
Incorporación de datos de series temporales en un formato tabular estándar para modelos ML clásicos y mejora de la precisión mediante AutoML.
Mateo Turco, 10 de enero 2025, Hacia la ciencia de datos. MEDIUM
Imagen: Ahasanara Akter
En este artículo, analizamos en profundidad cómo mejorar el proceso de previsión de los niveles de consumo diario de energía mediante la transformación de un conjunto de datos de series temporales en un formato tabular mediante bibliotecas de código abierto. Exploramos la aplicación de un modelo de clasificación multiclase popular y aprovechamos AutoML con Cleanlab Studio para aumentar significativamente nuestra precisión fuera de la muestra.
La conclusión clave de este artículo es que podemos utilizar métodos más generales para modelar un conjunto de datos de series de tiempo convirtiéndolo en una estructura tabular, e incluso encontrar mejoras al intentar predecir estos datos de series de tiempo.
Toma una instantánea
A un alto nivel nos proponemos:
- Establezca una precisión de referencia ajustando un modelo de pronóstico Prophet a nuestros datos de series de tiempo
- Convierta nuestros datos de series de tiempo en un formato tabular mediante el uso de bibliotecas de caracterización de código abierto y luego demostraremos que podemos superar a nuestro modelo Prophet con un enfoque de clasificación multiclase estándar (Gradient Boosting) con una reducción del 67 % en el error de predicción (aumento del 38 % en puntos porcentuales brutos en la precisión fuera de la muestra).
- El uso de una solución AutoML para la clasificación multiclase resultó en una reducción del 42 % en el error de predicción (aumento del 8 % en puntos porcentuales brutos en la precisión fuera de la muestra) en comparación con nuestro modelo Gradient Boosting y resultó en una reducción del 81 % en el error de predicción (aumento del 46 % en puntos porcentuales brutos en la precisión fuera de la muestra) en comparación con nuestro modelo de pronóstico Prophet.
Para ejecutar el código demostrado en este artículo, aquí está el cuaderno completo .
Examinar los datos
Puedes descargar el conjunto de datos aquí .
Los datos representan el consumo de energía por hora de PJM (en megavatios) por hora. PJM Interconnection LLC (PJM) es una organización de transmisión regional (RTO) de los Estados Unidos. Forma parte de la red Eastern Interconnection que opera un sistema de transmisión eléctrica que abastece a muchos estados.
Echemos un vistazo a nuestro conjunto de datos. Los datos incluyen una columna de fecha y hora ( objecttipo ), y la float64columna de Consumo de energía en megavatios ( tipo ) que estamos tratando de pronosticar como una variable discreta (que corresponde al cuartil de los niveles de consumo de energía por hora). Nuestro objetivo es entrenar un modelo de pronóstico de series de tiempo para poder pronosticar el nivel de consumo de energía diario de mañana que cae en 1 de 4 niveles: , lowo ( estos niveles se determinaron en función de los cuartiles de la distribución general del consumo diario). Primero demostramos cómo aplicar métodos de pronóstico de series de tiempo como Prophet a este problema, pero estos están restringidos a ciertos tipos de modelos de ML adecuados para datos de series de tiempo. A continuación, demostramos cómo reformular este problema en un problema de clasificación multiclase estándar al que podemos aplicar cualquier modelo de aprendizaje automático, y mostramos cómo podemos obtener pronósticos superiores mediante el uso de ML supervisado potente.below averageabove averagehigh
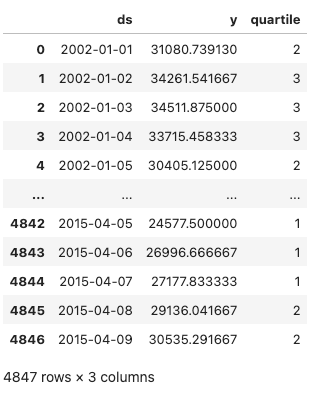
Primero, convertimos estos datos en un consumo de energía promedio a nivel diario y renombramos las columnas al formato que espera el modelo de pronóstico de Prophet. Estos niveles de consumo de energía diarios con valores reales se convierten en cuartiles, que es el valor que intentamos predecir. Nuestros datos de entrenamiento se muestran a continuación junto con el cuartil en el que se encuentra cada nivel de consumo de energía diario. Los cuartiles se calculan utilizando datos de entrenamiento para evitar la fuga de datos.
