

Wim Blommaert, 14 de mayo de 2025. MEDIUM. Blog de ING
¿Qué pasaría si la IA generara tus datos de prueba?
La calidad de las pruebas depende de los datos disponibles. Todos hemos pasado por la dificultad (principalmente debido a la creciente regulación de la privacidad) de obtener datos de prueba (incluidos los casos especiales) cuando los necesitamos y donde los necesitamos. Hablaremos sobre cómo en ING utilizamos la IA como una de las soluciones a este problema.
Capítulo I — La evidencia
En esta entrada del blog, hablaremos sobre la generación automática de datos de prueba mediante IA. Existe mucha discusión sobre la generación de datos sintéticos mediante IA generativa. Empecemos por hacerlo un poco más práctico. A continuación, se muestran dos subpantallas, cada una con información de pago que puede ser datos reales o sintéticos generados por IA.

En una conferencia reciente, pedí a mi público que señalara el pago real. La votación se dividió al 50%. Sin embargo, ambas pantallas son sintéticas generadas por IA. La primera vez que inyectamos 10.000 de estos pagos sintéticos generados automáticamente en el entorno de prueba, recibimos cierta resistencia de los evaluadores, ya que no podían distinguirlos fácilmente de los pagos «reales» que habían creado usando las pantallas de pago. Por eso, decidimos añadir la palabra «TEST» a la identificación del pago sintético (amarillo en las pantallas). Este ejemplo muestra la madurez de esta tecnología.
Capítulo II — El caso comienza
Mi trayectoria con los datos sintéticos comenzó hace cuatro años. Uno de mis proyectos se canceló y me quedé con un científico de datos de repuesto. En lugar de prescindir de él, elaboramos una lista de temas de automatización de pruebas que podríamos abordar con IA. El primer punto de la lista era usar inteligencia artificial para generar casos de prueba. Hace cuatro años, era un problema difícil de resolver. Hoy lo estamos revisando, ya que la evolución reciente de los modelos de lenguaje ha acercado las soluciones. Luego, abordamos el segundo tema de la lista: la generación de datos de prueba mediante IA. Durante nuestro estudio de mercado inicial, encontramos un artículo de investigación (respaldado por código abierto) del MIT. Ahí fue donde comenzamos. Hoy contamos con más de 20 aplicaciones para las que hemos generado datos de prueba sintéticos. Estamos construyendo una plataforma y hemos llevado a cabo un proyecto exitoso para generar datos sintéticos y construir un modelo de IA.
Capítulo III — El motivo
¿Por qué invertir en una tecnología emergente que puede generar automáticamente datos de prueba?

Todos sabemos que al entregar software a producción, ocurren cosas, y no siempre son las que deseamos. Por eso probamos y necesitamos datos de prueba. Con frecuencia, estos datos se copian desde producción, pero esto conlleva muchas condiciones.
Costoso
Copiar datos de producción tiene un costo. Tendrá que enmascarar sus datos. Dependiendo del volumen de datos, la copia también implica un costo en términos de tiempo y espacio en disco. Si copia el sistema de registros, podría tener que procesar todos esos datos para acceder a la capa de informes que deseaba probar.
Lento
Es posible que el equipo de pruebas no tenga acceso para copiar datos de producción y tenga que solicitarlo a otro equipo (de operaciones). Una encuesta que realizamos reveló que, en promedio, los usuarios tenían que esperar tres semanas desde que solicitaban los datos hasta que se cargaban en el entorno de pruebas.
Sensible a la privacidad
A veces, los datos no se pueden copiar desde producción, incluso con enmascaramiento. Este método también puede resultar más complejo de lo previsto. Por ejemplo, los campos de unión de un modelo de datos deben enmascararse de forma consistente en ambos extremos de la unión para preservar la integridad referencial. Si se enmascaran las fechas de nacimiento, es posible que aún haya que asegurarse de que coincidan con la edad de los menores. Si se desea probar caracteres especiales en el nombre del cliente, omitir los nombres como parte del enmascaramiento no será de gran ayuda.
Incompleto
El último problema es que los datos podrían estar incompletos. Por ejemplo, al inicio de la pandemia de COVID, se otorgaron garantías gubernamentales a las pequeñas y medianas empresas para que pudieran seguir obteniendo préstamos. Este tipo de garantías nuevas aún no existían en producción, por lo que tampoco se incluirían en un conjunto de prueba copiado de la producción. Esto limita la copia de datos de la producción, ya que podrían no existir casos especiales o nuevos.
Capítulo IV — Resolución del caso
Los datos de prueba sintéticos pueden ayudar a resolver estos problemas.
Básicamente es automatización, por lo que una vez configurado puede ser muy rápido y ahorrarle tiempo y esfuerzo.
