Guía para construir una aplicación de recuperación agentic-GraphRAG: todos los códigos en mi repositorio de GitHub.
Dr. Karthik Rajan Publicado en Avances en IA, 15 de julio de 2024
Resumen gráfico de la integración y componentes clave R
La generación aumentada por recuperación de conocimiento (RAG, por sus siglas en inglés) es una herramienta poderosa que brinda a los modelos de lenguaje grandes (LLM, por sus siglas en inglés) la capacidad de acceder a datos del mundo real para obtener respuestas más informadas. Esto se logra al integrar los modelos con una base de datos de vectores para el aprendizaje y la adaptación en tiempo real. Esta característica hace que RAG sea una opción preferida para aplicaciones como chatbots y asistentes virtuales, donde la demanda de respuestas precisas y sensatas en tiempo real es alta. Una variante avanzada de esto, conocida como Graph Retrieval-Augmented Generation (GraphRAG), fusiona los beneficios de la recuperación de conocimiento basada en gráficos con los LLM, mejorando aún más las capacidades en el procesamiento del lenguaje natural. A diferencia de los métodos RAG tradicionales que se basan en búsquedas de similitud de vectores, GraphRAG construye un gráfico de conocimiento estructurado a partir de texto sin formato, capturando entidades, relaciones y afirmaciones críticas. Esto puede mejorar la capacidad de los LLM para comprender y sintetizar conjuntos de datos complejos y sus relaciones, lo que produce respuestas más precisas y contextualizadas.
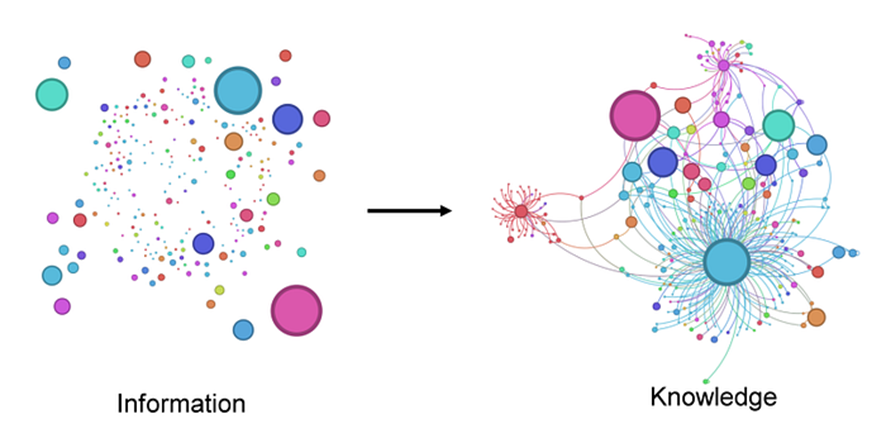
Extraído de un artículo de Markus Beuhler del MIT (enlace aquí )
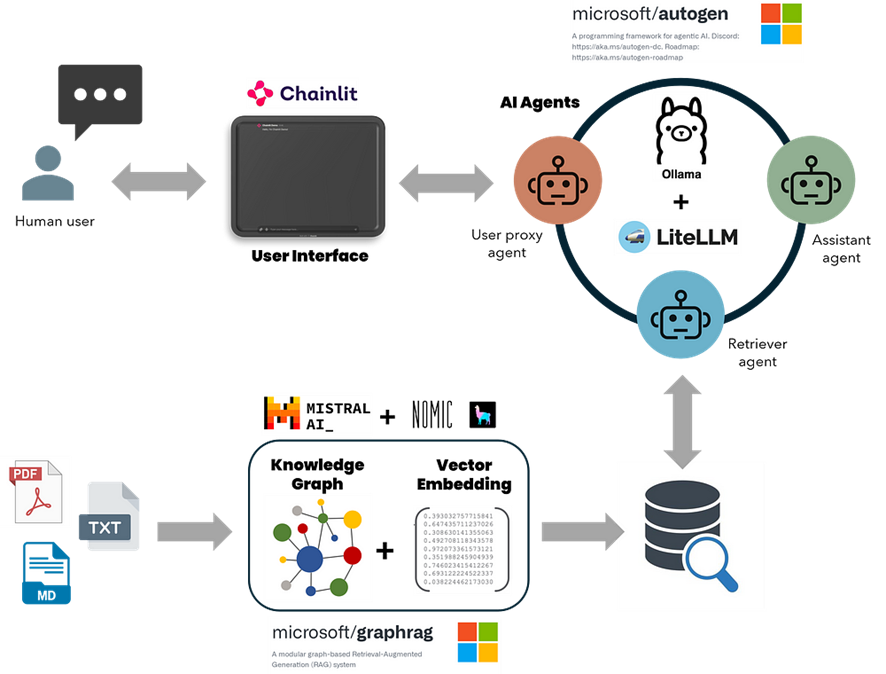
AutoGen es una herramienta de Microsoft que agiliza el desarrollo de aplicaciones complejas basadas en LLM multiagente mediante la automatización y optimización de flujos de trabajo que antes eran complicados y requerían un esfuerzo manual significativo. Imagine AutoGen como una plataforma en la que puede interactuar con múltiples GPT en lugar de solo uno. Cada GPT actúa como un «agente» individual, desempeñando un papel único en una operación integral. La combinación de las fortalezas de recuperación de GraphRAG con las funcionalidades conversacionales y orientadas a tareas de