuenta de que cuando los bloques de código RST y las tablas con código en línea se convertían a HTML, aunque se procesaban correctamente, el HTML en sí era increíblemente difícil de manejar. Tomemos como ejemplo nuestra hoja de trucos de filtrado.
Cuando se muestra en un navegador, el bloque de código que precede a la sección Fechas y horas de nuestra hoja de trucos de filtrado se ve así:

Sin embargo, el HTML sin procesar se ve así:
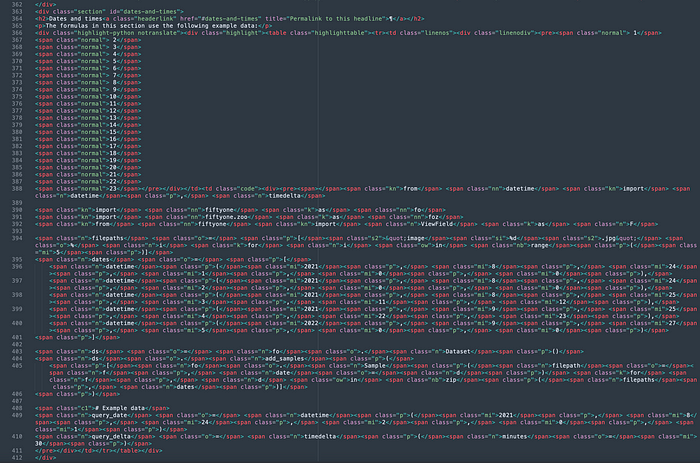
Esto no es imposible de analizar, pero tampoco es lo ideal.
Reducción
Afortunadamente, pude superar estos problemas convirtiendo todos los archivos HTML a Markdown con Markdownify . Markdown tenía algunas ventajas clave que lo convertían en la opción ideal para este trabajo.
- Más limpio que HTML : el formato del código se simplificó, pasando de las cadenas de
spanelementos en forma de espagueti a fragmentos de código en línea marcados con un solo`antes y después, y los bloques de código se marcaron con comillas triples```antes y después. Esto también facilitó la división en texto y código. - Aún contenía anclas: a diferencia del RST original, este Markdown incluía anclas de encabezado de sección, ya que las anclas implícitas ya se habían generado. De esta manera, podía vincularme no solo a la página que contenía el resultado, sino a la sección o subsección específica de esa página.
- Estandarización : Markdown proporcionó un formato mayoritariamente uniforme para los documentos RST y Jupyter iniciales, lo que nos permitió darle a su contenido un tratamiento consistente en la aplicación de búsqueda vectorial.
Nota sobre LangChain
Algunos de ustedes pueden conocer la biblioteca de código abierto LangChain para crear aplicaciones con LLM y se preguntarán por qué no utilicé los cargadores de documentos y divisores de texto de LangChain . La respuesta: ¡necesitaba más control!
Tramitación de los documentos
Una vez convertidos los documentos a Markdown, procedí a limpiar el contenido y dividirlos en segmentos más pequeños.
Limpieza
La limpieza consiste principalmente en eliminar elementos innecesarios, entre ellos:
- Encabezados y pies de página
- Andamiaje de filas y columnas de tablas, por ejemplo, el
|‘s en|select()| select_by()| - Nuevas líneas adicionales
- Campo de golf
- Imágenes
- Caracteres Unicode
- Negrita — es decir
**text**→text
También eliminé los caracteres de escape que se escapaban de caracteres que tienen un significado especial en nuestros documentos: _y *. El primero se utiliza en muchos nombres de métodos y el segundo, como es habitual, se utiliza en la multiplicación, patrones de expresiones regulares y muchos otros lugares:
documento = documento.replace( "\_" , "_" ).replace( "\*" , "*" )
División de documentos en bloques semánticos
Con el contenido de nuestros documentos limpio, procedí a dividirlos en bloques pequeños.
Primero, divido cada documento en secciones. A primera vista, parece que esto se puede hacer buscando cualquier línea que comience con un #carácter. En mi aplicación, no diferencié entre h1, h2, h3, etc. ( #, ##, ###), por lo que verificar el primer carácter es suficiente. Sin embargo, esta lógica nos mete en problemas cuando nos damos cuenta de que #también se emplea para permitir comentarios en el código Python.
Para evitar este problema, dividí el documento en bloques de texto y bloques de código:
texto_y_código = pagina_md.split( '```' )
texto = texto_y_código[:: 2 ]
código = texto_y_código[ 1 :: 2 ]
Luego identifiqué el inicio de una nueva sección con un #para iniciar una línea en un bloque de texto. Extraje el título y el ancla de la sección de esta línea:
def extract_title_and_anchor ( header ):
header = " " .join(header.split( " " )[ 1 :])
title = header.split( "[" )[ 0 ]
anchor = header.split( "(" )[ 1 ].split( " " )[ 0 ]
return title, anchor
Y asignó cada bloque de texto o código a la sección correspondiente.
Inicialmente, también intenté dividir los bloques de texto en párrafos, con la hipótesis de que, dado que una sección puede contener información sobre muchos temas diferentes, la inserción de toda esa sección puede no ser similar a la inserción de un mensaje de texto relacionado solo con uno de esos temas. Sin embargo, este enfoque dio como resultado que las principales coincidencias para la mayoría de las consultas de búsqueda fueran, de manera desproporcionada, párrafos de una sola línea, que no resultaron ser demasiado informativos como resultados de búsqueda.
¡Consulta el repositorio de GitHub adjunto para ver la implementación de estos métodos que puedes probar en tus propios documentos!
Incorporación de bloques de texto y código con OpenAI
Una vez convertidos, procesados y divididos los documentos en cadenas, generé un vector de incrustación para cada uno de estos bloques. Como los modelos de lenguaje grandes son flexibles y, por lo general, capaces por naturaleza, decidí tratar tanto los bloques de texto como los bloques de código como si fueran fragmentos de texto e incrustarlos con el mismo modelo.