Ahora mostramos los datos de entrenamiento a continuación, que son los datos que estamos usando para ajustar nuestro modelo de pronóstico.
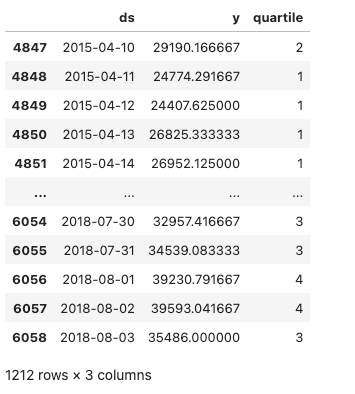
A continuación mostramos los datos de prueba a continuación, que son los datos con los que evaluamos los resultados de nuestro pronóstico.
Entrenar y evaluar el modelo de pronóstico Prophet
Como se ve en las imágenes de arriba, utilizaremos un límite de fecha de 2015-04-09para finalizar el rango de nuestros datos de entrenamiento y comenzar nuestros datos de prueba en 2015-04-10. Calculamos los umbrales de cuartil de nuestro consumo diario de energía utilizando ÚNICAMENTE datos de entrenamiento. Esto evita la fuga de datos, utilizando datos fuera de la muestra que solo estarán disponibles en el futuro.
A continuación, pronosticaremos el nivel de consumo diario de energía de PJME (en MW) durante la duración de nuestros datos de prueba y representaremos los valores pronosticados como una variable discreta. Esta variable representa en qué cuartil cae el nivel de consumo diario de energía, representado categóricamente como 1 ( low), 2 ( below average), 3 ( above average) o 4 ( high). Para la evaluación, vamos a utilizar la accuracy_scorefunción from scikit-learnpara evaluar el rendimiento de nuestros modelos. Dado que estamos formulando el problema de esta manera, podemos evaluar los pronósticos del día siguiente de nuestro modelo (y comparar modelos futuros) utilizando la precisión de clasificación.
import numpy como np
de Prophet import Prophet
de sklearn.metrics import precision_score
# Inicializar el modelo y entrenarlo con los datos de entrenamiento
model = Prophet()
model.fit(train_df)
# Crear un marco de datos para predicciones futuras que cubran el período de prueba
future = model.make_future_dataframe(periods= len (test_df), freq= 'D' )
forecast = model.predict(future)
# Categorizar los valores diarios pronosticados en cuartiles según los umbrales
forecast[ 'quartile' ] = pd.cut(forecast[ 'yhat' ], bins = [-np.inf] + list (quartiles) + [np.inf], labels=[ 1 , 2 , 3 , 4 ])
# Extraer los cuartiles pronosticados para el período de prueba
forecasted_quartiles = forecast.iloc[- len (test_df):][ 'quartile' ].astype( int )
# Categorizar los valores diarios reales en el conjunto de prueba en cuartiles
test_df[ 'quartile' ] = pd.cut(test_df[ 'y' ], bins=[-np.inf] + list (quartiles) + [np.inf], labels=[ 1 , 2 , 3 , 4 ])
actual_test_quartiles = test_df[ 'quartile' ].astype( int )
# Calcular las métricas de evaluación
accurate = accurate_score(actual_test_quartiles, forecasted_quartiles)
# Imprimir las métricas de evaluación
print ( f'Accuracy: {accuracy: .4 f} ' )
>>> 0.4249
La precisión fuera de la muestra es bastante pobre, del 43 %. Al modelar nuestras series temporales de esta manera, nos limitamos a utilizar únicamente modelos de pronóstico de series temporales (un subconjunto limitado de posibles modelos de ML). En la siguiente sección, consideramos cómo podemos modelar estos datos de manera más flexible al transformar las series temporales en un conjunto de datos tabulares estándar mediante la caracterización adecuada. Una vez que las series temporales se han transformado en un conjunto de datos tabulares estándar, podemos emplear cualquier modelo de ML supervisado para pronosticar estos datos de consumo diario de energía.