Puedes forzar a la IA a generar datos específicamente siguiendo tus instrucciones para probar casos especiales, lo que puede ser más efectivo que copiar millones de datos de producción y esperar que todo lo que necesitas esté allí.
Los datos sintéticos protegen al máximo la privacidad y, según el RGPD, no se consideran datos personales. Mientras que en el enmascaramiento solo se enmascaran unos pocos campos sensibles, dejando cientos de campos sin enmascarar con los que pueden trabajar los atacantes, en los datos sintéticos cada columna es sintética, lo que imposibilita un ataque de identidad.
Como la mayoría de los ingenieros utilizan datos de prueba en alguna etapa del proceso de desarrollo o están involucrados en el suministro de datos de prueba, tenemos una gran influencia ya que miles de ingenieros en ING pueden beneficiarse de esto.
Capítulo V — Historia Forense
Lo que la IA generativa puede hacer con las imágenes, también puede hacerlo con los datos tabulares.

Nos hemos familiarizado con las «falsificaciones profundas», imágenes generadas por IA generativa que parecen reales, pero son inventadas. Podemos usar el aprendizaje automático para aprender de imágenes reales y construir modelos para generar imágenes sintéticas realistas. La misma tecnología se puede aplicar para generar datos de prueba.
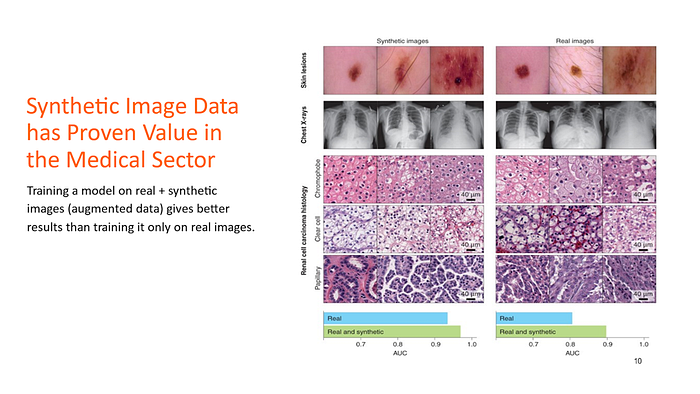
En los últimos años, esto se ha aplicado al sector médico. El software que detecta tumores en radiografías debe entrenarse con imágenes reales. Afortunadamente, no siempre disponen de tantas imágenes reales, por lo que las complementan con imágenes sintéticas. Incluso se ha demostrado que, en muchos casos, los datos aumentados (la combinación de imágenes reales y sintéticas) ofrecen mejores resultados que usar solo datos reales.

Analicemos los datos tabulares (ver imagen superior), que son los que solemos tener en bases de datos relacionales de Excel u Oracle. En la parte superior se encuentran los datos reales: una instantánea de una tabla con algunas filas. En la parte inferior se encuentran los datos sintéticos derivados de ella. Esto proviene de uno de nuestros proyectos (informes regulatorios al BCE). El principio fundamental de los datos sintéticos es que la IA debe aprender de los datos reales y producir los datos sintéticos, preservando sus propiedades estadísticas. ¿Qué significa esto?
Las frecuencias y distribuciones de las columnas deben coincidir . Si, por ejemplo, observamos el tipo de amortización de la columna, observamos que hay muchos pagos únicos. Observamos que esto también ocurre en los datos sintéticos, ya que la IA lo ha aprendido.
Las correlaciones entre columnas deben coincidir y tener sentido. Otro aspecto que la IA debe aprender es la correlación entre columnas. Por ejemplo, hay una columna que indica la fecha de vencimiento, la fecha de finalización del contrato y una columna que indica la fecha de inicio, denominada fecha de inicio. La fecha de vencimiento debe ser mayor que la fecha de inicio.
Al observar más de cerca, observamos que en la línea 236 la fecha de inicio del préstamo es posterior a la fecha de finalización, lo cual obviamente no es cierto. ¿Cómo es posible y qué queremos? Podría ser (como ocurrió durante nuestro proyecto) que este problema de calidad de los datos también existiera en los datos reales y que la IA lo detectara. Esto puede ser útil para probar casos de prueba negativos. Si no queremos estos «errores» en los datos sintéticos, podemos pedirle a la IA que respete siempre la secuencia de fechas. También podríamos pedirle a la IA que incluya algunos de estos «errores» a propósito; volveremos a este tema en los casos de uso.
Capítulo VI: Modus operandi
¿Cómo funciona?
En ING utilizamos Synthetic Data Vault (SDV), un software desarrollado originalmente y de código abierto en el MIT. Hace unos años, la tecnología se fusionó con la empresa Datacebo. Datacebo es nuestro socio para datos sintéticos generados por IA. SDV es un kit de desarrollo de software de Python. Esto nos proporciona una gran flexibilidad en su uso y en nuestra capacidad de integrarlo en nuestra infraestructura de ING.