los agentes de IA de AutoGen da como resultado asistentes de IA robustos capaces de manejar de manera eficiente consultas detalladas, generar y ejecutar códigos, crear informes científicos de varias páginas y realizar análisis de datos. Además, los LLM locales sin conexión, como los de Ollama o LM Studio, garantizan un procesamiento de datos rentable y seguro. Los LLM locales eliminan los altos costos y los riesgos de privacidad asociados con los LLM en línea, manteniendo los datos confidenciales dentro de la organización y reduciendo los gastos operativos.
Este artículo le guiará en la construcción de una aplicación de IA multiagente con el sistema de recuperación GraphRAG, que funciona completamente en su máquina local y está disponible sin cargo. Estos son los componentes clave de esta aplicación:
- Los métodos de búsqueda de conocimiento de GraphRAG están integrados con un agente AutoGen a través de una llamada de función.
- GraphRAG (búsqueda local y global) está configurado para admitir modelos locales de Ollama para inferencia e incrustación.
- AutoGen se amplió para admitir la llamada de funciones con LLM que no son OpenAI desde Ollama a través del servidor proxy Lite-LLM.
- Interfaz de usuario Chainlit para gestionar conversaciones continuas, subprocesos múltiples y configuraciones de entrada del usuario.
GRAMOA pesar de mi experiencia en ciencia de materiales y modelado computacional, quería probar esta aplicación mediante la construcción de gráficos de conocimiento a partir de la documentación de ABAQUS, un software de ingeniería de FEA, y algunas hojas de datos técnicos de fibras de carbono y polímeros. La precisión general del uso de los LLM locales podría ser mejor, considerando la complejidad de este conjunto de datos. Los artículos futuros explorarán los aprendizajes de los estudios de referencia utilizando diferentes modelos para la incrustación y la inferencia. Sin embargo, estoy ansioso por construir gráficos de conocimiento más complejos a partir de revistas científicas y datos en este campo, probar tareas avanzadas de generación de código de ingeniería y utilizar un asistente conversacional para intercambiar ideas sobre temas científicos dentro de mi experiencia. La aplicación se ve así.
