

Abhishek Chaudhary 1 de febrero de 2024 MEDIUM
Muchos de nosotros tenemos una comprensión funcional de las redes neuronales y de cómo funcionan. Incluso he estudiado este término en particular varias veces y cada vez me convenzo de que sé de lo que estoy hablando. El cerebro humano es divertido en ese sentido; toma el camino de menor resistencia y nos convence de que sabemos algo cuando no lo sabemos. Aunque he usado redes neuronales varias veces para tareas que van desde la clasificación binaria hasta el procesamiento del lenguaje natural, nunca las he implementado desde cero y, si eres como yo, entonces tu comprensión de las redes neuronales termina en Y = WX + b.
En este artículo, implementaré una red neuronal desde cero, repasando diferentes conceptos como derivadas, descenso de gradientes y propagación hacia atrás de gradientes. También me gustaría mencionar que este artículo está inspirado en la brillante serie de conferencias de Anderj Karapthy en YouTube, y utilizaré parte del código mencionado en ese video.
Este artículo también tiene un cuaderno J upyter correspondiente con todo el código que se describe a continuación.
Introducción
No dude en pasar a la siguiente sección, ya que la sección de introducción cubre la teoría de las redes neuronales y no la implementación.
Las redes neuronales son un tipo de modelo de máquina inspirado en la estructura del cerebro humano. Al igual que nuestro cerebro, las redes neuronales están formadas por neuronas que trabajan juntas para realizar una gran variedad de tareas. El siguiente diagrama muestra la arquitectura de una neurona:
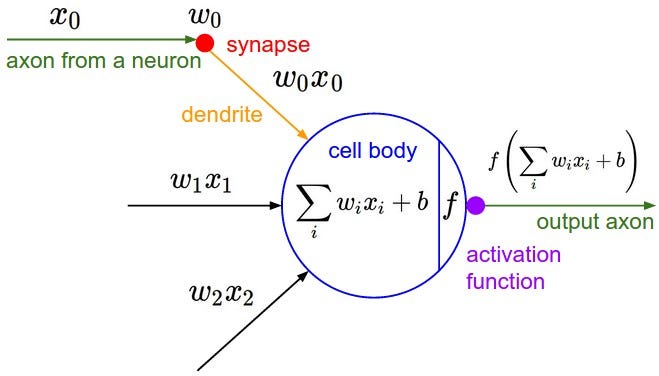
Dónde :
output: Este es el valor final o activación de la neurona.activation_function: Esta es una función matemática que determina si la neurona debe activarse o no en función de su entrada.weighted_sum: Es la suma de los productos de los valores de entrada y sus pesos correspondientes.bias: Se agrega un término de sesgo a la suma ponderada para proporcionar a la neurona cierta flexibilidad en su activación.
La suma ponderada se calcula de la siguiente manera: weighted_sum = (w1 * x1) + (w2 * x2) + ... + (wn * xn)Donde:
w1, w2, ..., wn: Estos son los pesos asociados con cada entrada.x1, x2, ..., xn: Estos son los valores de entrada.
La función de activación puede ser cualquier función no lineal, como la función sigmoidea, ReLU (Unidad lineal rectificada) o softmax, según el tipo de neurona y la tarea en cuestión.
La función de la función de activación es introducir no linealidad en la salida de la neurona, permitiéndole aprender patrones y relaciones complejos en los datos.
En resumen, una sola neurona en una red neuronal toma valores de entrada, les aplica pesos, los suma con un término de sesgo y luego pasa el resultado a través de una función de activación para producir una salida. Luego, esta salida se utiliza como entrada para capas o neuronas posteriores en la red neuronal, lo que permite a la red aprender y hacer predicciones para diversas tareas.
Ahora, dejando de lado toda la teoría, implementemos una neurona. Empezando por los derivados.
Deshacerse de las importaciones en las primeras etapas del procesoimportar matemáticas
importar numpy como np
importar matplotlib.pyplot como plt
%matplotlib inlinep
Derivados
Antes de pasar a las neuronas y las redes neuronales, repasemos brevemente las funciones y sus derivadas. Como todos hemos aprendido en la escuela, una derivada de una función con respecto a una variable muestra la tasa de cambio de la función con respecto a esa variable.