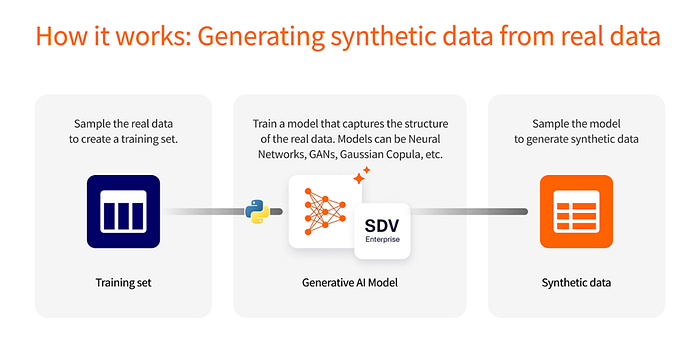
SDV funciona de forma muy similar a las tecnologías que generan deep fakes, salvo que se generan datos tabulares en lugar de imágenes. Siempre partimos de un conjunto de datos reales (el conjunto de entrenamiento) que alimentamos al algoritmo de IA. El algoritmo creará un modelo que contiene las propiedades estadísticas (como explicamos anteriormente) de los datos reales.
Una vez creado el modelo, podemos optar por el método inverso y solicitar a SDV que genere filas (de muestra) de datos sintéticos a partir del modelo. Se pueden utilizar diversas técnicas de IA para crear el modelo.
Una técnica consiste en usar redes neuronales (normalmente algún tipo de GAN), y la otra, algoritmos estadísticos como la cópula. Dado que el enfoque GAN no escala para modelos más grandes y requiere una gran cantidad de datos, nos centramos principalmente en la cópula. La cópula escala muy bien, no requiere una gran cantidad de datos para entrenar el modelo y ofrece un rendimiento excelente.
Los conjuntos de entrenamiento pueden ser pequeños; lo habitual es tener 20 000 filas, pero pueden usarse para generar millones de filas de datos sintéticos. El conjunto de entrenamiento debe provenir de producción o de un entorno inferior, siempre que sea representativo de los datos que queremos crear. Descubrimos que, en algún momento, aumentar el conjunto de entrenamiento ya no mejora la calidad de los datos sintéticos, ya que empezamos a mostrar a la IA los mismos patrones de datos una y otra vez. También se está investigando el uso de LLM, pero por ahora este enfoque parece presentar los mismos problemas que las GAN.
Capítulo VII: Escena del crimen
Ejemplos @ING
El primer ejemplo es el mencionado al principio de este artículo, con dos pantallas. El objetivo era generar datos de prueba sintéticos para probar un sistema de pago SEPA.
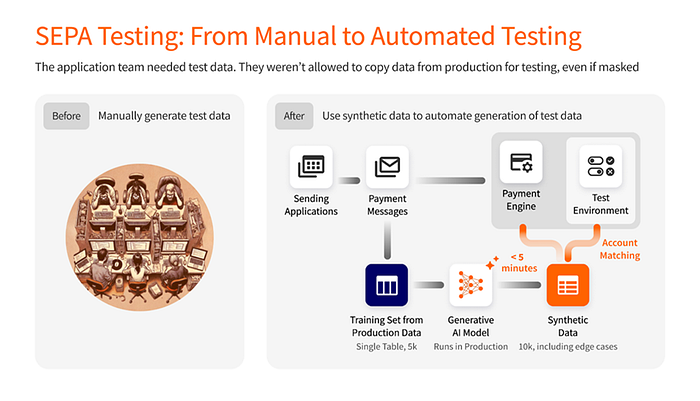
El equipo de pruebas, al no tener acceso a los datos de producción por motivos de privacidad, optó por crear manualmente sus propios pagos sintéticos en formato XML. Dado el alto coste de esta opción, el conjunto de pruebas terminó cubriendo principalmente algunos casos positivos.
Tomamos un conjunto real de 5.000 pagos de la cola de producción, entrenamos un modelo de IA y generamos 10.000 pagos sintéticos en menos de 2 minutos. El equipo de pruebas insertó estos pagos sintéticos en la cola de pagos del entorno de Aceptación para que el motor de pagos (OVI) pudiera procesarlos como si fueran pagos reales.
En ese momento, nos topamos con el problema de que el backend no reconocía los números de cuenta sintéticos. Teníamos dos opciones: sintetizar los (extensos) sistemas de back-office o usar los números de cuenta del entorno de Acceptance. Optamos por esta última opción y reemplazamos el IBAN sintético por el IBAN del entorno de Acceptance. Este enfoque demuestra que podemos combinar datos sintéticos (cola de pagos) con datos enmascarados en Acceptance (datos de back-office).