Utilicé el modelo text-embedding-ada-002 de OpenAI porque es fácil de usar, logra el mayor rendimiento de todos los modelos de incrustación de OpenAI (en el benchmark BEIR ) y también es el más económico. De hecho, es tan económico (0,0004 dólares/1000 tokens) que generar todas las incrustaciones para los documentos de FiftyOne solo cuesta unos pocos centavos. Como lo expresa el propio OpenAI: «Recomendamos usar text-embedding-ada-002 para casi todos los casos de uso. Es mejor, más económico y más sencillo de usar».
Con este modelo de inserción, puede generar un vector de 1536 dimensiones que represente cualquier solicitud de entrada, hasta 8191 tokens (aproximadamente 30 000 caracteres).
Para comenzar, debe crear una cuenta OpenAI, generar una clave API en https://platform.openai.com/account/api-keys y exportar esta clave API como una variable de entorno con:
exportar OPENAI_API_KEY= "<MY_API_KEY>"
También necesitarás instalar la biblioteca Python openai :
pip instala openai
Escribí un contenedor alrededor de la API de OpenAI que recibe un mensaje de texto y devuelve un vector de incrustación:
MODELO = "text-embedding-ada-002"
def embed_text ( texto ):
respuesta = openai.Embedding.create(
entrada =texto,
modelo=MODEL
)
incrustaciones = respuesta[ 'datos' ][ 0 ][ 'incrustación' ]
devolver incrustaciones
Para generar incrustaciones para todos nuestros documentos, simplemente aplicamos esta función a cada una de las subsecciones (bloques de texto y código) en todos nuestros documentos.
Creación de un índice vectorial Qdrant
Con las incrustaciones en la mano, creé un índice vectorial para realizar búsquedas. Elegí utilizar Qdrant por las mismas razones por las que elegimos agregar compatibilidad nativa con Qdrant a FiftyOne: es de código abierto, gratuito y fácil de usar.
Para comenzar a utilizar Qdrant, puede extraer una imagen de Docker precompilada y ejecutar el contenedor:
docker pull qdrant/qdrant
docker ejecutar -d -p 6333:6333 qdrant/qdrant
Además, necesitarás instalar el cliente Python de Qdrant:
pip instala qdrant-client
He creado la colección Qdrant:
importar qdrant_client como qc
importar qdrant_client.http.models como qmodels
cliente = qc.QdrantClient(url= "localhost" )
MÉTRICA = qmodels.Distancia.PUNTO
DIMENSIÓN = 1536
NOMBRE_DE_COLECCIÓN = "cincuenta_docs"
def crear_índice ():
cliente.recrear_colección(
nombre_de_colección=NOMBRE_DE_COLECCIÓN,
config_vectores = qmodels.VectorParams(
tamaño=DIMENSIÓN,
distancia=MÉTRICA,
)
)
Luego creé un vector para cada subsección (bloque de texto o código):
importar uuid
def create_subsection_vector (
contenido_subsección,
ancla_sección,
url_página,
tipo_doc
):
vector = embed_text(contenido_subsección)
id = str (uuid.uuid1(). int )[: 32 ]
payload = {
"texto" : contenido_subsección,
"url" : url_página,
"ancla_sección" : ancla_sección,
"tipo_doc" : tipo_doc,
"tipo_bloque" : tipo_bloque
}
return id , vector, payload
Para cada vector, puedes proporcionar un contexto adicional como parte de la carga útil . En este caso, incluí la URL (y el ancla) donde se puede encontrar el resultado, el tipo de documento, para que el usuario pueda especificar si desea buscar en todos los documentos o solo en ciertos tipos de documentos, y el contenido de la cadena que generó el vector de incrustación. También agregué el tipo de bloque (texto o código), de modo que si el usuario está buscando un fragmento de código, pueda adaptar su búsqueda a ese propósito.
Luego agregué estos vectores al índice, una página a la vez:
def add_doc_to_index (subsecciones, url_página, tipo_doc, tipo_bloque):
ids = []
vectores = []
cargas útiles = []
para ancla_sección, contenido_sección en subsecciones.items ( ):
para subsección en contenido_sección:
id, vector, carga útil = create_subsection_vector (
subsección,
ancla_sección,
url_página,
tipo_doc,
tipo_bloque
)
ids.append (id) vectores.append (vector) cargas útiles.append (carga útil) ## Agregar vectores a la colección client.upsert ( colección_nombre = NOMBRE_COLECCIÓN , points=qmodels.batch ( ids = ids, vectores=vectores, cargas útiles=cargas útiles ) , )
Consulta del índice
Una vez creado el índice, se puede ejecutar una búsqueda en los documentos indexados incorporando el texto de consulta con el mismo modelo de incorporación y luego buscando vectores de incorporación similares en el índice. Con un índice vectorial de Qdrant, se puede realizar una consulta básica con el search()comando del cliente de Qdrant.
Para que los documentos de mi empresa se puedan buscar, quería permitir que los usuarios filtraran por sección de los documentos, así como por el tipo de bloque que estaba codificado. En el lenguaje de la búsqueda vectorial, filtrar los resultados y al mismo tiempo garantizar que top_kse devolverá una cantidad predeterminada de resultados (especificada por el argumento) se denomina prefiltrado .
Para lograr esto, escribí un filtro programático:
def _generate_query_filter ( consulta, doc_types, block_types ):
"""Genera un filtro para la consulta.
Args:
consulta: Una cadena que contiene la consulta.
doc_types: Una lista de tipos de documentos para buscar.
block_types: Una lista de tipos de bloques para buscar.
Devuelve:
Un filtro para la consulta.
"""
doc_types = _parse_doc_types(doc_types)
block_types = _parse_block_types(block_types)
_ filter = models.Filter(
must=[
models.Filter(
should= [
models.FieldCondition(
key= "doc_type" ,
match =models.MatchValue(value=dt),
)
for dt in doc_types
],
),
models.Filter(
should= [
models.FieldCondition(
key= "block_type" ,
match =models.MatchValue(value=bt),
)
for bt en block_types
]
)
]
)
devolver _ filtro
Las funciones internas _parse_doc_types()y _parse_block_types()manejan casos donde el argumento es una cadena o un valor de lista, o es Ninguno.
