

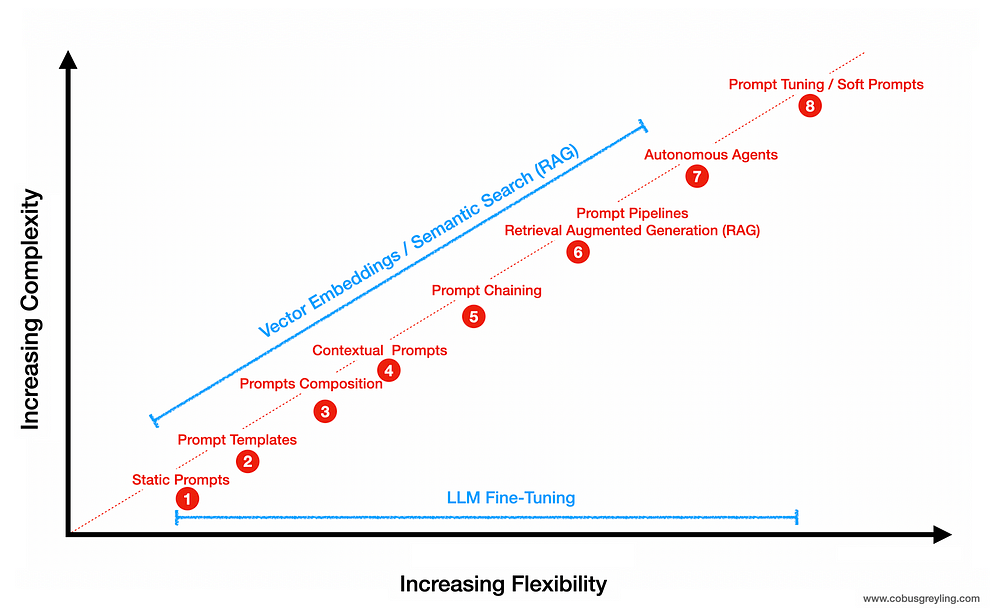
La habilidad de Prompt Engineering ha sido promocionada como la habilidad definitiva del futuro. Pero, ¿existirá la ingeniería pronta en un futuro próximo? En este artículo intento descomponer cómo se vería la futura interfaz LLM… considerando que será conversacional.
Cobus Greyling Medium
Actualmente soy el evangelista jefe de HumanFirst . Exploro y escribo sobre todas las cosas en la intersección de la IA y el lenguaje; que van desde LLM , Chatbots , Voicebots , Build Frameworks , suites de productividad de datos en lenguaje natural y más.
Introducción
Hace un año , a Sam Altman le hicieron la siguiente pregunta: ¿cómo interactuarán la mayoría de los usuarios con Foundation Models dentro de cinco años?
Sam Altman respondió diciendo que no cree que utilicemos ingeniería rápida dentro de cinco años. Destacó dos modalidades principales de entrada, voz o texto. Y una interfaz de usuario completa y no estructurada donde el lenguaje natural es la entrada y el modelo que actúa según las instrucciones del ser humano.
Hasta cierto punto, esta afirmación resulta discordante debido al hecho de que tanta tecnología e innovación se basan en el principio básico de la ingeniería rápida.
Se puede argumentar que Prompt Engineering es un lenguaje natural estructurado de cierta manera. Pero parece que a lo que se refiere el CEO de OpenAI son a interfaces verdaderamente desestructuradas y altamente intuitivas.
La mejor manera de intentar comprender el futuro de las interfaces LLM es comenzar desglosando los casos de uso.
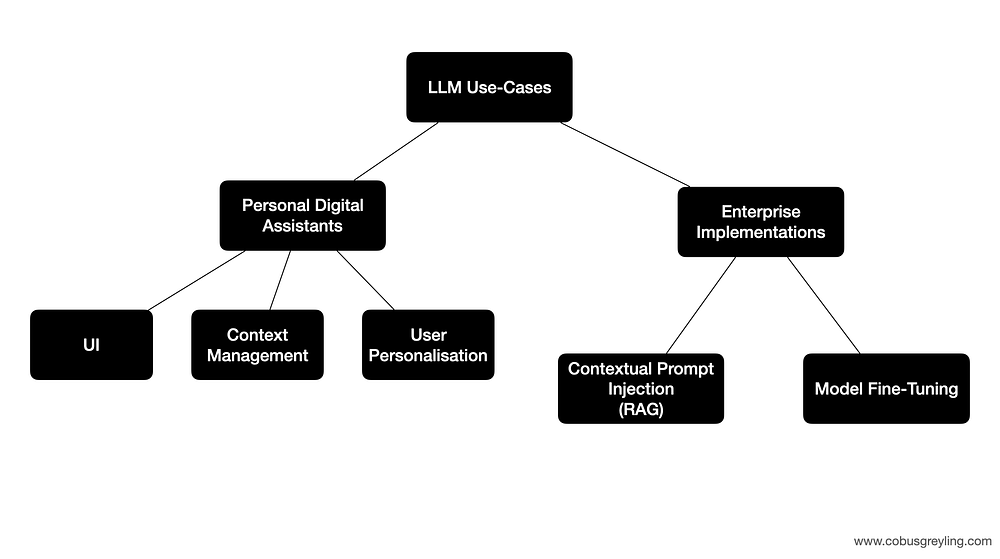
Hay dos casos de uso principales; Implementaciones personales y empresariales . Los asistentes digitales personales o de uso personal actualmente en circulación son HuggingChat , ChatGPT y Cohere Coral .
