

Marcos Riedl IA para narración de historias, juegos, explicabilidad, seguridad, ética. Profesor @GeorgiaTech. Director Asociado @MLatGT . Experto en viajes en el tiempo.
Introducción
Este artículo está diseñado para brindar a las personas sin experiencia en informática una idea de cómo funcionan ChatGPT y sistemas de IA similares (GPT-3, GPT-4, Bing Chat, Bard, etc.). ChatGPT es un chatbot, un tipo de IA conversacional construida, pero sobre un modelo de lenguaje grande . Esas son definitivamente palabras y desglosaremos todo eso. En el proceso, discutiremos los conceptos básicos detrás de ellos. Este artículo no requiere ningún conocimiento técnico o matemático. Haremos un uso intensivo de metáforas para ilustrar los conceptos. Hablaremos sobre por qué los conceptos básicos funcionan de la manera en que funcionan y qué podemos esperar o no esperar que hagan los modelos de lenguaje grande como ChatGPT.
Esto es lo que vamos a hacer. Vamos a repasar suavemente parte de la terminología asociada con modelos de lenguaje grande y ChatGPT sin ninguna jerga. Si tengo que usar jerga, lo desglosaré sin jerga. Comenzaremos de manera muy básica, con «qué es la inteligencia artificial» y avanzaremos. Usaré algunas metáforas recurrentes tanto como sea posible. Hablaré sobre las implicaciones de las tecnologías en términos de lo que deberíamos esperar que hicieran o no deberíamos esperar que hicieran.
¡Vamos!
¿Qué es la Inteligencia Artificial?
Pero primero, comencemos con una terminología básica que probablemente esté escuchando mucho. ¿Qué es la inteligencia artificial ?
- Inteligencia artificial : una entidad que realiza comportamientos que una persona podría razonablemente llamar inteligente si un ser humano hiciera algo similar.
Es un poco problemático definir la inteligencia artificial usando la palabra «inteligente», pero nadie puede ponerse de acuerdo sobre una buena definición de «inteligente». Sin embargo, creo que esto todavía funciona razonablemente bien. Básicamente dice que si miramos algo artificial y hace cosas que son atractivas y útiles y parecen no ser triviales, entonces podríamos llamarlo inteligente. Por ejemplo, a menudo atribuimos el término «IA» a los personajes controlados por computadora en los juegos de computadora. La mayoría de estos bots son piezas simples de código if-then-else (p. ej., «si el jugador está dentro del alcance, dispara, de lo contrario, muévete a la roca más cercana para cubrirte»). Pero si estamos haciendo el trabajo de mantenernos comprometidos y entretenidos, y no estamos haciendo cosas obviamente estúpidas, entonces podríamos pensar que son más sofisticados de lo que son.
Una vez que entendemos cómo funciona algo, es posible que no quedemos muy impresionados y esperemos algo más sofisticado entre bastidores. Todo depende de lo que sepas sobre lo que sucede detrás de escena.
El punto clave es que la inteligencia artificial no es magia. Y como no es magia, se puede explicar.
2. ¿Qué es el aprendizaje automático?
Otro término que escuchará a menudo asociado con la inteligencia artificial es aprendizaje automático .
- Aprendizaje automático : un medio por el cual crear comportamiento tomando datos, formando un modelo y luego ejecutando el modelo.
A veces es demasiado difícil crear manualmente un montón de declaraciones if-then-else para capturar algún fenómeno complicado, como el lenguaje. En este caso, tratamos de encontrar un montón de datos y usar algoritmos que puedan encontrar patrones en los datos para modelar.
Pero, ¿qué es un modelo? Un modelo es una simplificación de algún fenómeno complejo. Por ejemplo, un modelo de automóvil es solo una versión más pequeña y simple de un automóvil real que tiene muchos de los atributos pero no pretende reemplazar completamente al original. Un modelo de auto puede parecer real y ser útil para ciertos propósitos, pero no podemos llevarlo a la tienda.