Convertir datos de series temporales en datos tabulares mediante caracterización
Ahora convertimos los datos de series temporales en un formato tabular y los caracterizamos utilizando las bibliotecas de código abierto sktime, tsfreshy tsfel. Al emplear bibliotecas como estas, podemos extraer una amplia gama de características que capturan patrones y características subyacentes de los datos de series temporales. Esto incluye características estadísticas, temporales y posiblemente espectrales, que brindan una instantánea completa del comportamiento de los datos a lo largo del tiempo. Al descomponer las series temporales en características individuales, resulta más fácil comprender cómo los diferentes aspectos de los datos influyen en la variable objetivo.
TSFreshFeatureExtractores una herramienta de extracción de características de la sktimebiblioteca que aprovecha las capacidades de tsfreshpara extraer características relevantes de los datos de series temporales. tsfreshestá diseñada para calcular automáticamente una gran cantidad de características de series temporales, lo que puede resultar muy beneficioso para comprender dinámicas temporales complejas. Para nuestro caso de uso, utilizamos el conjunto mínimo y esencial de características de nuestra TSFreshFeatureExtractorpara caracterizar nuestros datos.
tsfel, o biblioteca de extracción de características de series temporales, ofrece un conjunto completo de herramientas para extraer características de los datos de series temporales. Utilizamos una configuración predefinida que permite construir un amplio conjunto de características (por ejemplo, estadísticas, temporales, espectrales) a partir de los datos de series temporales de consumo de energía, capturando una amplia gama de características que podrían ser relevantes para nuestra tarea de clasificación.
import tsfel
from sktime.transformations.panel.tsfresh import TSFreshFeatureExtractor
# Definir el extractor de características tsfresh
tsfresh_trafo = TSFreshFeatureExtractor(default_fc_parameters= "minimal" )
# Transformar los datos de entrenamiento utilizando el extractor de características
X_train_transformed = tsfresh_trafo.fit_transform(X_train)
# Transformar los datos de prueba utilizando el mismo extractor de características
X_test_transformed = tsfresh_trafo.transform(X_test)
# Recupera un archivo de configuración de características predefinido para extraer todas las características disponibles
cfg = tsfel.get_features_by_domain()
# Función para calcular las características tsfel por día
def calculate_features ( group ):
# TSFEL espera un DataFrame con los datos en columnas, por lo que transponemos el grupo de entrada
features = tsfel.time_series_features_extractor(cfg, grupo, fs= 1 , verbose= 0 )
devolver características
# Agrupar por el nivel 'día' del índice y aplicar el cálculo de características
train_features_per_day = X_train.groupby(level= 'Date' ).apply(compute_features).reset_index(drop= True )
test_features_per_day = X_test.groupby(level= 'Date' ).apply(compute_features).reset_index(drop= True )
# Combinar cada caracterización en un conjunto de características combinadas para nuestros datos de entrenamiento/prueba
train_combined_df = pd.concat([X_train_transformed, train_features_per_day], axis= 1 )
test_combined_df = pd.concat([X_test_transformed, test_features_per_day], axis= 1 )
A continuación, limpiamos nuestro conjunto de datos eliminando las características que mostraron una alta correlación (por encima de 0,8) con nuestra variable objetivo (niveles de consumo de energía diario promedio) y aquellas con correlaciones nulas. Las características de alta correlación pueden provocar un sobreajuste, en el que el modelo funciona bien con los datos de entrenamiento, pero mal con los datos no vistos. Las características con correlación nula, por otro lado, no aportan ningún valor, ya que carecen de una relación definible con el objetivo.
Al excluir estas características, pretendemos mejorar la generalización del modelo y garantizar que nuestras predicciones se basen en un conjunto equilibrado y significativo de entradas de datos.