Una mejora adicional fue que, en lugar de generar 10 000 pagos aleatorios, generamos solo 20 pagos basados en los casos de prueba reales. Por ejemplo, el equipo solicitaba pagos con montos pequeños y grandes, pagos que se ejecutaban el mismo día, pero también algunos que se planificaban para una fecha posterior. Incluso podemos pedirle al modelo que genere valores que no ha visto en datos reales y que ni siquiera están en el modelo, pero que aun así podrían ser casos extremos interesantes. Contar con solo 20 puntos de datos de prueba muy específicos significa que hay menos pruebas que realizar.
El segundo ejemplo proviene de proyectos en los que utilizamos esta tecnología para probar API con software de simulación.
Normalmente, si quieres probar una API, llegarás al punto final de la API real. Le envías solicitudes y obtienes respuestas. A veces, es más conveniente realizar estas pruebas con una simulación, para no tener que conectarte a la API real. Por ejemplo, si esa API no siempre está disponible en tu entorno de prueba, llegas al punto final de la simulación, envías la solicitud y obtienes una respuesta. Pero, por supuesto, no ocurre nada. La simulación simplemente recibe tu solicitud y devuelve la respuesta que le indicaste según esa solicitud (implementada en una tabla de mapeo).
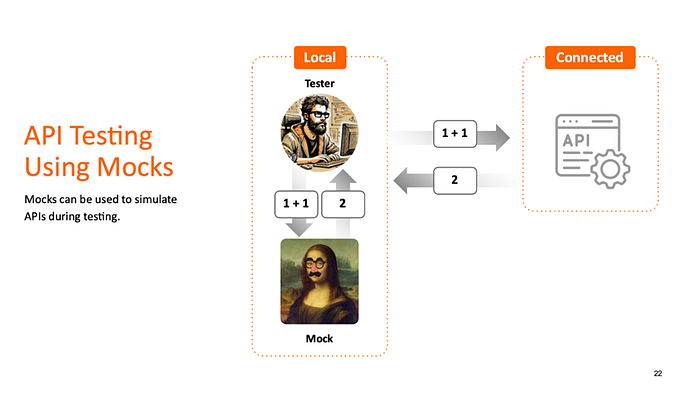
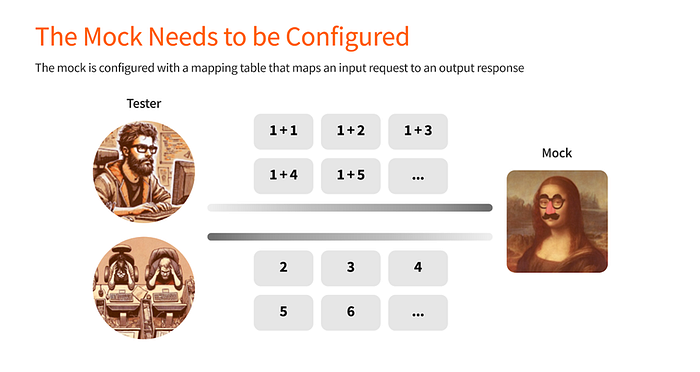
Todo esto suena bien, pero podría complicarse un poco si se quieren realizar, por ejemplo, 100 casos de prueba, teniendo que indicar al modelo 100 pares de solicitud-respuesta en la tabla de mapeo. Cada par puede ser bastante complejo. Completar 100 de ellos tomará mucho tiempo y provocará errores. Un ejemplo se muestra en la imagen a continuación.

La API de la parte involucrada se ejecuta en OnePam, el sistema global de clientes de ING. Le enviamos un ID de cliente (UUID) y recibimos la información del cliente. Tendría que escribirlos o buscar otra forma de hacerlo y luego entregarlos al simulador 100 veces. Esto limita el uso de dicho simulador y lo hace menos atractivo para los evaluadores.
La buena noticia es que podemos generar automáticamente esta tabla de mapeo usando SDV. El enfoque es el mismo que en el otro ejemplo. Para generar los pares en la tabla de mapeo, necesitamos comenzar con un conjunto de entrenamiento con pares reales de solicitud-respuesta de la API. Estos se obtienen del registro de Kafka de la API. Usamos 2000 de estos pares de ejemplo para entrenar el modelo. A partir de este modelo, podemos generar los pares que queremos introducir en el modelo simulado. Este es un buen ejemplo de la combinación de dos tecnologías (datos simulados y sintéticos) para ayudar a los ingenieros.
Capítulo VIII: El juicio
Hemos demostrado que el acceso a datos de prueba de calidad suele ser un problema y que los datos sintéticos generados por IA pueden ser una solución. Con ejemplos, hemos mostrado cómo esto ya se utiliza en ING. Si desea continuar este recorrido con nosotros, puede obtener una visión más técnica probando la versión de código abierto: SDV.