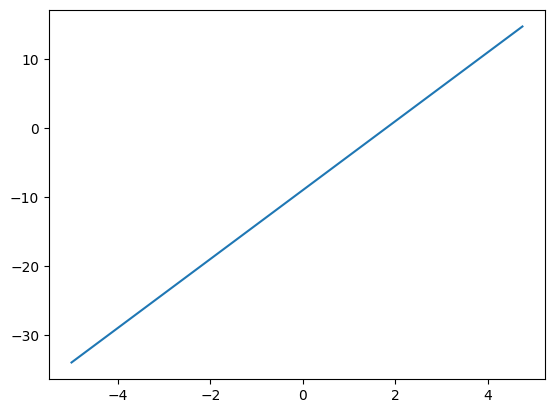
¿Qué significa esto para una función, digamos f(x) = 5x - 9?
f'(x)=5es decir, la función f(x)aumenta en un factor de 5 por 1 unidad de cambio en x. También podemos calcular este valor empujando x por un valor infinitesimal hy observar cómo f(x)cambia. es decirf(x) = 5x – 9
f(x+h) = 5 (x+h) – 9
f`(x) = (f(x+h) – f(x))/(x+h – x) = 5 –>
Esto también se conoce como aumento sobre la marcha.
Funciones multivariadas
Para funciones multivariadas como d = a*b + c, la tasa de cambio es diferente para diferentes variables.def f ( x ):
devuelve 5 *x – 9
xs = np.arange(- 5 , 5 , 0.25 )
ys = f(xs)
plt.plot(xs, ys)[<matplotlib.lines.Line2D en 0x130c99290 >]
Implementación de un valor en la red neuronal
Pytorch utiliza Tensorspara el cálculo, para replicar la funcionalidad, escribiremos nuestra propia implementación.Value valor de clase :
def __init__ ( self, data, label= » ):
self.data = data
self.label = label
self.grad = 0.0 # Repasaremos este campo en detalle más adelante
def __repr__ ( self ):
return f»Valor=(datos= {self.data} , etiqueta= {self.label} )»»’
Hagamos uso de una ecuación multivariada y escribámosla usando la clase Valor definida anteriormente
a = 2.0
b = -3.0
c = 10.0
e = a * b
d = e + c
f = -2.0
l = d * f
»’
a = Valor( 2.0 , etiqueta= ‘a’ )
b = Valor(- 3.0 , etiqueta= ‘b’ )
c = Valor( 10.0 , etiqueta= ‘c’ )
e = a*b————————————————– ————————-
TypeError Traceback (última llamada más reciente)
Celda en [ 92 ], línea 14
12 b = Valor (- 3.0 , etiqueta = ‘b’ )
13 c = Valor( 10.0 , etiqueta= ‘c’ )
—> 14 e = a*b
TypeError: tipos de operandos no admitidos para *: ‘Valor’ y ‘Valor’
El error anterior muestra que * no está definido para el tipo Valor. Necesitaremos modificar el tipo de Valor para admitir operaciones + y *.
También agregaremos un campo de operación que muestra cómo se creó el Valor. Como estamos trabajando con una red neuronal, necesitaremos realizar un seguimiento de los hijos de un nodo. Entonces agregaremos un campo _prev al tipo de valor. valor de clase :
def __init__ ( self, datos, _children=( ), _op= » , etiqueta= » ):
self.data = datos
self.label = etiqueta
self._op = _op
self._prev = set (_children)
self .grad = 0
def __repr__ ( self ):
retorno f»Valor=(datos= {self.data} , etiqueta= {self.label} )»
def __add__ ( self, otro ):
out = Valor(self.data + otro .data, (self, other), ‘ +’ )
devuelve def
__mul__ ( self, other ) : out = Valor(self.data * other.data, (self, other), ‘*’ ) devuelve
a = Valor ( 2.0 , etiqueta = ‘a’ )
b = Valor (- 3.0 , etiqueta = ‘b’ )
c = Valor ( 10.0 , etiqueta = ‘c’ )
e = a*b; e.label = ‘e’
d = e + c; d.label = ‘d’
f = Valor(- 2.0 , etiqueta = ‘f’ )
L = d * f; L.etiqueta = ‘L’
LValor=(datos=- 8.0 , etiqueta=L)
Para visualizar la red, usaremos graphviz. El siguiente código tiene referencia directa desde https://github.com/karpathy/nn-zero-to-hero/blob/master/lectures/micrograd.from graphviz import Digraph
def trace ( root ):
# construye un conjunto de todos los nodos y bordes en los
nodos de un gráfico, bordes = set (), set ()
def build ( v ):
si v no está en los nodos:
nodes.add(v) )
para niño en v._prev:
bordes.add((niño, v))
build(niño)