Así como podemos hacer una versión más pequeña y simple de un automóvil, también podemos hacer una versión más pequeña y simple del lenguaje humano. Usamos el término modelos de lenguaje grande porque estos modelos son, bueno, grandes, desde la perspectiva de cuánta memoria se requiere para usarlos. Los modelos más grandes en producción, como ChatGPT, GPT-3 y GPT-4, son lo suficientemente grandes como para requerir supercomputadoras masivas que se ejecutan en servidores de centros de datos para crear y ejecutar.
3. ¿Qué es una Red Neuronal?
Hay muchas formas de aprender un modelo a partir de los datos. La red neuronal es una de esas formas. La técnica se basa aproximadamente en cómo el cerebro humano se compone de una red de células cerebrales interconectadas llamadas neuronas que transmiten señales eléctricas de un lado a otro, permitiéndonos de alguna manera hacer todas las cosas que hacemos. El concepto básico de la red neuronal se inventó en la década de 1940 y los conceptos básicos sobre cómo entrenarlos se inventaron en la década de 1980. Las redes neuronales son muy ineficientes y no fue hasta alrededor de 2017 cuando el hardware de la computadora fue lo suficientemente bueno para usarlas a gran escala.
Pero en lugar de cerebros, me gusta pensar en redes neuronales utilizando la metáfora de los circuitos eléctricos. No es necesario ser ingeniero eléctrico para saber que la electricidad fluye a través de