# Filtrar las características que están altamente correlacionadas con nuestra variable objetivo
column_of_interest = "PJME_MW__mean"
train_corr_matrix = train_combined_df.corr()
train_corr_with_interest = train_corr_matrix[column_of_interest]
null_corrs = pd.Series(train_corr_with_interest.isnull())
false_features = null_corrs[null_corrs].index.tolist()
columnas_a_excluir = list ( set (train_corr_with_interest[ abs (train_corr_with_interest) > 0.8 ].index.tolist() + false_features))
columnas_a_excluir.remove(column_of_interest)
# DataFrame filtrado excluyendo columnas con alta correlación con la columna de interés
X_train_transformed = train_combined_df.drop(columns=columns_to_exclude)
X_test_transformed = prueba_combinada_df.drop(columnas=columnas_a_excluir)
Si observamos las primeras filas de los datos de entrenamiento, esta es una instantánea de cómo se ven. Ahora tenemos 73 características que se agregaron a partir de las bibliotecas de caracterización de series temporales que usamos. La etiqueta que vamos a predecir en función de estas características es el nivel de consumo de energía del día siguiente.
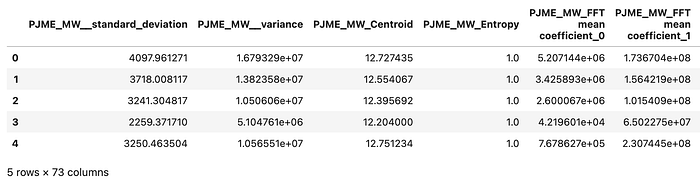
Es importante tener en cuenta que utilizamos una práctica recomendada de aplicar el proceso de caracterización por separado para los datos de entrenamiento y de prueba para evitar fugas de datos (y los datos de prueba retenidos son nuestras observaciones más recientes).
Además, calculamos nuestro valor de cuartil discreto (usando los cuartiles que definimos originalmente) usando el siguiente código para obtener nuestras etiquetas de energía de entrenamiento/prueba, que son nuestras y_labels.
# Defina una función para clasificar cada valor en un cuartil
def classify_into_quartile ( valor ):
if valor < cuartiles[ 0 ]:
return 1
elif valor < cuartiles[ 1 ]:
return 2
elif valor < cuartiles[ 2 ]:
return 3
else :
return 4
y_train = X_train_transformed[ "PJME_MW__mean" ].rename( " nivel_energético_diario " )
X_train_transformed.drop( "PJME_MW__mean" , inplace= True , axis= 1 )
y_test = X_test_transformed[ "PJME_MW__mean " ].rename( "nivel_energético_diario" )
X_test_transformed.drop( "PJME_MW__mean" , inplace= True , axis= 1 )
niveles_energía_entrenamiento = y_train.apply(clasificar_en_cuartil)
prueba_niveles_energia = y_test.apply(clasificar_en_cuartil)
Entrenar y evaluar el modelo GradientBoostingClassifier en datos tabulares destacados
Con nuestro conjunto de datos tabulares destacados, podemos aplicar cualquier modelo de aprendizaje automático supervisado para predecir los niveles futuros de consumo de energía. Aquí utilizaremos un modelo de clasificador de refuerzo de gradiente (GBC), el arma preferida por la mayoría de los científicos de datos que trabajan con datos tabulares.
Nuestro modelo GBC se instancia desde el sklearn.ensemblemódulo y se configura con hiperparámetros específicos para optimizar su rendimiento y evitar el sobreajuste.
de sklearn.ensemble importar GradientBoostingClassifier
gbc = GradientBoostingClassifier(
n_estimadores= 150 ,
tasa_de_aprendizaje= 0.1 ,
profundidad_máxima= 4 ,
muestras_hoja_mínimas= 20 ,
características_máximas= 'sqrt' ,
submuestra= 0.8 ,
estado_aleatorio= 42
)
gbc.fit(X_train_transformed, niveles_de_energía_train)
y_pred_gbc = gbc.predict(X_test_transformed)
gbc_accuracy = precision_score(niveles_de_energía_test, y_pred_gbc)
imprimir ( f'Precisión: {gbc_accuracy: .4 f} ' )
>>> 0.8075
La precisión fuera de muestra del 81% es considerablemente mejor que los resultados de nuestro modelo Prophet anterior.
Usar AutoML para simplificar las cosas
Ahora que hemos visto cómo caracterizar el problema de las series temporales y los beneficios de aplicar modelos de ML potentes como Gradient Boosting, surge una pregunta natural: ¿Qué modelo de ML supervisado deberíamos aplicar? Por supuesto, podríamos experimentar con muchos modelos, ajustar sus hiperparámetros y combinarlos. Una solución más sencilla es dejar que AutoML se encargue de todo esto por nosotros.