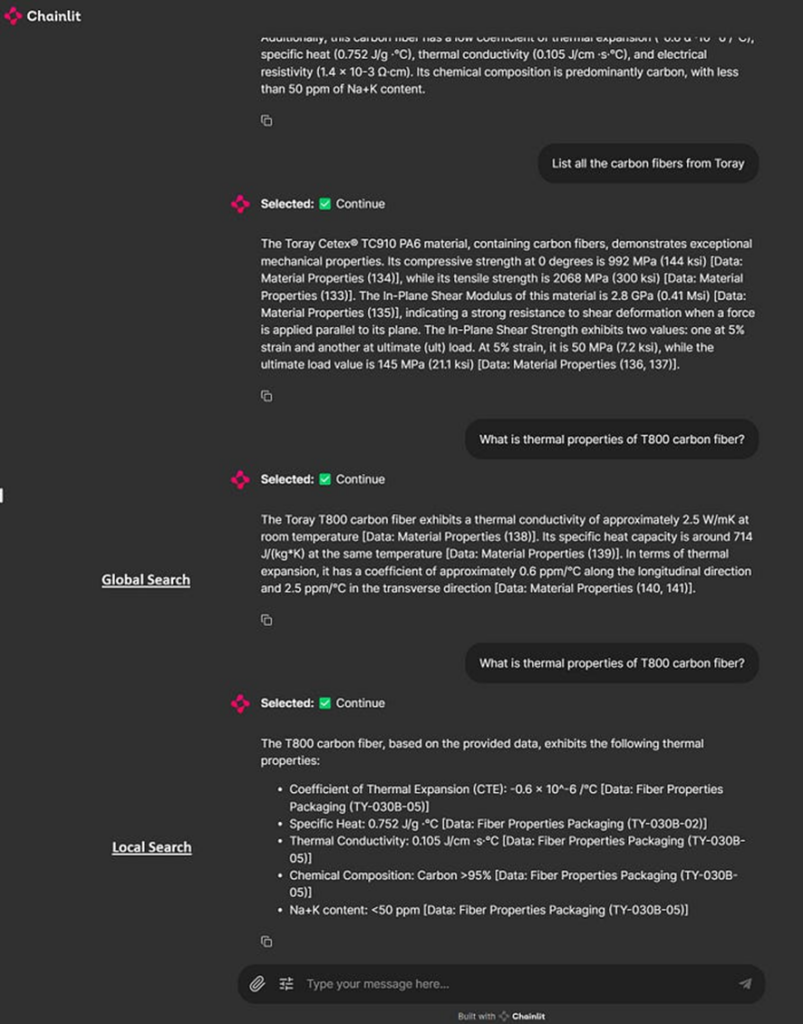
Interfaz de usuario de la aplicación principal con consultas de ejemplo. Las dos últimas tienen la misma consulta, pero la primera es una búsqueda global, mientras que la segunda es local.
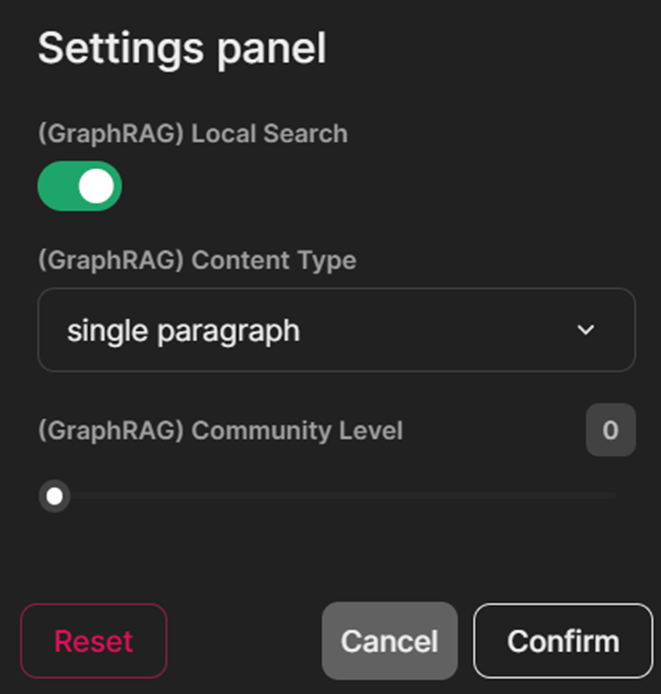
Configuración de widgets para cambiar entre búsqueda local y global, establecer niveles de comunidad y duración de generación.