construir(raíz) nodos
de retorno , bordes
def draw_dot ( raíz ):
punto = Digraph( formato = ‘png’ , graph_attr={ ‘ rankdir’ : ‘LR’ }) # LR = nodos de izquierda a derecha , bordes = trace(root) para n en nodos: uid = str ( id (n)) # para cualquier valor en el gráfico, crea un registro rectangular (‘ ‘) nodo para ello dot.node(nombre = uid, etiqueta = «{ %s | datos %.4f | grad %.4f }» % (n.label, n.data, n.grad), forma = ‘registro ‘ ) if n._op: # si este valor es el resultado de alguna operación, cree un nodo de operación para él dot.node(name = uid + n._op, label = n._op) # y conecte este nodo a él dot .edge(uid + n._op, uid) para n1, n2 en bordes: # conecta n1 al nodo op de n2 dot.edge( str ( id (n1)), str ( id (n2)) + n2._op ) punto de retorno
»’
Trazar la variable L para diseñar la red. Los nodos _op simplemente se representan para mostrar la relación padre/hijo entre los nodos
»’
draw_dot(L)

Derivadas/Gradiente
Calcular manualmente el gradiente, retrocediendo desde L, que es el caso base con un gradiente de 1,0L.grad = 1.0 # Caso base como tasa de cambio de L wrt a L es 1
»’
Sabemos que L = d*f
entonces dL/df (gradiente de L wrt a f o tasa de cambio de L wrt a f ) = d
de manera similar, dL/dd será f
»’
d.grad = f.data
f.grad = d.data
»’
Dado que d = e + c, para averiguar dL/de (tasa de cambio de L wrt a e) haremos uso de la regla de la cadena, es decir,
dL/de = (dL/dd) * (dd/de) = (dL/dd) * 1,0
de manera similar dL/dc = dL/dd * 1,0
»’
e .grad = d.grad
c.grad = d.grad
»’
e = a * b
Entonces, siguiendo la regla de la cadena nuevamente
dL/da = (dL/de) * (de/da) = (dL/de) * b
dL/db = (dL/de) * (de/db) = (dL/de) * a
»’
a.grad = e.grad * b.data
b.grad = e.grad * a.data»’
Trazar la variable L para diseñar la red.
»’
dibujar_punto(L)

Del diagrama anterior, podemos hacer una observación simple de que +los nodos transfieren gradientes del nodo secundario a los nodos principales; por ejemplo, el gradiente de ey ces el mismo que el de d. Ahora que hemos establecido los conceptos de gradientes. Avancemos hacia la expresión que representa una Neurona.# entradas x1,x2
x1 = Valor( 2.0 , etiqueta= ‘x1’ )
x2 = Valor( 0.0 , etiqueta= ‘x2’ )
# pesos w1,w2
w1 = Valor(- 3.0 , etiqueta= ‘w1’ )
w2 = Valor ( 1.0 , etiqueta = ‘w2’ )
# sesgo de la neurona
b = Valor ( 6 , etiqueta = ‘b’ )
# x1*w1 + x2*w2 + b
x1w1 = x1*w1; x1w1.label = ‘x1*w1’
x2w2 = x2*w2; x2w2.label = ‘x2*w2’
x1w1x2w2 = x1w1 + x2w2; x1w1x2w2.label = ‘x1*w1 + x2*w2’
n = x1w1x2w2 + b; n.etiqueta = ‘n’dibujar_punto(n)

Función de activación
Las neuronas también utilizan algo llamado función de activación. Las funciones de activación introducen no linealidad en la red neuronal, lo que le permite modelar relaciones complejas y aprender de los datos. A los efectos de este artículo, la utilizaremos tanhcomo función de activación. La función tanh aplasta la entrada neta, pero la asigna a un rango entre -1 y 1. A menudo se usa en capas ocultas de redes neuronales.plt.plot(np.arange(- 5 , 5 , 0.2 ), np.tanh(np.arange(- 5 , 5 , 0.2 ))); plt.grid();

»’
Pasaremos n a través de una función de activación tanh pero antes de eso necesitaremos agregar tanh al tipo Valor ya que tanh no entiende el tipo Valor.