los cables y que tenemos cosas llamadas resistencias que dificultan que la electricidad fluya a través de partes de un circuito.
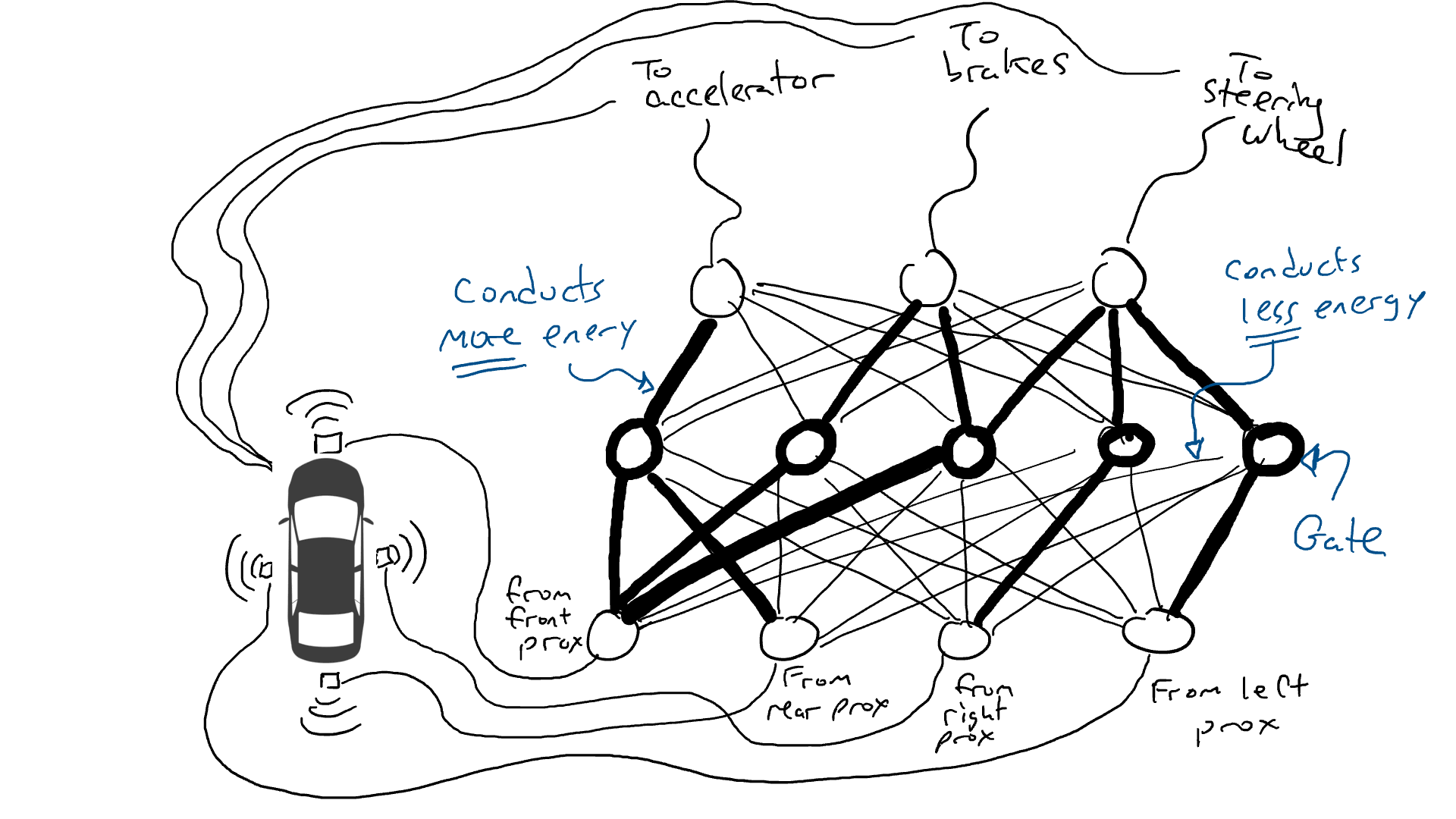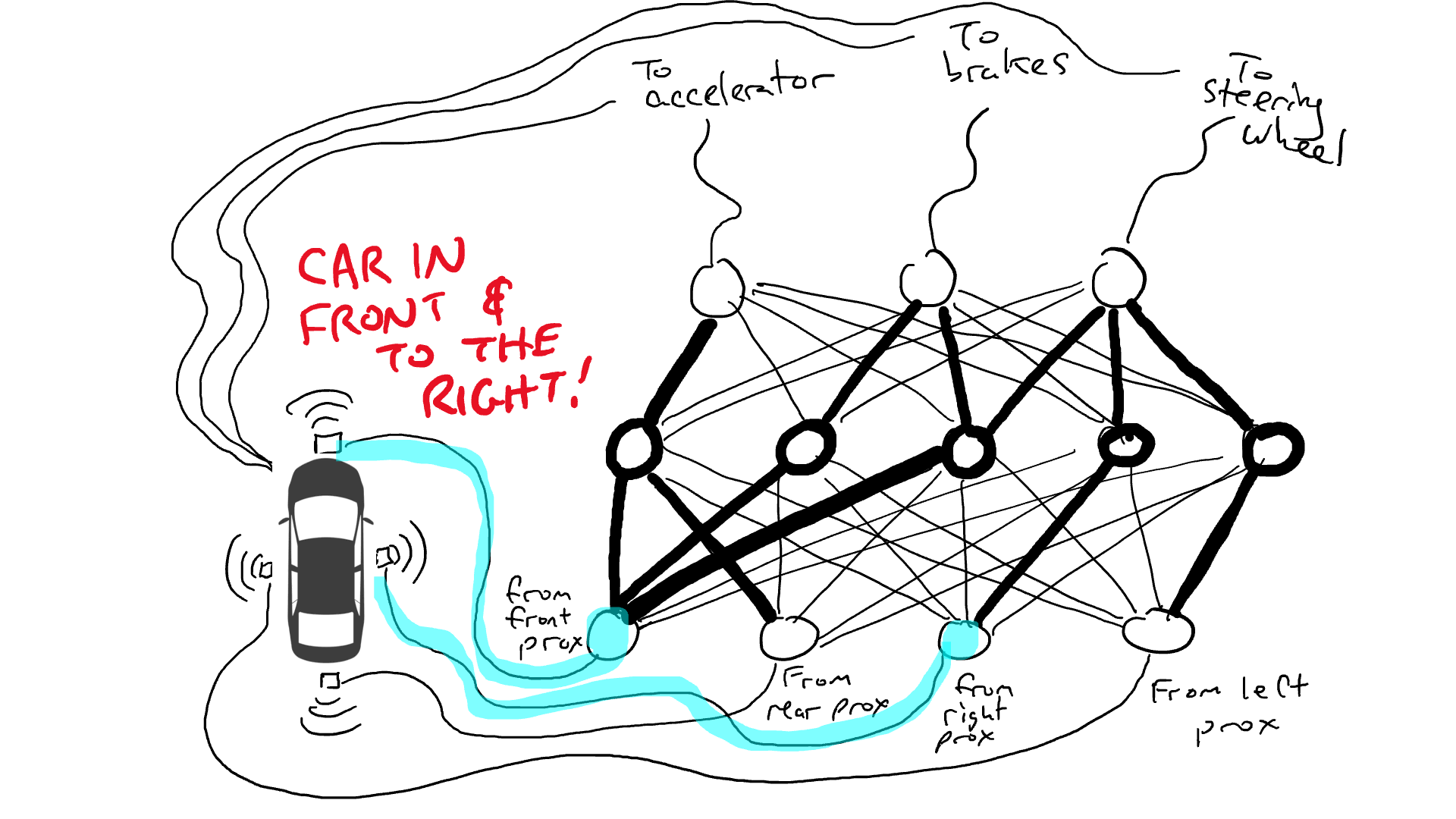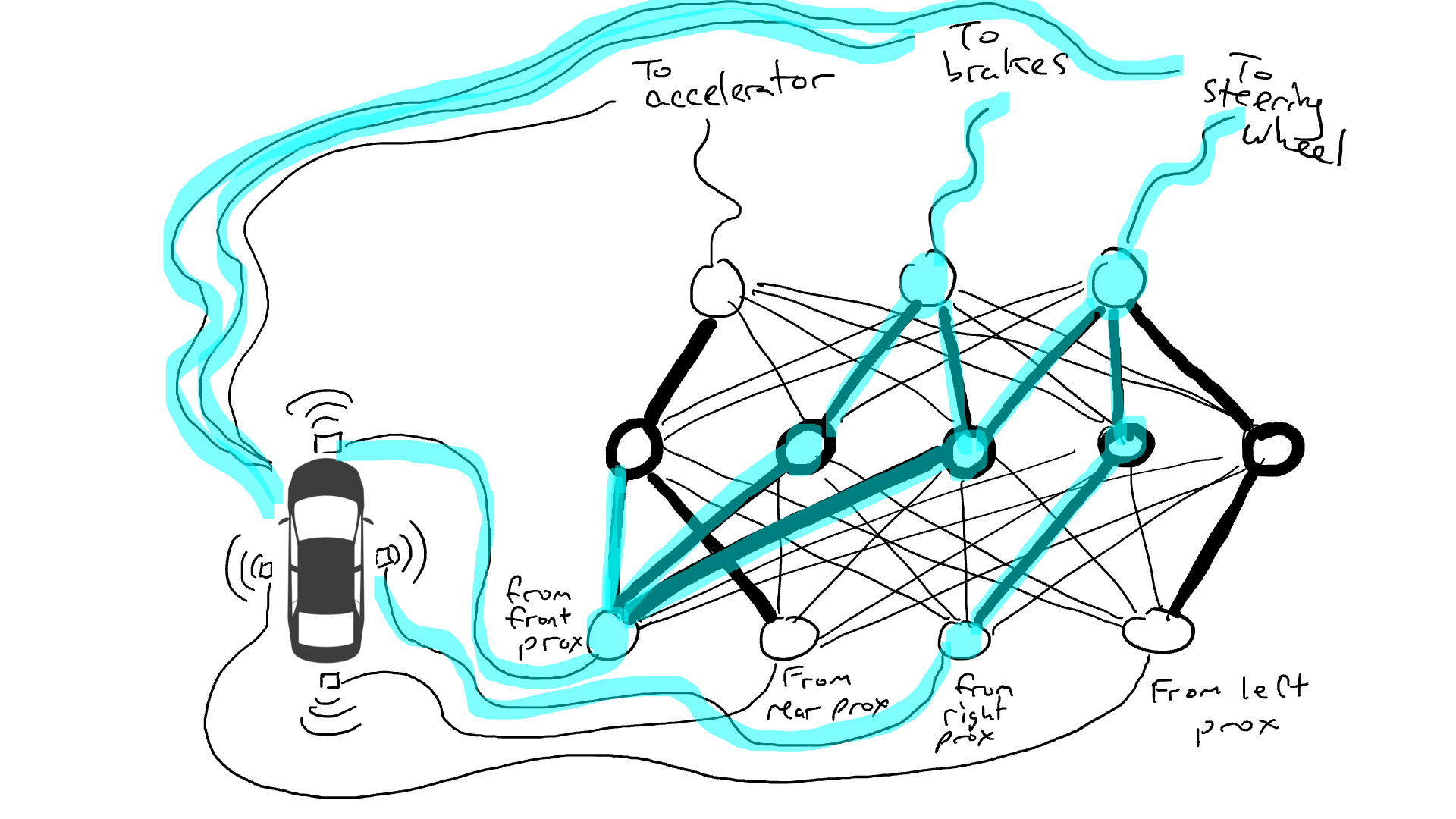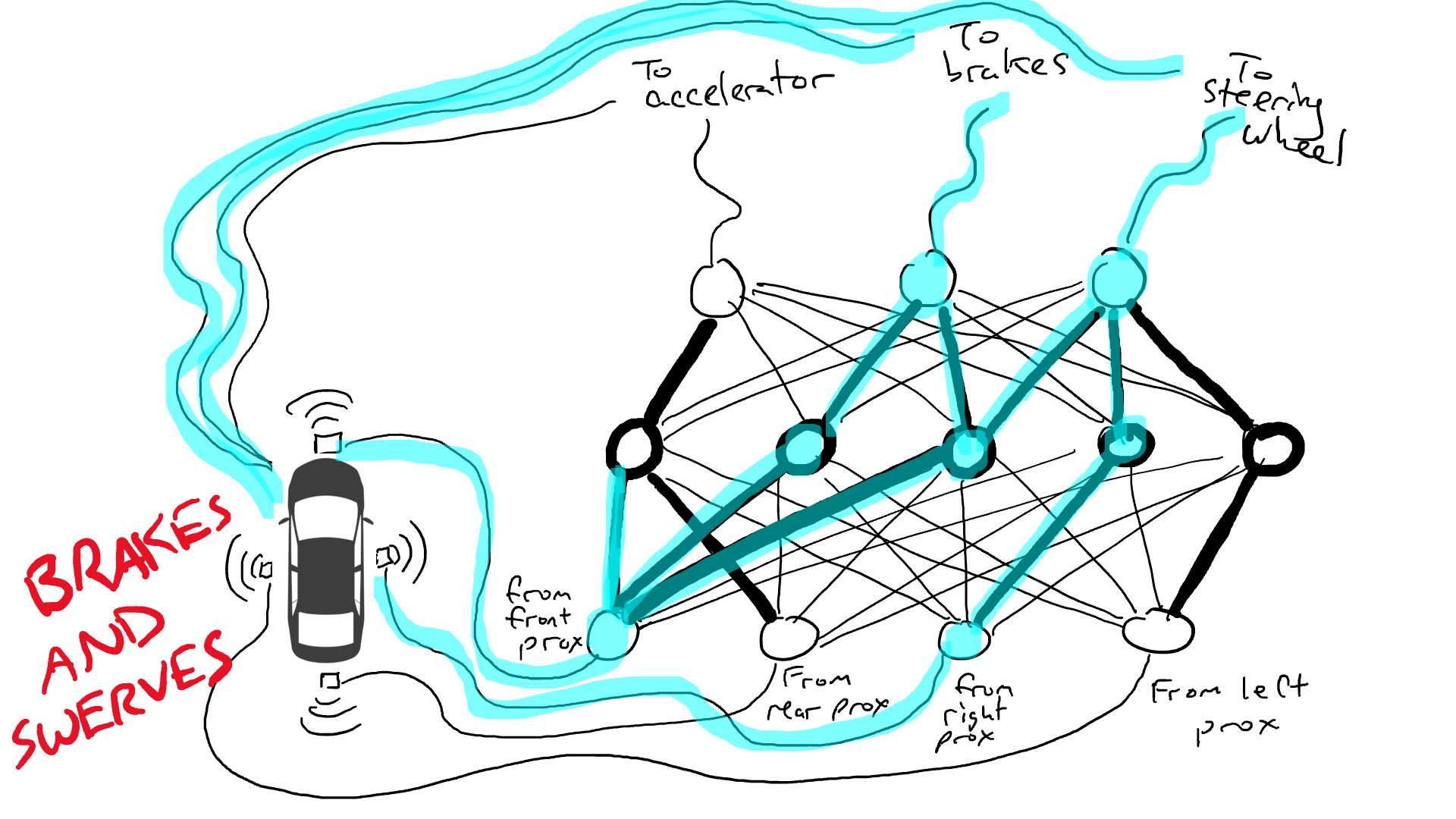
Imagina que quieres hacer un coche autónomo que pueda circular por la autopista. Ha equipado su automóvil con sensores de proximidad en la parte delantera, trasera y laterales. Los sensores de proximidad informan un valor de 1,0 cuando hay algo muy cerca y un valor de 0,0 cuando no se detecta nada cerca.
También ha manipulado su automóvil para que los mecanismos robóticos puedan girar el volante, presionar los frenos y