El desarrollo se realizó en un entorno Linux utilizando el Subsistema de Windows para Linux (WSL) y Visual Studio Code en una PC con Windows 11 con un procesador i9 de 13.ª generación, 64 GB de RAM y 24 GB de Nvidia RTX 4090. Para obtener la mejor experiencia en el desarrollo y prueba de esta aplicación, se recomienda utilizar una distribución de Linux o WSL. No he probado esto en un entorno nativo de Windows. Para obtener instrucciones sobre la instalación de WSL y la configuración de entornos Python y Conda, consulte este artículo ( aquí ). Se proporcionan referencias adicionales e información relevante al final de este artículo.
Aquí está el enlace al repositorio de código fuente. ¡Ahora, comencemos!
Instalar dependencias del modelo y clonar el repositorio.
Instalar modelos de lenguaje de Ollama para inferencia e incrustación
# Mistral para inferencia GraphRAG
ollama pull mistral
# Nomic-Embed-Text para incrustación GraphRAG
ollama pull nomic-embed-text
# LLama3 para inferencia Autogen
ollama pull llama3
# Aloje Ollama en un servidor local: http://localhost:11434
ollama serve
Cree un entorno conda e instale estas dependencias
# Crear y activar un entorno conda
conda create -n RAG_agents python=3.12
conda activate RAG_agents
# Servidor proxy Lite-LLM para Ollama
pip install ‘litellm[proxy]’
# Instalar Ollama
pip install ollama
# Microsoft AutoGen
pip install pyautogen «pyautogen[retrievechat]»
# Microsoft GraphRAG
pip install graphrag
# Codificador-decodificador de token de texto
pip install tiktoken
# Aplicación Python de Chainlit
pip install chainlit
# Clonar mi repositorio de Git-hub
git clone https://github.com/karthik-codex/autogen_graphRAG.git
# (BONUS) Para convertir archivos PDF a Markdown para GraphRAG
pip install marker-pdf
# (BONUS) Solo si instalaste Marker-pdf, ya que elimina la compatibilidad con GPU CUDA de forma predeterminada conda install pytorch Torchvision Torchaudio pytorch-cuda=12.1 -c pytorch -c Nvidia
Encontrarás los siguientes archivos en mi repositorio de GitHub.
- /requirements.txt— Contiene una lista de todos los paquetes anteriores
- /utils/settings.yaml— Contiene la configuración LLM para usar Mistral 7B y Nomic-Text-Embedding de Ollama para la incrustación e indexación fuera de línea de GraphRAG. Utilizará este archivo para reemplazar el que se creó cuando inicializó GraphRAG en su directorio de trabajo por primera vez.
- /utils/chainlit_agents.py— Contiene definiciones de clase que incluyen el asistente de AutoGen y los agentes proxy de usuario. Esto permite realizar un seguimiento de varios agentes y mostrar sus mensajes en la interfaz de usuario. (Un agradecimiento al equipo de Chainlit por crear la plantilla ).
- /utils/embedding.py— Contiene las funciones de incrustación modificadas para la incrustación de GraphRAG para consultas de búsqueda locales mediante Ollama. Utilizarás este archivo para reemplazar el que está dentro del paquete GraphRAG (más información a continuación)
- utils/openai_embeddings_llm.py—Contiene las funciones de incrustación modificadas para la indexación e incrustación de GraphRAG mediante Ollama. Utilizará este archivo para reemplazar el que se encuentra dentro del paquete GraphRAG (más información a continuación).
- /appUI.py— Contiene las principales funciones asincrónicas para configurar agentes, definir funciones de búsqueda GraphRAG, rastrear y manejar mensajes y mostrarlos dentro de la interfaz de usuario de Chainlit.
- /utils/pdf_to_markdown.py— Archivo adicional que contiene funciones para convertir archivos PDF a archivos Markdown para la ingesta de GraphRAG.