Luego escribí una función query_index()que toma la consulta de texto del usuario, realiza un prefiltrado, busca en el índice y extrae información relevante de la carga útil. La función devuelve una lista de tuplas con el formato (url, contents, score), donde la puntuación indica qué tan bien coincide el resultado con el texto de la consulta.
def índice_consulta ( consulta, top_k= 10 , tipos_doc= Ninguno , tipos_bloque= Ninguno ):
vector = embed_text(consulta)
_ filtro = _generate_query_filter(consulta, tipos_doc, tipos_bloque)
resultados = CLIENTE.búsqueda(
nombre_colección=NOMBRE_COLECCIÓN,
vector_consulta=vector,
filtro_consulta= _filtro ,
límite=top_k,
con_carga_útil= True ,
parámetros_búsqueda=_parámetros_búsqueda,
)
resultados = [
(
f" {res.carga_útil[ 'url' ]} # {res.carga_útil[ 'ancla_sección' ]} " ,
res.carga_útil[ "texto" ],
res.puntuación,
)
para res en resultados
]
devolver resultados
Escritura del contenedor de búsqueda
El paso final fue proporcionar una interfaz limpia para que el usuario pudiera buscar semánticamente en estos documentos “vectorizados”.
Escribí una función print_results()que toma la consulta, los resultados de query_index()y un scoreargumento (si se debe imprimir o no el puntaje de similitud), e imprime los resultados de una manera fácil de interpretar. Usé el paquete Python enriquecido para formatear hipervínculos en la terminal de modo que cuando trabaje en una terminal que admita hipervínculos, al hacer clic en el hipervínculo se abra la página en su navegador predeterminado. También usé el navegador web para abrir automáticamente el enlace para el resultado superior, si así lo desea.
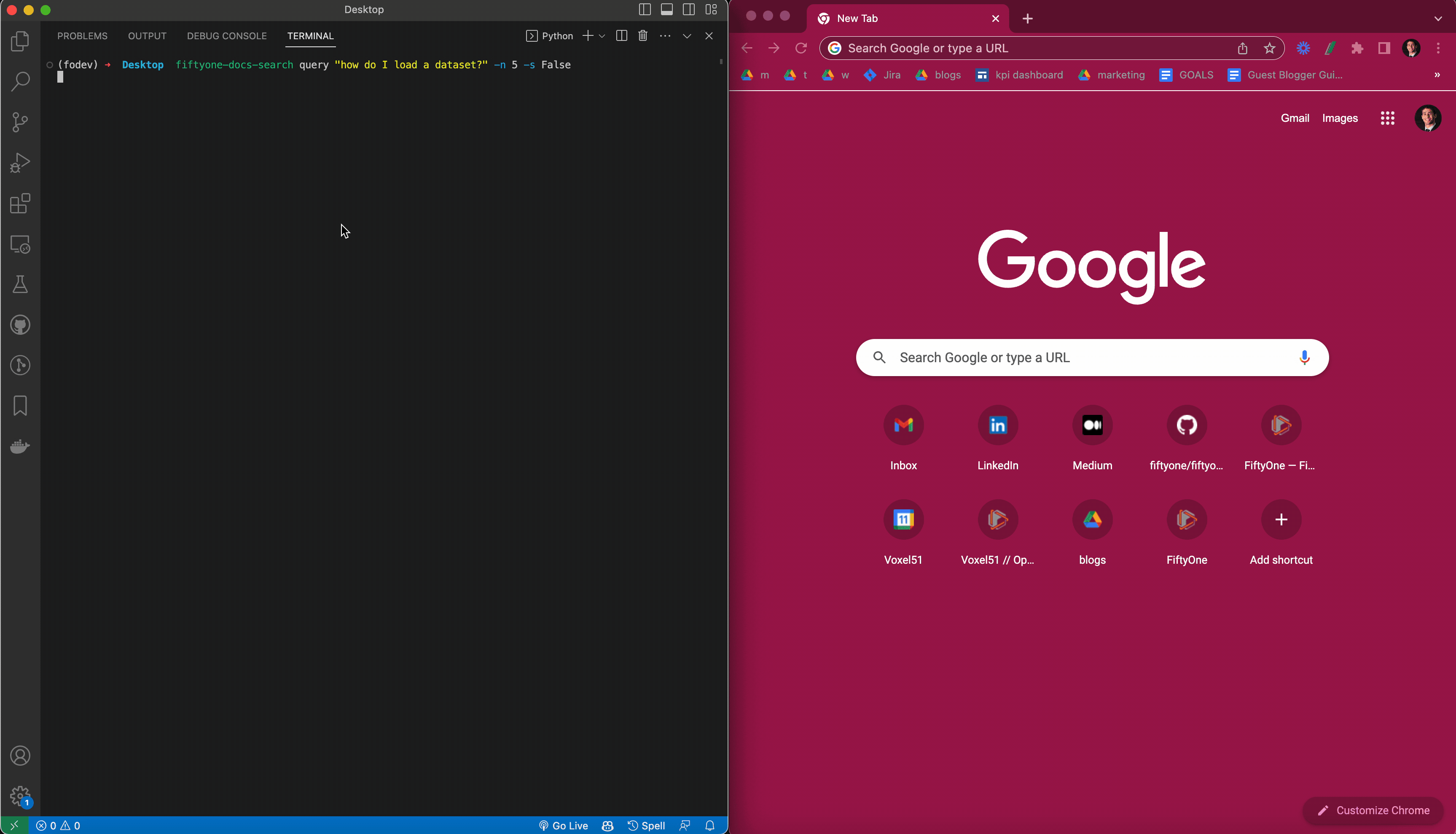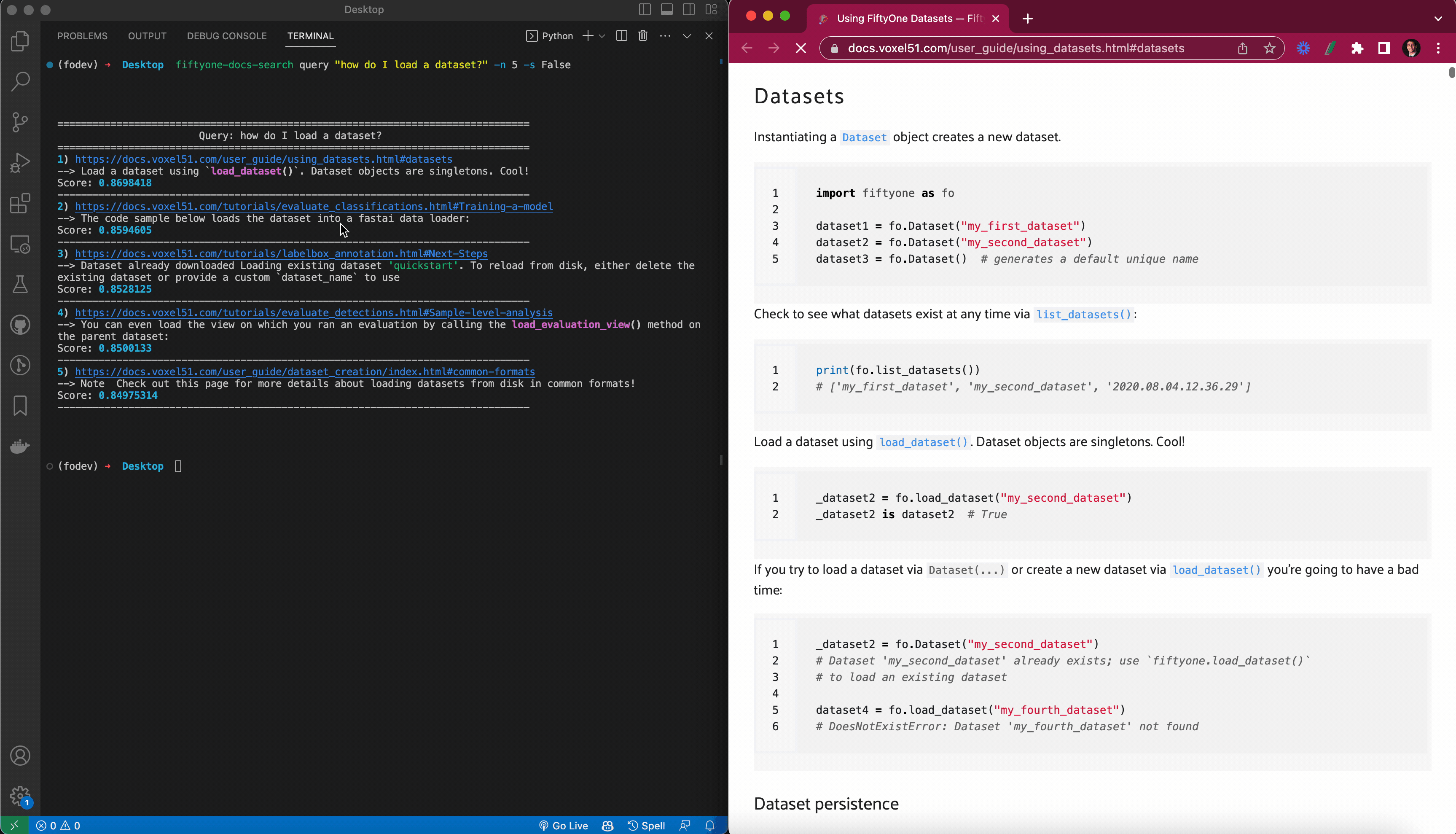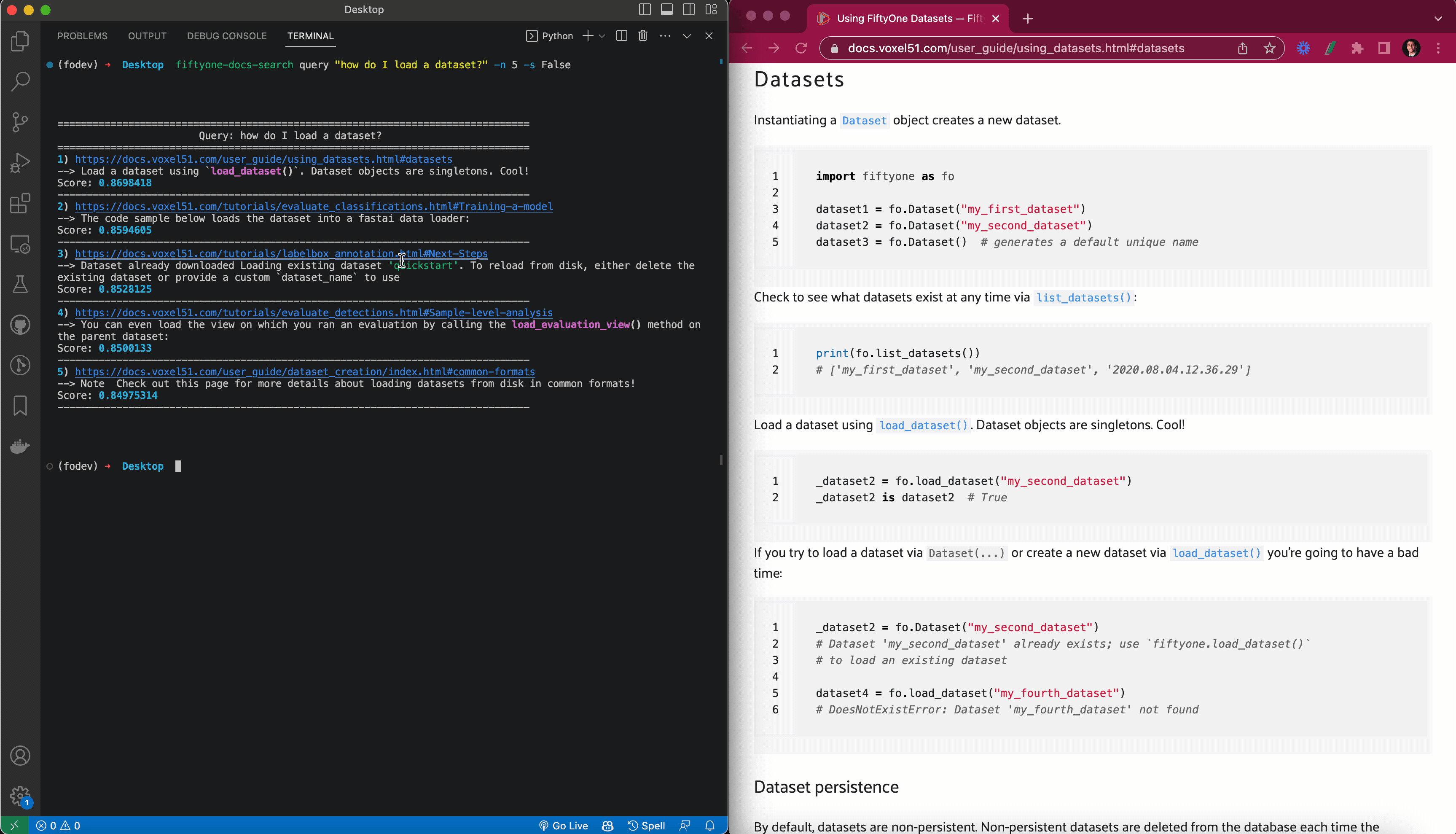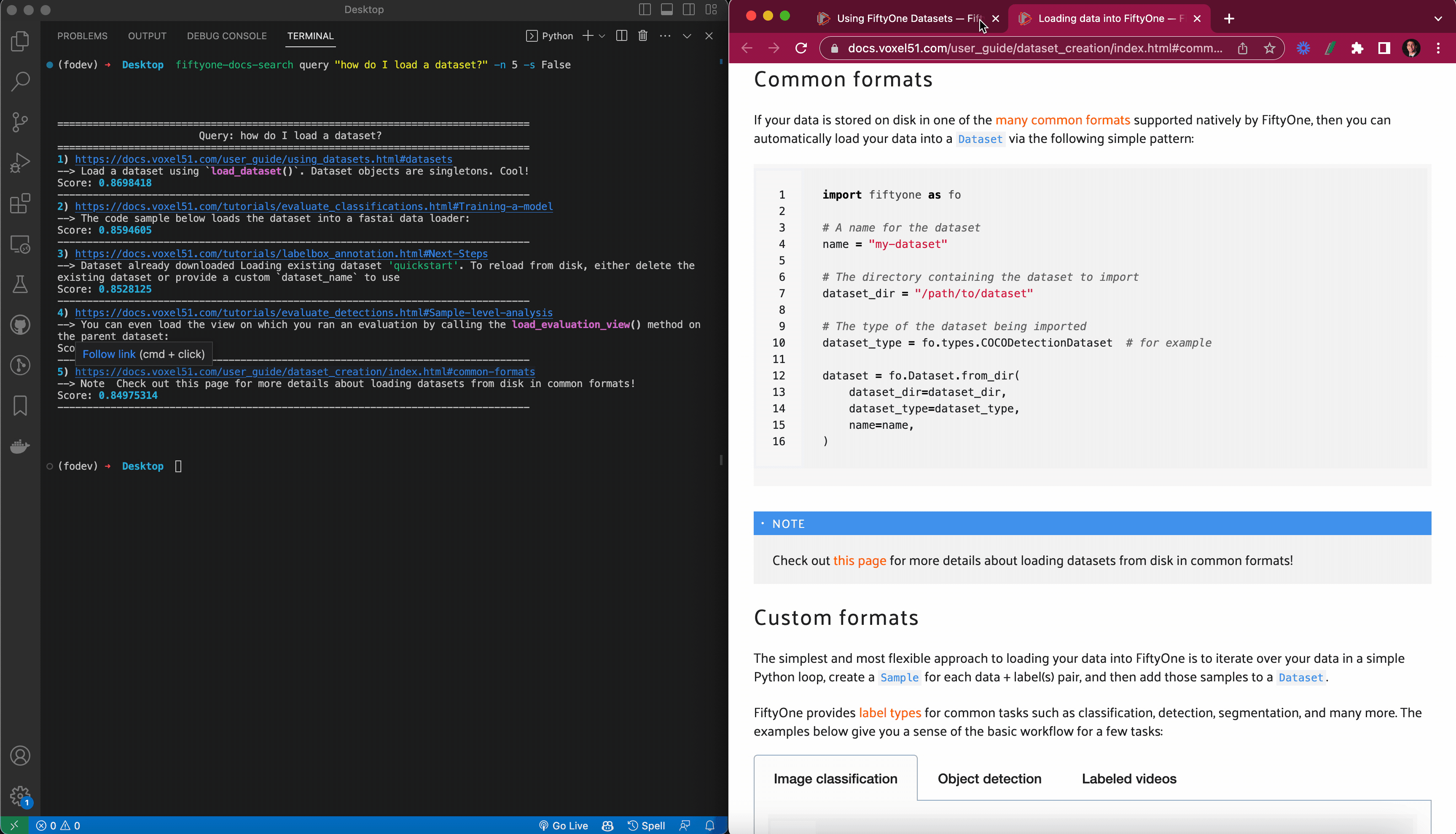
Para las búsquedas basadas en Python, creé una clase FiftyOneDocsSearchpara encapsular el comportamiento de búsqueda de documentos, de modo que una vez que FiftyOneDocsSearchse haya creado una instancia de un objeto (posiblemente con configuraciones predeterminadas para los argumentos de búsqueda):