»’
def tanh ( self ):
x = self.data
t = (math.exp( 2 *x) – 1 )/(math.exp( 2 *x) + 1 )
out = Valor(t, (self, ), ‘tanh’ )
devuelve # Adjunte
el método de instancia a la clase
Value.tanh = tanh
o = n.tanh(); o.label = ‘o’
dibujar_punto (o)

Propagación hacia atrás
Para calcular el gradiente de cada nodo, será una locura hacerlo manualmente a medida que crece el tamaño de la red. Nos gustaría crear un método _backwardque haga eso para cada nodo. Dado que calcular el gradiente requiere diferenciar la función, tendríamos que implementarlo en el _backwardmétodo. Así es como se vería para cada operación en Tipo de valor
addmétodo
def _backward ():
self.grad += 1.0 * out.grad
otro.grad += 1.0 * out.grad
mulmétodo
def _backward ():
self.grad += otros.datos * out.grad
otros.grad += self.data * out.grad
tanhmétodo
def _backward ():
self.grad += ( 1 – t** 2 ) * out.grad»’
Actualizando valor para incluir la función _backward para cada método de operación
»’ valor
de clase : def __init__ ( self, data, _children=( ), _op= » , label= » ): self.data = data self.grad = 0.0 self._backward = lambda : Ninguno self._prev = set (_children) self._op = _op self.label = etiqueta def __repr__ ( self ): devuelve f»Valor(datos= {self.data} )» def __add__ ( self, other ): out = Valor(self.data + other.data, (self, other), ‘+’ ) def _backward (): self.grad += 1.0 * out.grad other.grad += 1.0 * out .grad out._backward = _backward return out def __mul__ ( self, otro ): out = Valor(self.data * other.data, (self, otro), ‘*’ ) def _backward (): self.grad += otro .data * out.grad other.grad += self.data * out.grad out._backward = _backward return out def tanh ( self ): x = self.data t = (math.exp( 2 *x) – 1 ) /(math.exp( 2 *x) + 1 ) out = Valor(t, (self, ), ‘tanh’ ) def _backward (): self.grad += ( 1 – t** 2 ) * out.grad out._backward = _backward regresar fuera
»’Reinicializando los valores para reflejar nuevas propiedades de clase »’
# entradas x1,x2
x1 = Valor( 2.0 , etiqueta= ‘x1’ )
x2 = Valor( 0.0 , etiqueta= ‘x2’ )
# pesos w1,w2
w1 = Valor(- 3.0 , etiqueta= ‘w1’ )
w2 = Valor( 1.0 , etiqueta= ‘w2’ )
# sesgo de la neurona
b = Valor( 6 , etiqueta= ‘b’ )
# x1*w1 + x2*w2 + b
x1w1 = x1*w1; x1w1.label = ‘x1*w1’
x2w2 = x2*w2; x2w2.label = ‘x2*w2’
x1w1x2w2 = x1w1 + x2w2; x1w1x2w2.label = ‘x1*w1 + x2*w2’
n = x1w1x2w2 + b; n.label = ‘n’
o = n.tanh(); o.label = ‘o’dibujar_punto (o)

o.grad = 1.0 # caso base
»’
Llamar hacia atrás en o cambiará el gradiente de n
»’
o._backward()
»’
Llamar hacia atrás en n cambiará el gradiente de x1w1 + x2w2 y b nodos
»’
n. _backward()
»’
Llamar hacia atrás a x1w1x2w2 cambiará el gradiente de x2w2 y x1w1
»’
x1w1x2w2._backward()
draw_dot(o)
»’
Llamar hacia atrás a x1w1 y x1w1 cambiará el gradiente de x1, x2, w1 y w2
‘ »
x1w1._backward()
x2w2._backward()
dibujar_punto(o)

Una mejor manera de hacer esto sería tener un método que ejecute métodos hacia atrás para todos los niños a partir del nodo actual.