Aquí utilizaremos una solución AutoML simple proporcionada en Cleanlab Studio , que no requiere configuración. Solo proporcionamos nuestro conjunto de datos tabulares y la plataforma entrena automáticamente muchos tipos de modelos de ML supervisados (incluidos los de Gradient Boosting, entre otros), ajusta sus hiperparámetros y determina qué modelos son mejores para combinar en un solo predictor. Aquí está todo el código necesario para entrenar e implementar un clasificador supervisado de AutoML:
de cleanlab_studio import Studio
studio = Studio()
studio.create_project(
id_conjunto_de_datos=conjunto_de_datos_de_pronostico_de_energia,
nombre_del_proyecto= "PRONOSTICO_DE_NIVEL_DE_ENERGIA" ,
modalidad= "tabular" ,
tipo_de_tarea= "multiclase" ,
tipo_de_modelo= "regular" ,
columna_de_etiqueta= "nivel_de_energia_diario" ,
)
modelo = studio.get_model(modelo_de_pronostico_de_energia)
y_pred_automl = modelo.predict(datos_de_prueba, return_pred_proba= True )
A continuación, podemos ver las estimaciones de evaluación del modelo en la plataforma AutoML, que muestran todos los diferentes tipos de modelos ML que se ajustaron y evaluaron automáticamente (incluidos múltiples modelos Gradient Boosting), así como un predictor de conjunto construido combinando de manera óptima sus predicciones.
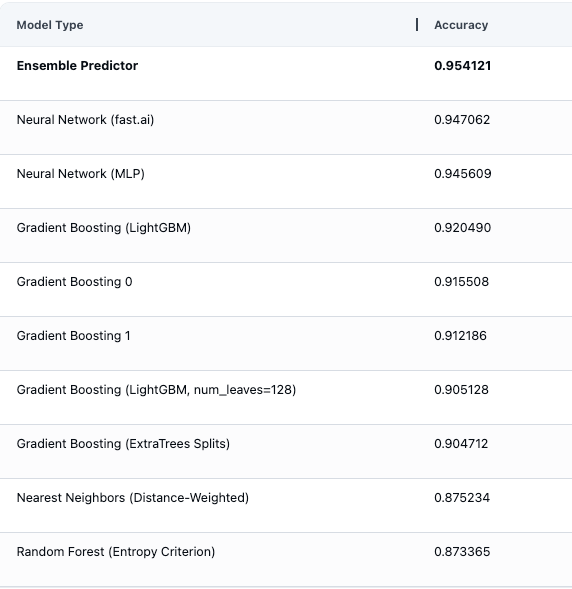
Después de ejecutar inferencias en nuestros datos de prueba para obtener las predicciones del nivel de consumo de energía del día siguiente, vemos que la precisión de la prueba es del 89 %, una mejora del 8 % en puntos porcentuales brutos en comparación con nuestro enfoque anterior de Gradient Boosting.

Conclusión
Para nuestros datos de consumo diario de energía de PJM, descubrimos que al transformar los datos en un formato tabular y caracterizarlos se logró una reducción del 67 % en el error de predicción (un aumento del 38 % en puntos porcentuales brutos en la precisión fuera de la muestra) en comparación con nuestra precisión de referencia establecida con nuestro modelo de pronóstico Prophet.
También probamos un enfoque AutoML sencillo para la clasificación multiclase, que resultó en una reducción del 42 % en el error de predicción (aumento del 8 % en puntos porcentuales brutos en la precisión fuera de la muestra) en comparación con nuestro modelo Gradient Boosting y resultó en una reducción del 81 % en el error de predicción (aumento del 46 % en puntos porcentuales brutos en la precisión fuera de la muestra) en comparación con nuestro modelo de pronóstico Prophet.
Al adoptar enfoques como los ilustrados anteriormente para modelar un conjunto de datos de series de tiempo más allá del enfoque restringido de considerar solo métodos de pronóstico, podemos aplicar técnicas de aprendizaje automático supervisado más generales y lograr mejores resultados para ciertos tipos de problemas de pronóstico.