Lo que más me interesa son las implementaciones empresariales altamente escalables .
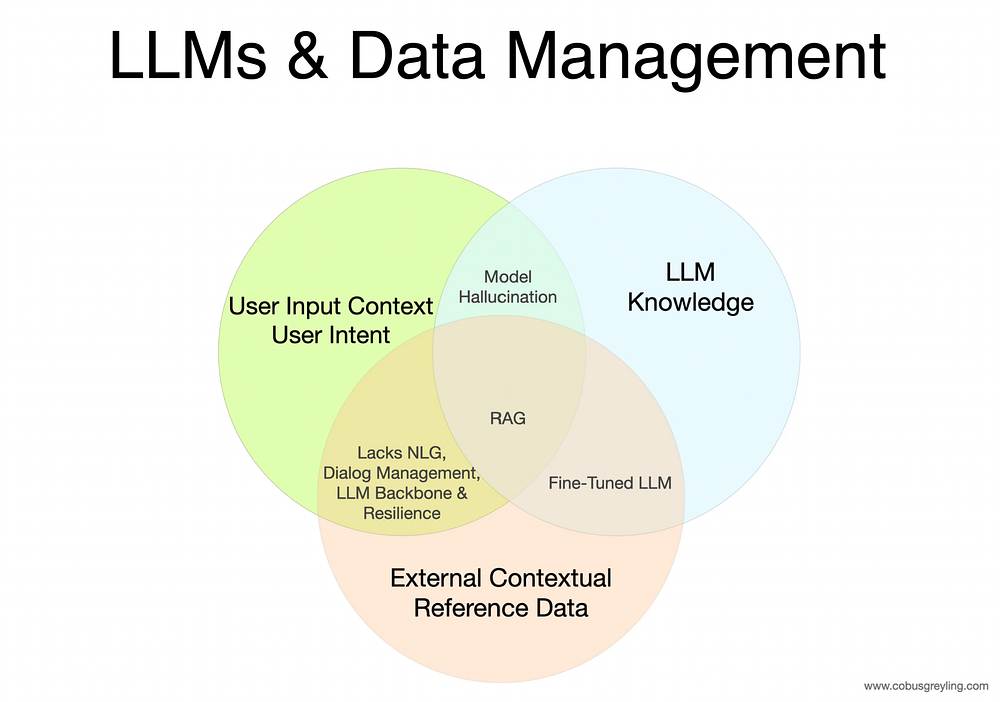
Teniendo en cuenta los casos de uso empresarial , los dos enfoques principales para manipular el LLM son [1] ajustar y [2] inyectar datos de referencia contextual (RAG) en el mensaje de inferencia (RAG). Un enfoque no necesariamente reemplaza al otro. El ajuste fino del modelo cambia el comportamiento y la respuesta del LLM. RAG complementa la entrada del usuario con una referencia contextual.
El problema del contexto y la ambigüedad
Uno de los principales desafíos de Prompt Engineering es el planteamiento y formulación de problemas. Traducir un requisito existente en el pensamiento a una solicitud de texto.
Dando un paso atrás, con los chatbots tradicionales establecer el contexto es muy importante. El contexto se establece primero clasificando la entrada del usuario según una o más intenciones . Se establece un contexto adicional a través de conversaciones previas, llamadas API a sistemas CRM, etc.
El contexto también depende en gran medida del tiempo y el lugar, y de cuál sea nuestra referencia espacial a la hora de plantear la pregunta.