Esto requeriría obtener el orden de los nodos de modo que el nodo actual sea el primero y todos sus hijos se procesen después. Esto es lo que nos proporciona el tipo topológico.topo = []
visitado = set ()
def build_topo ( v ):
si v no está visitado:
visitado.add(v)
para niño en v._prev:
build_topo(child)
topo.append(v)
build_topo(o)
topo[Valor ( datos = 1,0 ),
Valor ( datos = 0,0 ),
Valor ( datos = 0,0 ),
Valor ( datos = – 3,0 ),
Valor ( datos = 2,0 ),
Valor ( datos = – 6,0 ),
Valor ( datos = – 6.0 ),
Valor ( datos = 6 ),
Valor ( datos = 0.0 ),
Valor ( datos = 0.0 )]
Usando el enfoque anterior, podemos escribir un método en la clase Value, ese método de clase _backward para cada uno de los hijos de una clase.def hacia atrás ( self ):
topo = []
visitado = set ()
def build_topo ( v ):
si v no está visitado:
visitado.add(v)
para niño en v._prev:
build_topo(niño)
topo.append(v)
build_topo(self)
self.grad = 1.0 # Replicando el caso base
para el nodo en reverso (topo):
node._backward()
# Adjunte el método de instancia a la clase
Value.backward = backward»’Reinicializando los valores para reflejar nuevas propiedades de clase »’
# entradas x1,x2
x1 = Valor( 2.0 , etiqueta= ‘x1’ )
x2 = Valor( 0.0 , etiqueta= ‘x2’ )
# pesos w1,w2
w1 = Valor(- 3.0 , etiqueta= ‘w1’ )
w2 = Valor( 1.0 , etiqueta= ‘w2’ )
# sesgo de la neurona
b = Valor( 6 , etiqueta= ‘b’ )
# x1*w1 + x2*w2 + b
x1w1 = x1*w1; x1w1.label = ‘x1*w1’
x2w2 = x2*w2; x2w2.label = ‘x2*w2’
x1w1x2w2 = x1w1 + x2w2; x1w1x2w2.label = ‘x1*w1 + x2*w2’
n = x1w1x2w2 + b; n.label = ‘n’
o = n.tanh(); o.label = ‘o’
o.hacia atrás()
draw_dot(o)

Podemos verificar nuestra implementación usando la biblioteca PyTorch.importar antorcha
x1 = torch.Tensor([ 2.0 ]).double() ; x1.requires_grad = True # require_grad fuerza el uso del tensor en los cálculos de gradientes
x2 = torch.Tensor([ 0.0 ]).double() ; x2.requires_grad = Verdadero
w1 = torch.Tensor([- 3.0 ]).double() ; w1.requires_grad = Verdadero
w2 = torch.Tensor([ 1.0 ]).double() ; w2.requires_grad = Verdadero
b = torch.Tensor([ 6 ]).double() ; b.requires_grad = True
n = x1*w1 + x2*w2 + b
o = torch.tanh(n)
print (o.data.item())
o.backward()
print ( ‘—‘ )
print ( ‘ x2’ , x2.grad.item())
imprimir ( ‘w2’ , w2.grad.item())
imprimir ( ‘x1’ , x1.grad.item())
imprimir ( ‘w1’ , w1.grad.item ())0,0
—
x2 1,0
w2 0,0
x1 -3,0
w1 2,0
Codificando una red neuronal
En las secciones anteriores, hemos creado una clase Valor que nos permite crear ecuaciones multivariadas y el uso de retropropagación nos permite calcular gradientes. Para crear una red neuronal, crearíamos las siguientes clases que utilizarían la clase Valor:
Neuron– Representa una sola neurona en la red.Layer– Representar una sola capa en la red neuronal que contendría múltiplesNeuronsMLP– Representa un perceptrón multicapa o una red neuronal con múltiplesLayers deNeurons
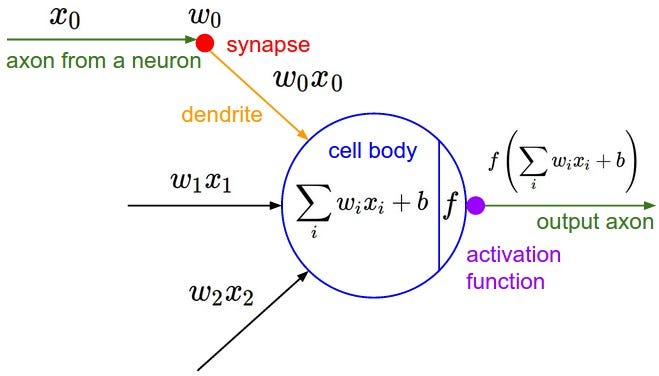
El diagrama anterior muestra la estructura de una neurona con pesos (Wi), polarización (b) y entrada (xi) como inputsy una única salida pasada a través de una función de activación tanhen nuestro caso.