de fiftyone.docs_search importar FiftyOneDocsSearch
fosearch = FiftyOneDocsSearch(open_url= False , top_k= 3 , score= True )
Puedes realizar búsquedas dentro de Python llamando a este objeto. Para consultar la documentación sobre “Cómo cargar un conjunto de datos”, por ejemplo, solo tienes que ejecutar:
fosearch(“Cómo cargar un conjunto de datos”)
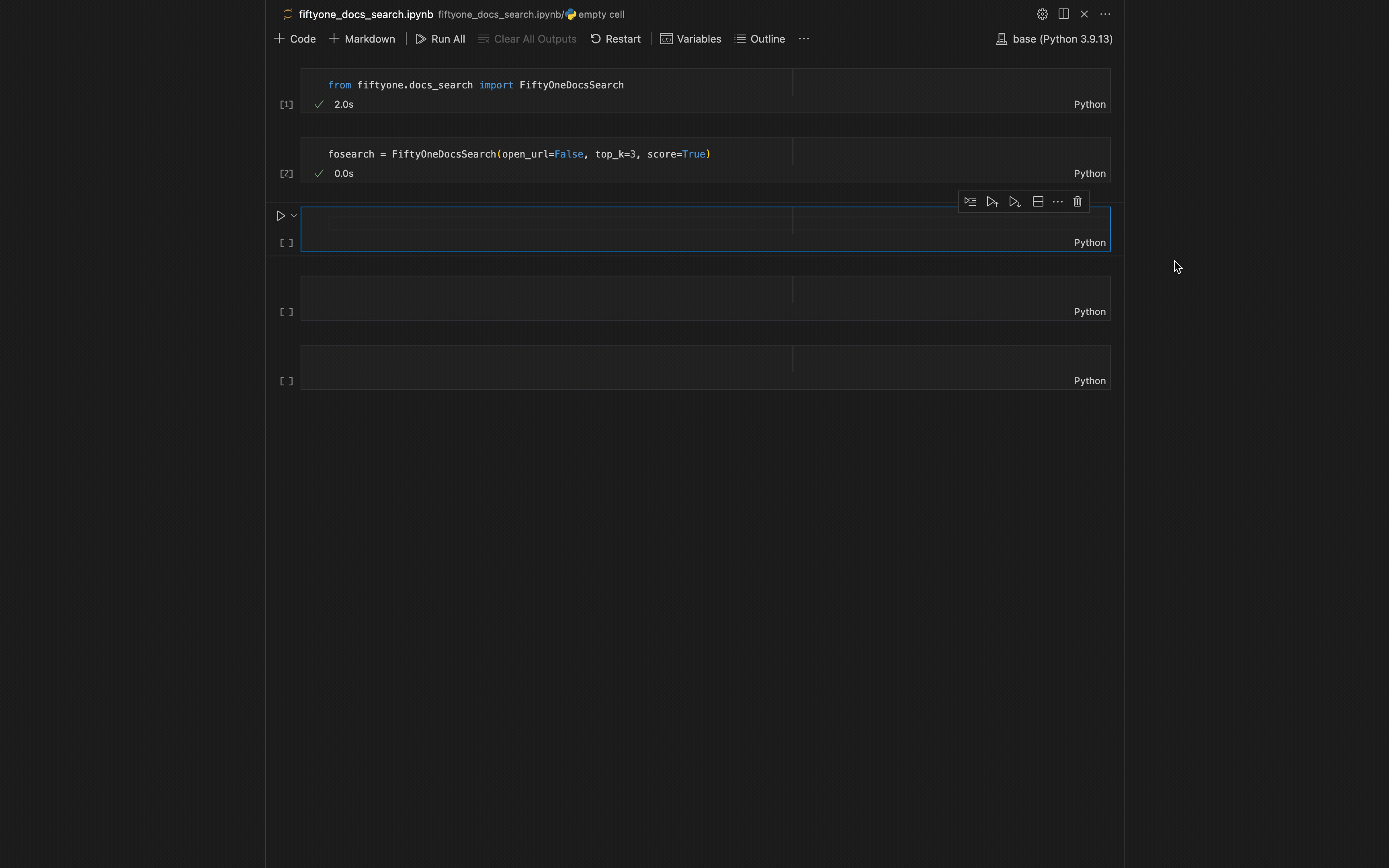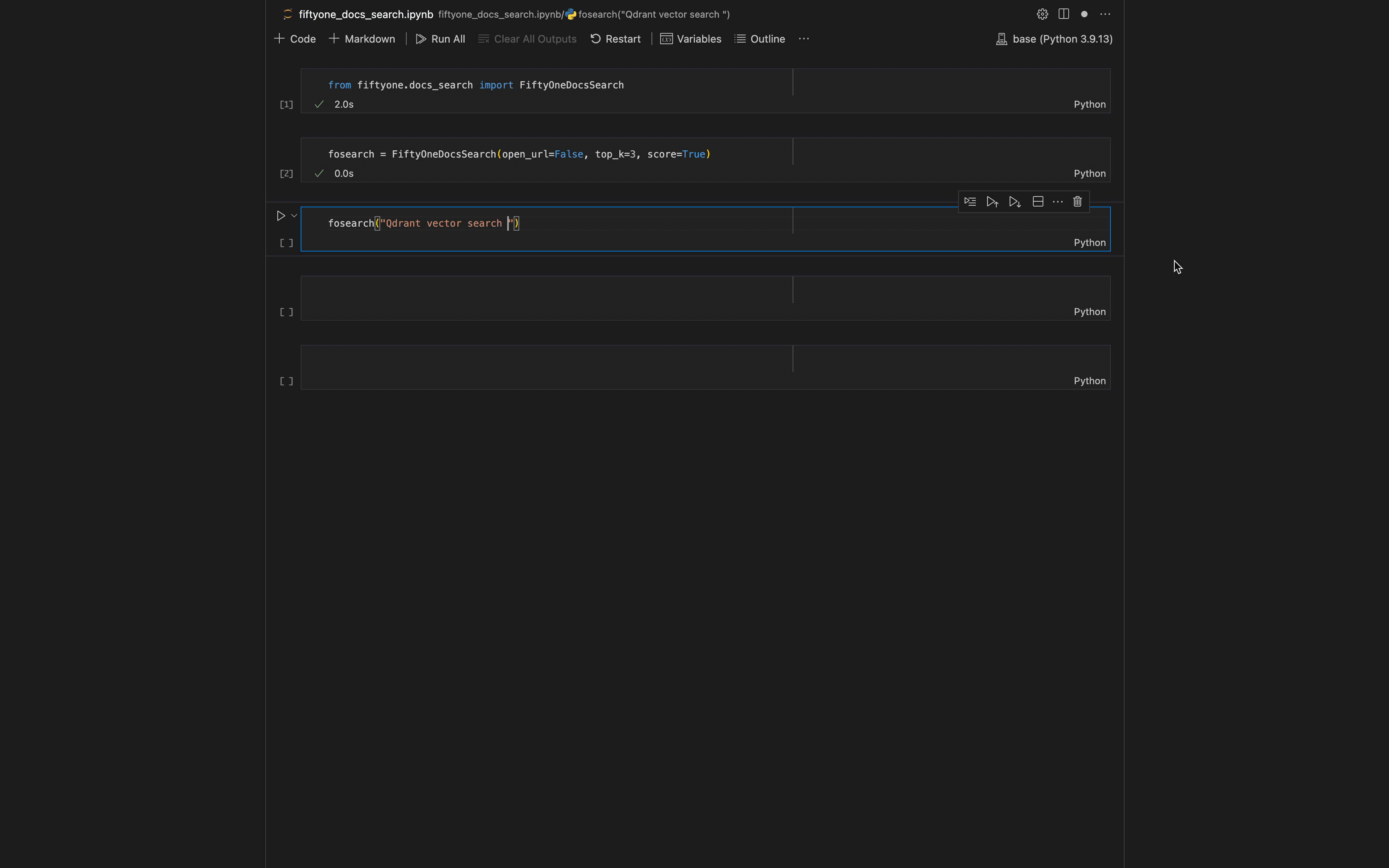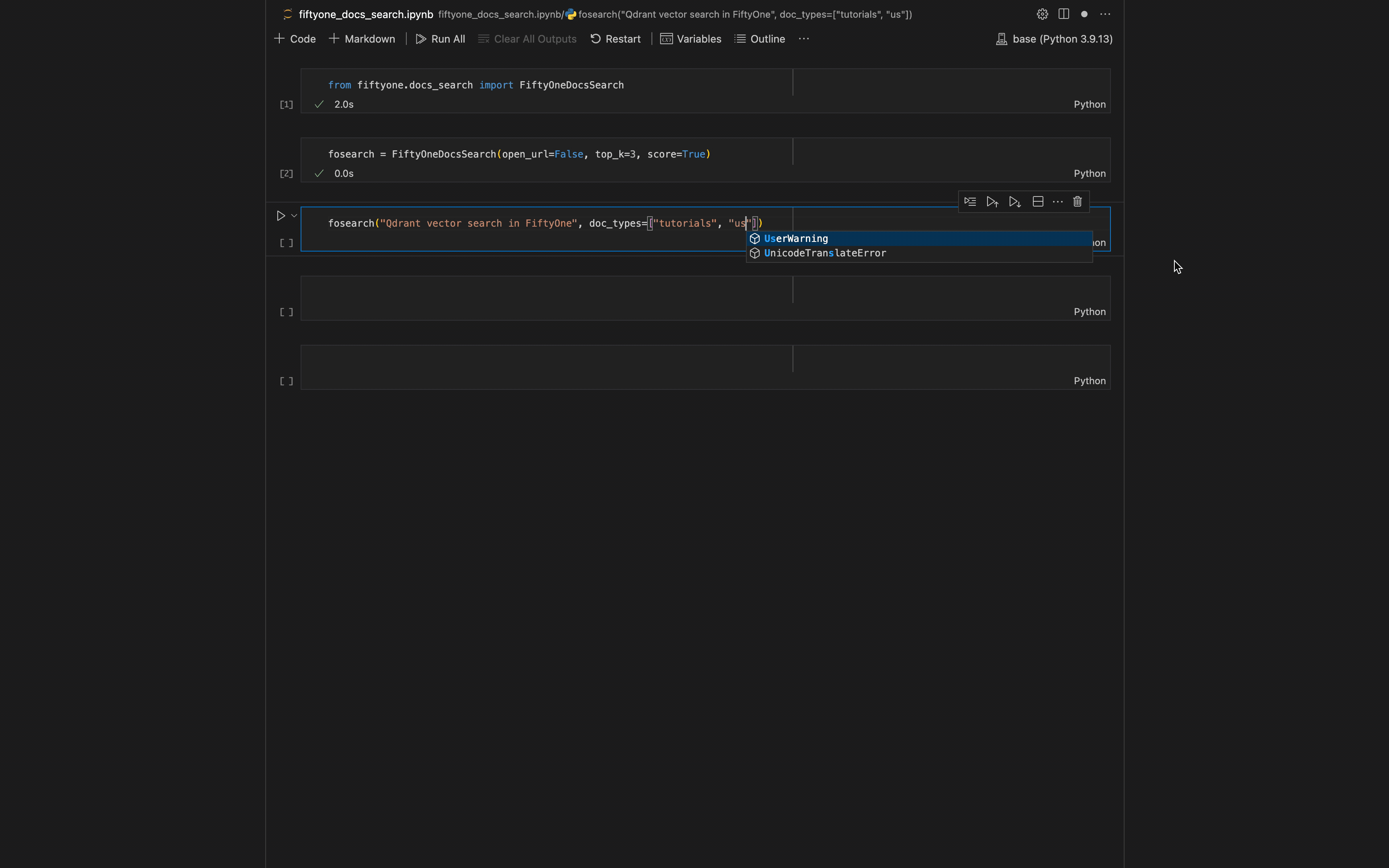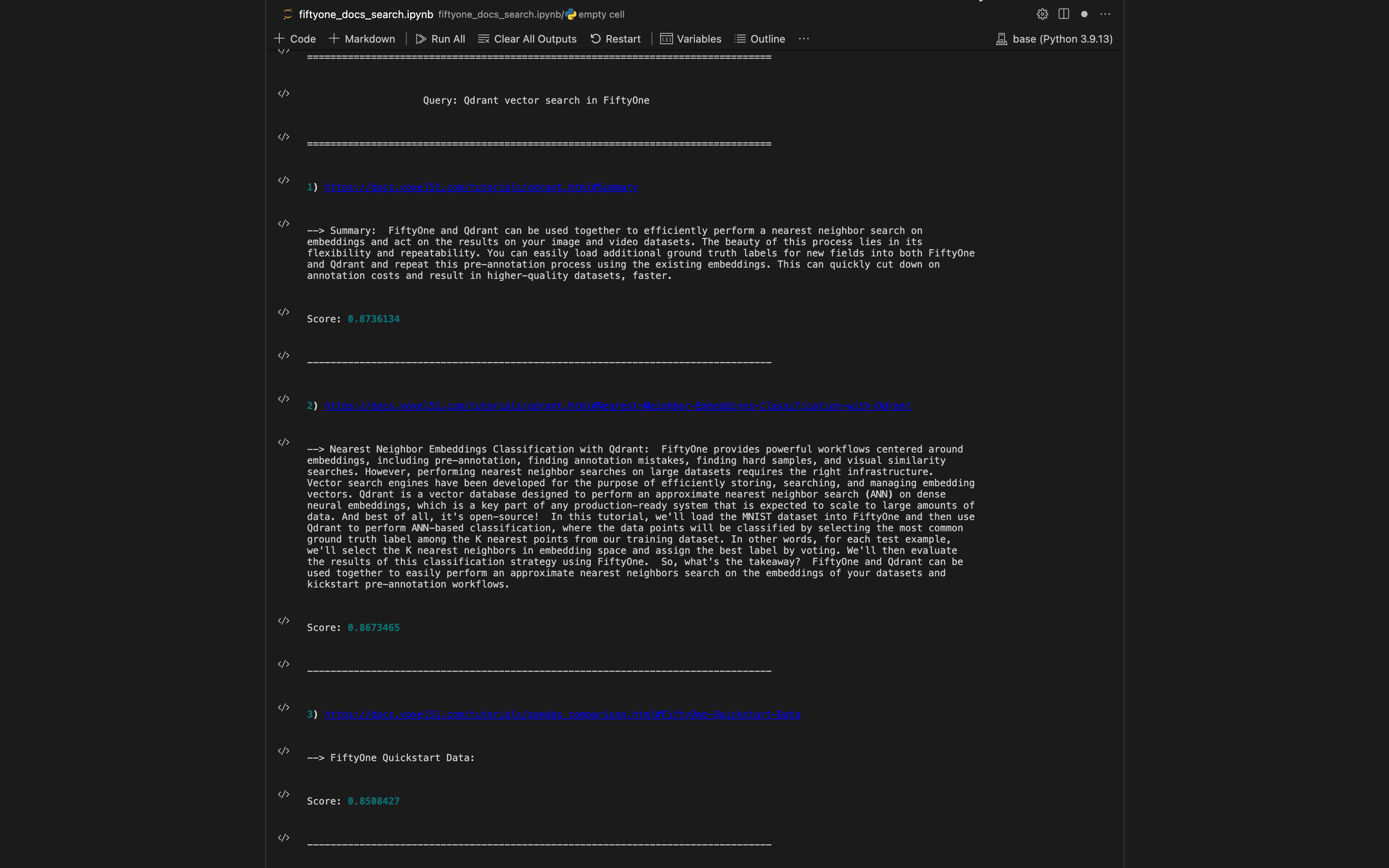
También utilicé argparse para que esta función de búsqueda de documentos esté disponible a través de la línea de comandos. Cuando se instala el paquete, los documentos se pueden buscar mediante CLI con:
consulta de búsqueda de fiftyone-docs "<mi-consulta>" <args
Sólo por diversión, porque fiftyone-docs-search queryes un poco engorroso, agregué un alias a mi .zsrcharchivo:
alias fosearch= 'consulta de búsqueda de cincuenta y un documentos'
Con este alias, los documentos se pueden buscar desde la línea de comandos con:
argumentos de fosearch "<mi-consulta>"