Crear una base de conocimientos de GraphRAG.
Inicialice GraphRAG en la carpeta raíz del repositorio
#crea una nueva carpeta «input» para colocar tus archivos de entrada para GraphRAG (.txt o .md) mkdir -p ./input # Inicializa GraphRAG para crear los archivos y carpetas requeridos en el directorio raíz python -m graphrag.index –init –root .
# Mueve el archivo settings.yaml para reemplazar el creado por GraphRAG –init
mv ./utils/settings.yaml ./
Configurar los ajustes de GraphRAG para admitir modelos locales de Ollama
A continuación, se incluye un fragmento que settings.yamlilustra la configuración de los LLM para crear índices e incrustaciones. GraphRAG requiere una longitud de contexto de 32k para la indexación, lo que hace que Mistral sea el modelo elegido. Para las incrustaciones, se selecciona Nomic-embed-text, aunque puede experimentar con otras incrustaciones de Ollama. No es necesario configurar ${GRAPHRAG_API_KEY}, ya que no se requiere acceso a los puntos finales de estos modelos locales.
modelo_de_codificación: cl100k_base
skip_workflows: []
llm:
api_key: ${GRAPHRAG_API_KEY}
tipo: openai_chat # o azure_openai_chat
modelo: mistral
model_supports_json: true
api_base: http://localhost:11434/v1
.
.
.
incrustaciones:
async_mode: threaded # o asyncio
llm:
api_key: ${GRAPHRAG_API_KEY}
tipo: openai_embedding # o azure_openai_embedding
modelo: nomic_embed_text
api_base: http://localhost:11434/api
.
.
.
entrada: #Cambiar el patrón del archivo de entrada a .md o .txt
tipo: archivo # o blob
tipo_de_archivo: texto # o csv
directorio_base: «entrada»
codificación_de_archivo: utf-8
patrón_de_archivo: «.*\\.md$»
Puede especificar la carpeta que contiene los archivos de entrada en la carpeta “input” del directorio raíz. Se pueden utilizar tanto archivos de texto como de Markdown. Puede utilizar el /utils/pdf_to_markdown.pypara convertir sus archivos PDF en archivos de Markdown que luego se colocan dentro de la carpeta “input”. No se ha descubierto cómo manejar múltiples formatos de archivo, pero es un problema solucionable.
Antes de ejecutar GraphRAG para indexar, crear incrustaciones y realizar consultas locales, debe modificar los archivos de Python openai_embeddings_llm.py y embedding.pyque se encuentran dentro del paquete GraphRAG. Sin esta modificación, GraphRAG generará un error al crear incrustaciones, ya que no reconocerá «nomic-embed-text» como un modelo de incrustación válido de Ollama. En mi configuración, estos archivos se encuentran en /home/karthik/miniconda3/envs/RAG_agents/lib/python3.12/site-packages/graphrag/llm/openai/openai_embeddings_llm.pyy/home/karthik/miniconda3/envs/RAG_agents/lib/python3.12/site-packages/graphrag/query/llm/oai/embedding.py
Puedes localizar estos archivos usando el comando sudo find / -name openai_embeddings_llm.py.
Crear incrustaciones y gráficos de conocimiento.
Por último, creamos las incrustaciones y probamos el gráfico de conocimiento utilizando el método de búsqueda global o local. Después de completar el proceso de incrustación, puede encontrar los artefactos de salida (archivos .parquet) y los informes (.json y .logs) en la carpeta “output” de su directorio de trabajo GraphRAG, que es la carpeta raíz en esta instancia.
# Crear un gráfico de conocimiento: esto lleva algo de tiempo
python -m graphrag.index –root .
# Probar GraphRAG
python -m graphrag.query –root . –method global «<inserte su consulta>»
Inicie el servidor Lite-LLM y ejecute la aplicación desde la terminal
A continuación se muestra el comando para inicializar el servidor antes de ejecutar la aplicación. Elegí Llama3:8b para probar esta aplicación. Puede utilizar modelos más grandes si su hardware lo permite. Puede encontrar más información sobre Lite-LLM en este enlace . Ahora, está listo para ejecutar la aplicación desde otra terminal. Asegúrese de estar en el entorno conda correcto.