La suma ponderada se calcula de la siguiente manera: weighted_sum = (w1 * x1) + (w2 * x2) + ... + (wn * xn)Donde:
w1, w2, ..., wn: Estos son los pesos asociados con cada entrada.x1, x2, ..., xn: Estos son los valores de entrada.
Implementación de neurona
importar
clase aleatoria Neurona :
def __init__ ( self, ninp ):
self.w = [Valor(random.uniform(- 1 , 1 )) para _ en el rango (ninp)]
self.b = Valor(random.uniform(- 1 , 1 ))
def __call__ ( self, x ):
out = sum ([ wi*xi for wi, xi in zip (self.w, x)]) + self.b
res = out.tanh()
return res parámetros
def ( self ): # Esta función se usaría más adelante mientras se entrena la red return self.w + [self.b]
x = [1.0, 2.0, 3.0 ]
n = Neurona(3)
n(x)————————————————– ————————-
AttributeError Traceback (última llamada más reciente)
Celda en [ 123 ], línea 3
1 x = [ 1.0 , 2.0 , 3.0 ]
2 n = Neurona( 3 )
—-> 3 n(x)
Celda En[ 122 ], línea 8 , en Neurona.__call__( self , x)
7 def __call__ ( self , x ):
—-> 8 out = sum([ wi*xi for wi, xi in zip( self .w, x)]) + self .b
9 res = out.tanh()
10 return res
Cell In[ 122 ], línea 8 , in < listcomp>(. 0 )
7 def __call__ ( self , x ):
—-> 8 out = suma([ wi*xi para wi, xi in zip( self .w, x)]) + self .b
9 res = out.tanh()
10 return res
Cell In[ 105 ], línea 29 , in Value.__mul__( self , other)
28 def __mul__ ( self , other ):
—> 29 out = Value( self .data * other .data, ( self , other), ‘*’ )
31 def _backward ():
32 self .grad += other.data * out.grad
AttributeError: el objeto ‘flotante’ no tiene el atributo ‘datos’
El error anterior es el resultado de multiplicar el tipo Valor con un tipo flotante. Para admitir dichas operaciones, modificaremos Valor con algunos métodos más. Valor de clase :
def __init__ ( self, data, _children=( ), _op= » , label= » ):
self.data = datos
self.grad = 0.0
self._backward = lambda : Ninguno
self._prev = set (_children )
self._op = _op
self.label = etiqueta
def __repr__ ( self ):
return f»Value(data= {self.data} )»
def __add__ ( self, other ):
other = other if isinstance (other, Value) else Valor(otro)
salida = Valor(self.data + other.data, (self, other), ‘+’ )
def _backward ():
self.grad += 1.0 * out.grad
other.grad += 1.0 * out. grad
out._backward = _backward
return out
def __mul__ ( self, otro ):
otro = otro if isinstance (otro, Valor) else Valor(otro)
out = Valor(self.data * other.data, (self, otro), ‘ *’ )
def _backward ():
self.grad += other.data * out.grad
other.grad += self.data * out.grad
out._backward = _backward
return out
def __pow__ ( self, otro ):
afirmar isinstance ( other, ( int , float )), «solo admite poderes int/float por ahora»
out = Value(self.data**other, (self,), f’** {other} ‘ )
def _backward ():
self .grad += otro * (self.data ** (otro – 1 )) * out.grad
out._backward = _backward
return out
def __rmul__ ( self, otro ): # otro * self
return self * otro
def __truediv__ ( self, otro ): # yo / otro
regresa yo * otro**- 1
def __neg__ ( yo ): # -yo
regresa yo * – 1
def __sub__ ( self, otro ): # self – otro
regresa self + (-other)
def __radd__ ( self, other ): # otro + self
regresa self + otro
def tanh ( self ):
x = self.data
t = (matemáticas .exp( 2 *x) – 1 )/(math.exp( 2 *x) + 1 )
out = Valor(t, (self, ), ‘tanh’ )
def _backward ():
self.grad += ( 1 – t** 2 ) * out.grad
out._backward = _backward
return out
def exp ( self ):
x = self.data
out = Valor(math.exp(x), (self, ), ‘exp’ )
def _backward ():
self.grad += out.data * out.grad
out._backward = _backward
return out
def atrás ( self ):
topo = []
visitado = set ()
def build_topo ( v ):
si v no está visitado:
visitado .add(v)
para niño en v._prev:
build_topo(child)
topo.append(v)
build_topo(self)
self.grad = 1.0
para nodo en invertido (topo):
node._backward()»’
Probando la operación anterior nuevamente
»’
x = [ 1.0 , 2.0 , 3.0 ]
n = Neuron( 3 )
n(x)Valor (datos=- 0,5181071586116809 )
A continuación, definiremos una capa en la red neuronal.