presionar el acelerador. Cuando el acelerador recibe un valor de 1,0, utiliza la aceleración máxima y 0,0 significa que no hay aceleración. De manera similar, un valor de 1,0 enviado al mecanismo de frenado significa que los frenos se pisan bruscamente y 0,0 significa que no se frena. El mecanismo de dirección toma un valor de -1,0 a +1,0 con un valor negativo que significa girar a la izquierda y un valor positivo que significa girar a la derecha y 0,0 que significa mantenerse recto.
También ha registrado datos sobre cómo conduce. Cuando el camino de enfrente está despejado, aceleras. Cuando hay un coche delante, reduce la velocidad. Cuando un automóvil se acerca demasiado a la izquierda, gira a la derecha y cambia de carril. A menos, por supuesto, que también haya un automóvil a su derecha. Es un proceso complejo que involucra diferentes combinaciones de acciones (girar a la izquierda, girar a la derecha, acelerar más o menos, frenar) basado en diferentes combinaciones de información del sensor.
Ahora tienes que conectar el sensor a los mecanismos robóticos. ¿Cómo haces esto? No está claro. Así que conectas cada sensor a cada actuador robótico.
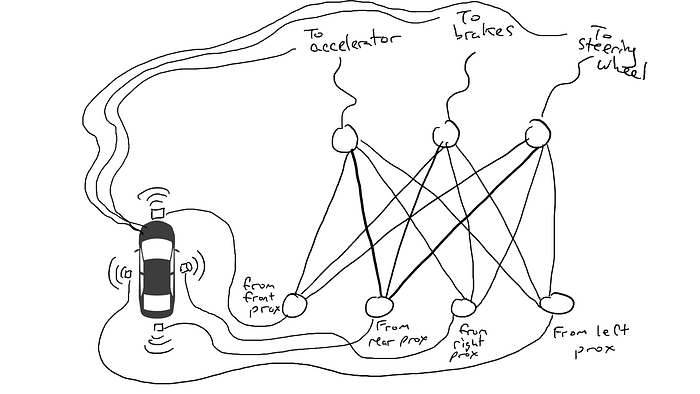
¿Qué pasa cuando sacas tu coche a la carretera? La corriente eléctrica fluye desde todo el sensor a todos los actuadores robóticos y el automóvil gira a la izquierda, gira a la derecha, acelera y frena simultáneamente. Es un desastre.