# iniciar el servidor desde la terminal
litellm –model ollama_chat/llama3
# ejecutar la aplicación desde otra terminal
chainlit run appUI.py
Desglose: componentes principales de appUI.py
Importar bibliotecas de Python
importar autogen
desde rich importar print
importar chainlit como cl
desde writing_extensions importar Annotated
desde chainlit.input_widget importar (
Seleccionar, Control deslizante, Interruptor)
desde autogen importar AssistantAgent, UserProxyAgent
desde utils.chainlit_agents importar ChainlitUserProxyAgent, ChainlitAssistantAgent
desde graphrag.query.cli importar run_global_search, run_local_search
Notarás que se importan dos clases desde chainlit_agents . Estas clases contenedoras para agentes AutoGen permiten a Chainlit rastrear sus conversaciones y manejar la finalización u otras entradas del usuario. Puedes leer más sobre esto aquí .
Configurar agentes de AutoGen
Los agentes de AutoGen utilizan modelos de Ollama a través del servidor proxy Lite-LLM. Esto es necesario porque AutoGen no admite la invocación de funciones a través de modelos de inferencia que no sean de OpenAI. El servidor proxy permite utilizar modelos de Ollama para la invocación de funciones y la ejecución de código.
# LLama3 LLM desde el servidor Lite-LLM para agentes #
llm_config_autogen = {
«seed» : 40 , # cambia la semilla para diferentes pruebas
«temperature» : 0 ,
«config_list» : [{ «model» : «litellm» ,
«base_url» : «http://0.0.0.0:4000/» ,
‘api_key’ : ‘ollama’ },
],
«timeout» : 60000 , }
Cree una instancia de agentes e ingrese la configuración del usuario al inicio del chat
Creé tres widgets de Chainlit (interruptor, selección y control deslizante) como configuraciones de usuario para elegir el tipo de búsqueda de GraphRAG, el nivel de comunidad y el tipo de generación de contenido. Cuando está activado, el widget de interruptor utiliza el método de búsqueda local de GraphRAG para realizar consultas. Las opciones de selección para la generación de contenido incluyen «lista priorizada», «párrafo único», «párrafos múltiples» e «informe de varias páginas». El widget de control deslizante selecciona el nivel de generación de la comunidad con las opciones 0, 1 y 2. Puede leer más sobre las comunidades de GraphRAG aquí .
@cl.on_chat_start
async def on_chat_start ():
try :
settings = await cl.ChatSettings(
[
Switch( id = «Tipo_búsqueda» , etiqueta = «(GraphRAG) Búsqueda local» , inicial = True ),
Select(
id = «Tipo_gen» ,
etiqueta = «(GraphRAG) Tipo de contenido» ,
valores = [ «lista priorizada» , «párrafo único» , «párrafos múltiples» , «informe de varias páginas» ],
índice_inicial = 1 ,
),
Slider(
id = «Comunidad» ,
etiqueta = «(GraphRAG) Nivel de comunidad» ,
inicial = 0 ,
mín = 0 ,
máx = 2 ,
paso = 1 ,
),
]
).send()
tipo_respuesta = settings[ «Tipo_gen» ]
comunidad = settings[ «Comunidad» ]
búsqueda_local = settings[ «Tipo_búsqueda» ]
cl.user_session.set ( » Gen_type» , response_type)
cl.user_session.set ( «Community» , community) cl.user_session.set ( » Search_type» , local_search) retriever = AssistantAgent( name= «Retriever» , llm_config=llm_config_autogen, system_message= «»»Solo ejecuta la función query_graphRAG para buscar el contexto. Genera ‘TERMINATE’ cuando se haya proporcionado una respuesta.»»» , max_consecutive_auto_reply= 1 , human_input_mode= «NUNCA» , description= «Agente de Retriever» ) user_proxy = ChainlitUserProxyAgent( name= «User_Proxy» , modo_de_entrada_humana= «SIEMPRE» , llm_config=llm_config_autogen, is_termination_msg=