capa de clase :
def __init__ ( self, ninp, nneurons ): # ninp es el número de entradas para cada neurona en la capa
self.neurons = [Neuron(ninp) for _ in range (nneurons)]
def __call__ ( self, x ) :
outs = [n(x) para n en self.neurons]
devuelve outs[ 0 ] si len (outs) == 1 else outs
def parámetros ( self ):
devuelve [p para neurona en self.neurons para p en neurona. parámetros()]»’
La entrada x pasa a través de cada neurona de la capa l, por lo tanto, salen 4 valores de la capa
»’
x = [ 1.0 , 2.0 , 3.0 ]
l = Layer( 3 , 4 )
l(x)[Valor ( datos = 0,971182517031463 ),
Valor ( datos = – 0,9790568300306317 ),
Valor ( datos = – 0,4857385699176223 ),
Valor ( datos = – 0,9636928832453497 )]
A continuación, definiremos una clase MLP que es nuestra red neuronal.
clase MLP :
def __init__ ( self, nin, nouts ): # nin es el número de entradas para la primera capa y nouts es un [] para la salida en cada capa
sz = [nin] + nouts
self.layers = [Layer(sz [i], sz[i+ 1 ]) para i en el rango ( len (nouts))]
def __call__ ( self, x ):
para capa en self.layers:
x = capa(x)
devuelve x parámetros
def ( self ): devolver [p para capa en self.layers para p en capa.parameters()]
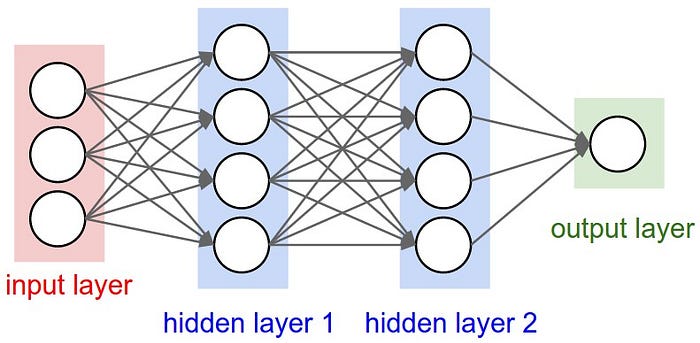
En el ejemplo creamos el siguiente MPL
- Primera capa: 3 entradas
- Capas intermedias: 4 y 4 salidas
- Capa de salida: 1
x = [ 2.0 , 3.0 , – 1.0 ]
n = MLP( 3 , [ 4 , 4 , 1 ])
n(x)Valor (datos=- 0,3286322706370602 )
Creando un clasificador binario
Para las x como entradas, tenemos un objetivo ys, que son las predicciones verdaderas. Crearemos un MLP con la misma estructura que vimos arriba.xs = [
[ 2.0 , 3.0 , – 1.0 ],
[ 3.0 , – 1.0 , 0.5 ],
[ 0.5 , 1.0 , 1.0 ],
[ 1.0 , 1.0 , – 1.0 ],
]
ys = [ 1.0 , – 1.0 , – 1.0 , 1.0 ] # objetivos deseados
n = MLP( 3 , [ 4 , 4 , 1 ])»’
Cada x en xs se pasaría a MLP, lo que daría como resultado ypred, esto se denomina paso directo
»’
ypred = [n(x) para x en xs]
ypred[Valor ( datos =- 0,9605353699041816 ),
Valor ( datos =- 0,9652866142967272 ),
Valor ( datos = 0,26960003457444665 ),
Valor ( datos =- 0,9511958636250315 )]
Pérdida
Vemos arriba que ypredies diferente a yi. La diferencia entre los valores se denomina loss. Podemos utilizar diferentes métodos para calcular loss. En este ejemplo, haremos uso deSquared errorpérdida = suma ((yout – ygt)** 2 para ygt, yout en zip (ys, ypred))
pérdidaValor (datos= 9.26395350181118 )draw_dot (pérdida)

Una vez que hayamos calculado el gradiente correspondiente a cada parámetro del MLP, modificaremos el valor de cada parámetro por un pequeño valor también conocido como tasa de aprendizaje.para p en n.parameters():
p.data += – 0.1 * p.grad