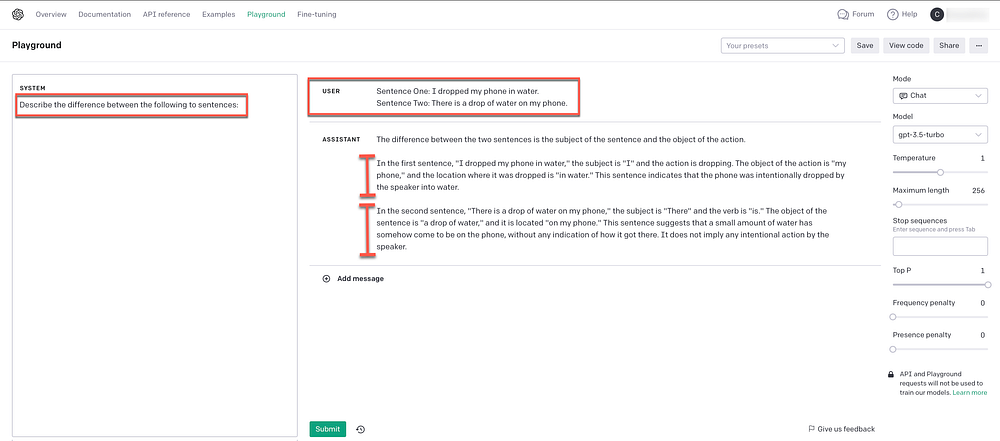
Aparte de la conciencia contextual, la ambigüedad también es un desafío. Considerando el siguiente ejemplo, esta forma de ambigüedad es fácil de decodificar para nosotros como humanos; pero tradicionalmente más difícil para NLU/chatbots.

Sin embargo, considere qué tan bien responde OpenAI a la siguiente pregunta a través del gpt-3.5-turbomodelo:
Pero hay una ambigüedad que es imposible de resolver con significados múltiples; un ejemplo de oración que es verdaderamente ambigua y requiere desambiguación es: I saw Tom with binoculars.
Conversación estructurada
Aunque la predicción de Sam Altman habla de que la interfaz será más natural y menos diseñada , se está produciendo un fenómeno interesante en términos de entrada y salida de LLM .
Vimos con OpenAI que los modos Editar y Completar se marcaban como heredados ( programados para su desuso ) y el modo de finalización del chat se establecía como un estándar de facto .
Siempre sostengo que la complejidad debe acomodarse en alguna parte, o la UX/UI es más compleja… o se le proporciona al usuario una interfaz de lenguaje natural no estructurada; lo que a su vez requiere complejidad en el lado de la solución.
Con ChatML se definen roles y se le da una estructura definida a la entrada al LLM. Como se ve en el ejemplo de código siguiente. Por lo tanto, el modo de entrada es más conversacional, pero se impone una estructura subyacente que debe respetarse.pip install openai
import os
import openai
openai.api_key = «xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx»
finalización = openai.ChatCompletion.create(
model= «gpt-3.5-turbo» ,
mensajes = [{ «rol» : «sistema» , «contenido» : «Tú son ChatGPT, un modelo de lenguaje grande entrenado por OpenAI. Responda lo más concisamente posible.\nLímite de conocimiento: 2021-09-01\nFecha actual: 2023-03-02» },
{ «rol» : «usuario» , «contenido» : «¿Cómo estás?» },
{ «rol» : «asistente», «content» : «Lo estoy haciendo bien» },
{ «role» : «user» , «content» : «¿Cuál es la misión de la empresa OpenAI?» }]
)
#print(finalización)
print (finalización)
Conclusión
- La intención , el contexto , la ambigüedad y la desambiguación son parte integrante de cualquier conversación.
- Con una interfaz de lenguaje humano, el contexto y la conciencia contextual siempre serán importantes.
- La ambigüedad existe y un nivel de desambiguación es parte integrante de la conversación humana. En la conversación humana utilizamos continuamente la desambiguación para establecer significado e intención.
- La desambiguación se puede automatizar hasta cierto punto con el aprendizaje automático en contexto . Este es el proceso por el cual la interfaz de usuario conversacional comprende cómo eliminar la ambigüedad en varios escenarios según la entrada del usuario en los menús de desambiguación .
- Por ejemplo, pedirle a un LLM que genere cinco opciones y usted, como usuario, seleccione la mejor respuesta generada, es una forma de desambiguación.
- La implementación específica de la empresa será específica del dominio y exigirá restricciones , con un nivel de detección fuera del dominio.
- La descomposición de problemas o solicitudes siempre será importante para crear una cadena de proceso de razonamiento de pensamiento.
- El ajuste fino establecerá el comportamiento del modelo y RAG proporcionará un contexto específico de inferencia.
- RAG crea una referencia contextual para que el LLM la utilice durante la inferencia.
- La gestión de datos siempre será parte de las solicitudes de LLM.
- Se debe tener en cuenta el principio de las indicaciones suaves . Los avisos suaves se crean durante el proceso de ajuste de avisos. A diferencia de las indicaciones físicas, las indicaciones suaves no se pueden ver ni editar en texto. Las indicaciones consisten en una incrustación, una cadena de números, que deriva el conocimiento del modelo más grande.
⭐️ Sígueme en LinkedIn para obtener actualizaciones sobre modelos de lenguajes grandes ⭐️