lambda x: x.get( «content» , «» ).rstrip().endswith( «TERMINATE» ),
code_execution_config= False ,
system_message= »’Un administrador humano. Interactúa con el recuperador para proporcionar cualquier contexto»’ ,
description= «Agente proxy de usuario»
)
print ( «Establecer agentes.» )
cl.user_session.set ( «Agente de consulta» , user_proxy) cl.user_session.set
( » Recuperador» , recuperador) msg = cl.Message(content= f»»»¡Hola ! ¿Qué tarea te gustaría realizar hoy? «»» , author= «User_Proxy» ) await msg.send() print ( «Mensaje enviado.» ) except Exception as e: print ( «Error: » , e) pass
Elegí no usar la clase contenedora Chainlit para el agente asistente del recuperador. Esto me permitió deshabilitar el seguimiento de la salida del recuperador y capturar directamente la respuesta de la función GraphRAG. La razón es que cuando la respuesta pasa por el recuperador, el texto pierde su formato, incluidos los espacios y las sangrías de párrafo. Este problema era especialmente notorio al generar informes de varias páginas con encabezados principales y secundarios. Pude conservar el formato original omitiendo la clase contenedora Chainlit y recuperando directamente la salida de la función GraphRAG. Verá cómo lo logré a continuación.
Actualizar los cambios en la configuración de entrada
Esta función detecta cualquier cambio realizado en los widgets de selección, interruptor y control deslizante desde la configuración para poder reflejar esos cambios en las consultas posteriores.
@cl.on_settings_update
async def setup_agent ( configuraciones ):
tipo_respuesta = configuraciones[ «Tipo_gen» ]
comunidad = configuraciones[ «Comunidad» ]
búsqueda_local = configuraciones[ «Tipo_búsqueda» ]
cl.user_session.set ( «Tipo_gen» , tipo_respuesta) cl.user_session.set ( «Comunidad» , comunidad) cl.user_session.set ( «Tipo_búsqueda» , búsqueda_local) print ( » on_settings_update » , configuraciones)
Actualizar la interfaz de usuario con mensajes entrantes de los agentes y del usuario.
Esta es la parte central de la aplicación, que crea un chat grupal con dos agentes, define una función “state_transition” para administrar la secuencia de conversación y proporciona la función de consulta RAG asincrónica.
Observará INPUT_DIR ,ROOT_DIR, RESPONSE_TYPE, COMMUNTIYlos parámetros que se pasan a las funciones de consulta de búsqueda local y global de GraphRAG en función del parámetro bool LOCAL_SEARCH. El valor ROOT_DIR,está configurado en ’.’: preste atención a esto si inicializó GraphRAG en un directorio diferente.
La función asincrónica “query_graphRAG” llama al método de búsqueda global o local de GraphRAG. Notarás la línea await cl.Message(content=result.response).send()dentro de la async def query_graphRAGfunción que recupera directamente el resultado de la consulta RAG y conserva el formato de texto del contenido recuperado.
@cl.on_message
async def run_conversation ( message: cl.Message ):
print ( «Conversación en ejecución» )
CONTEXTO = mensaje.contenido
MAX_ITER = 10
INPUT_DIR = None
ROOT_DIR = ‘.’