Conclusión
Al comenzar, ya me había convertido en un usuario avanzado de la biblioteca de código abierto de Python de mi empresa, FiftyOne. Había escrito muchos de los documentos y había utilizado (y sigo utilizando) la biblioteca a diario. Pero el proceso de convertir nuestros documentos en una base de datos con capacidad de búsqueda me obligó a comprenderlos a un nivel aún más profundo. ¡Siempre es genial cuando estás creando algo para otros y, además, termina ayudándote a ti!
Esto es lo que aprendí:
- Sphinx RST es complicado : crea documentos hermosos, pero es un poco complicado analizarlos.
- No se vuelva loco con el preprocesamiento: el modelo text-embeddings-ada-002 de OpenAI es excelente para comprender el significado detrás de una cadena de texto, incluso si tiene un formato ligeramente atípico. Atrás quedaron los días de la derivación y la eliminación minuciosa de palabras vacías y caracteres diversos.
- Lo mejor es utilizar fragmentos pequeños y semánticamente significativos : divida sus documentos en los segmentos significativos más pequeños posibles y conserve el contexto. En el caso de fragmentos de texto más largos, es más probable que la superposición entre una consulta de búsqueda y una parte del texto en su índice quede oculta por texto menos relevante en el segmento. Si divide el documento en fragmentos demasiado pequeños, corre el riesgo de que muchas entradas en el índice contengan muy poca información semántica.
- La búsqueda vectorial es potente : con un esfuerzo mínimo y sin realizar ajustes, pude mejorar drásticamente la capacidad de búsqueda de nuestros documentos. Según las estimaciones iniciales, parece que esta búsqueda de documentos mejorada tiene más del doble de probabilidades de devolver resultados relevantes que el antiguo enfoque de búsqueda por palabras clave. Además, la naturaleza semántica de este enfoque de búsqueda vectorial significa que los usuarios ahora pueden buscar con consultas arbitrarias y complejas, y tienen la garantía de obtener la cantidad especificada de resultados.
Si usted (o los demás) se encuentran constantemente buscando o examinando tesoros de documentación en busca de información específica, le recomiendo que adapte este proceso a su propio caso de uso. Puede modificarlo para que funcione con sus documentos personales o los archivos de su empresa. Y si lo hace, le garantizo que verá sus documentos bajo una nueva luz.
¡Aquí hay algunas formas en las que puedes ampliar esto para tus propios documentos!
- Búsqueda híbrida : combina la búsqueda vectorial con la búsqueda tradicional por palabras clave
- Globalícese: utilice Qdrant Cloud para almacenar y consultar la colección en la nube
- Incorporar datos web: utilizar solicitudes para descargar HTML directamente desde la web
- Automatice las actualizaciones: use Github Actions para activar el recálculo de las incrustaciones cada vez que cambien los documentos subyacentes
- Incrustar: envuelva esto en un elemento de Javascript y colóquelo como reemplazo de una barra de búsqueda tradicional
Todo el código utilizado para crear el paquete es de código abierto y se puede encontrar en el repositorio voxel51/fiftyone-docs-search .