Después de actualizar los valores, podemos verificar la pérdida nuevamente; esta pérdida de tiempo debe reducirseypred = [n(x) para x en xs]
pérdida = suma ((yout – ygt)** 2 para ygt, yout en zip (ys, ypred))
pérdidaValor (datos= 7,829761457067251 )
Bucle de entrenamiento
Podemos tener los pasos anteriores en un ciclo de entrenamiento.
- Pase adelantado
- pase hacia atrás
- Actualizar
»’
Restableciendo los valores
»’
xs = [
[ 2.0 , 3.0 , – 1.0 ],
[ 3.0 , – 1.0 , 0.5 ],
[ 0.5 , 1.0 , 1.0 ],
[ 1.0 , 1.0 , – 1.0 ],
]
ys = [ 1.0 , – 1.0 , – 1.0 , 1.0 ] # objetivos deseados
n = MLP( 3 , [ 4 , 4 , 1 ])para k en rango ( 50 ):
# pase hacia adelante
ypred = [ n (x) para x en xs]
pérdida = suma ((yout – ygt)** 2 para ygt, yout en zip (ys, ypred))
# pase hacia atrás
para p en n. parámetros ():
p.grad = 0.0
pérdida. hacia atrás ()
# actualización
para p en n. parámetros ():
p.data += – 0.1 * p.grad
print (k, loss.data)0 3.6406853121192033
1 3.610944134843126
2 3.741912394115651
3 3.2018009544051136
4 3.2524598245980503
5 1.9728216636593452
6 1.3173214047883315
7 1.0735765629752656
8 0.8890437353493715
9 0.11522009736067115
10 0.05081752438719958
11 0.03672318278028023
12 0.02979416308450841
13 0.02556184631434586
14 0.022653024581680118
15 0.02049638823502594
16 0.01881087828912575
17 0.017442066784978914
18 0.01629801693027828
19 0.015320499407445488
20 0.014470748984735923
21 0.013721869837929553
22 0.013054538143998672
23 0.012454448840696034
24 0.01191073501042354
25 0.011414954174232338
26 0.010960417756148979
27 0.010541735226885831
28 0.010154496500154066
29 0.009795045700014122
30 0.009460316742793573
31 0.009147711635699132
32 0.008855008873882249
33 0.008580293427428378
34 0.008321902472546286
35 0.00807838278062741
36 0.007848456862487212
37 0.007630995774834821
38 0.007424997058651014
39 0.007229566675831996
40 0.007043904093967112
41 0.006867289874369098
42 0.006699075268871989
43 0.00653867344237842
44 0.0063855520216464234
45 0.00623922673400612
46 0.006099255947992355
47 0.005965235965120223
48 0.005836796940995997
49 0.0057135993366707865
Inferencia
xs = [
[ 4.0 , 5.0 , – 3.0 ],
]
ypred = [n(x) para x en xs]
ypred[ Valor(datos=0,9658818961790056) ]
Conclusión
Ahí lo tiene, una red neuronal funcional que puede aprender los datos de entrada y optimizar sus pesos mediante el descenso de gradiente. Este artículo fue una simplificación excesiva de las redes neuronales reales, pero, aun así, cubre las operaciones que se llevan a cabo, menos las optimizaciones.
Espero que a través de este artículo haya podido mejorar su comprensión de las redes neuronales y profundizar en el funcionamiento de componentes con los que quizás ya esté familiarizado.