TIPO_RESPUESTA = cl.user_session.get( «Gen_type» )
COMUNIDAD = cl.user_session.get( «Comunidad» )
BÚSQUEDA_LOCAL = cl.user_session.get( «Search_type» )
print ( «Configuración de groupchat» )
retriever = cl.user_session.get( «Retriever» )
user_proxy = cl.user_session.get( «Query Agent» )
def state_transition ( last_speaker, groupchat ):
mensajes = groupchat.messages
si last_speaker es user_proxy:
devuelve retriever
si last_speaker es retriever:
si mensajes[- 1 ][ «content» ].lower() no está en [ ‘math_expert’ , ‘physics_expert’ ]:
devuelve user_proxy
de lo contrario :
si mensajes[- 1 ][ «content» ].lower() == ‘math_expert’ :
devolver user_proxy
else :
devolver user_proxy
else :
pasar
return None
async def query_graphRAG (
question: Annotated[ str , ‘Cadena de consulta que contiene la información que desea de la búsqueda RAG’ ]
) -> str :
if LOCAL_SEARCH:
result = run_local_search(INPUT_DIR, ROOT_DIR, COMMUNITY ,RESPONSE_TYPE, question)
else :
result = run_global_search(INPUT_DIR, ROOT_DIR, COMMUNITY ,RESPONSE_TYPE, question)
await cl.Message(content=result).send()
devolver resultado
para el llamador en [recuperador]:
d_retrieve_content = caller.register_for_llm(
description= «recupera contenido para la generación de código y respuesta a preguntas.» ,api_style= «función»
)(consulta_graphRAG)
para agentes en [user_proxy, retriever]:
agents.register_for_execution()(d_retrieve_content)
groupchat = autogen.GroupChat(
agents=[user_proxy, retriever],
messages=[],
max_round=MAX_ITER,
speakers_selection_method=state_transition,
allow_repeat_speaker= True ,
)
manager = autogen.GroupChatManager(groupchat=groupchat,
llm_config=llm_config_autogen,
is_termination_msg= lambda x: x.get( «content» , «» ) and x.get( «content» , «» ).rstrip().endswith( «TERMINATE» ),
code_execution_config= False ,
)
# ——————– Lógica de conversación. Edite para cambiar su primer mensaje en función de la tarea que desea realizar. —————————– #
si len (chat grupal.mensajes) == 0 :
await cl.make_async(usuario_proxy.iniciar_chat)( administrador, mensaje=CONTEXTO, )
elif len (chat grupal.mensajes) < MAX_ITER:
await cl.make_async(usuario_proxy.enviar)( administrador, mensaje=CONTEXTO, )
elif len (chat grupal.mensajes) == MAX_ITER:
await cl.make_async(usuario_proxy.enviar)( administrador, mensaje= «salir» , )
Para esta aplicación, solo necesitamos dos agentes. Puedes agregar o modificar agentes y configurar la función “state_transition” para orquestar la selección de hablantes en conversaciones para flujos de trabajo más complejos.
Reflexiones finales
Esta es mi primera incursión en el mundo de los agentes de IA, los LLM y los RAG, y me sumergí de lleno en la creación de esta implementación durante las últimas semanas, omitiendo muchos aspectos básicos. Si bien esta implementación es imperfecta, es una plantilla excelente para desarrollar aplicaciones más complejas. Sienta una base sólida para integrar múltiples funciones y agentes de codificación, y debería permitirle crear flujos de trabajo sofisticados, personalizar las interacciones de los agentes y mejorar la funcionalidad según sea necesario.
Acerca de mí : Soy ingeniero de modelado líder en Eaton Research Labs, Southfield, MI, EE. UU. Exploro, desarrollo herramientas y escribo sobre temas relacionados con la mecánica computacional, la ciencia de los materiales, la ingeniería, los modelos de lenguaje y la inteligencia artificial generativa.
Si quieres mantenerte actualizado sígueme en mis redes sociales a continuación.
Redes sociales: LinkedIn , GitHub , código fuente
Algunas referencias útiles
- https://medium.com/@datadrifters/autogen-litellm-and-open-source-llms-c4c6bc8fa9c5
- https://medium.com/@rajib76.gcp/memory-default-compute-fallback-5ff4287d47e6
- https://medium.com/generative-ai/graphrag-the-rag-approach-by-microsoft-e1abc7eb9fba
- https://docs.chainlit.io/get-started/overview
- https://medium.com/@antoineross/autogen-web-application-using-chainlit-8c5ebf5a4e75