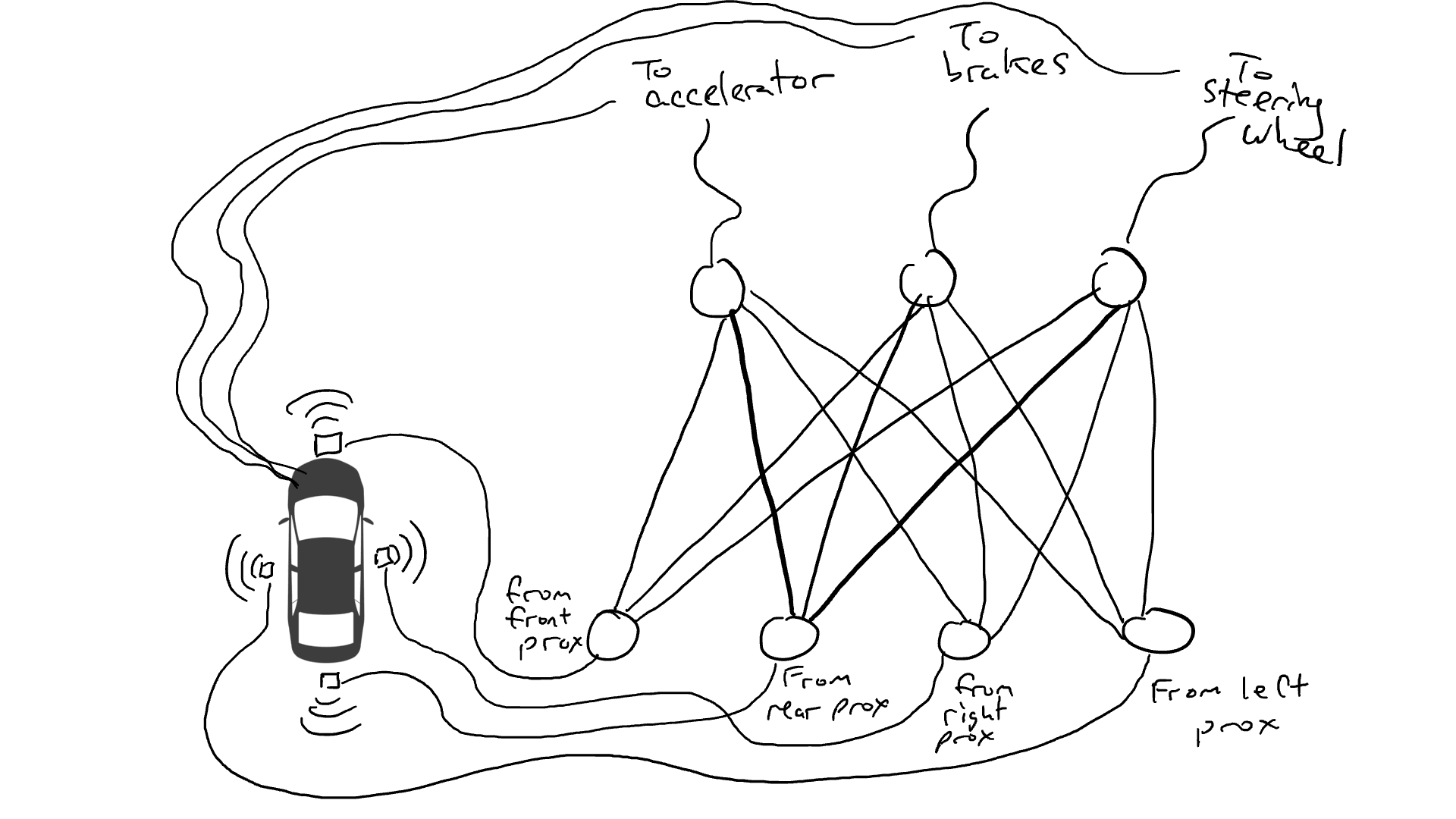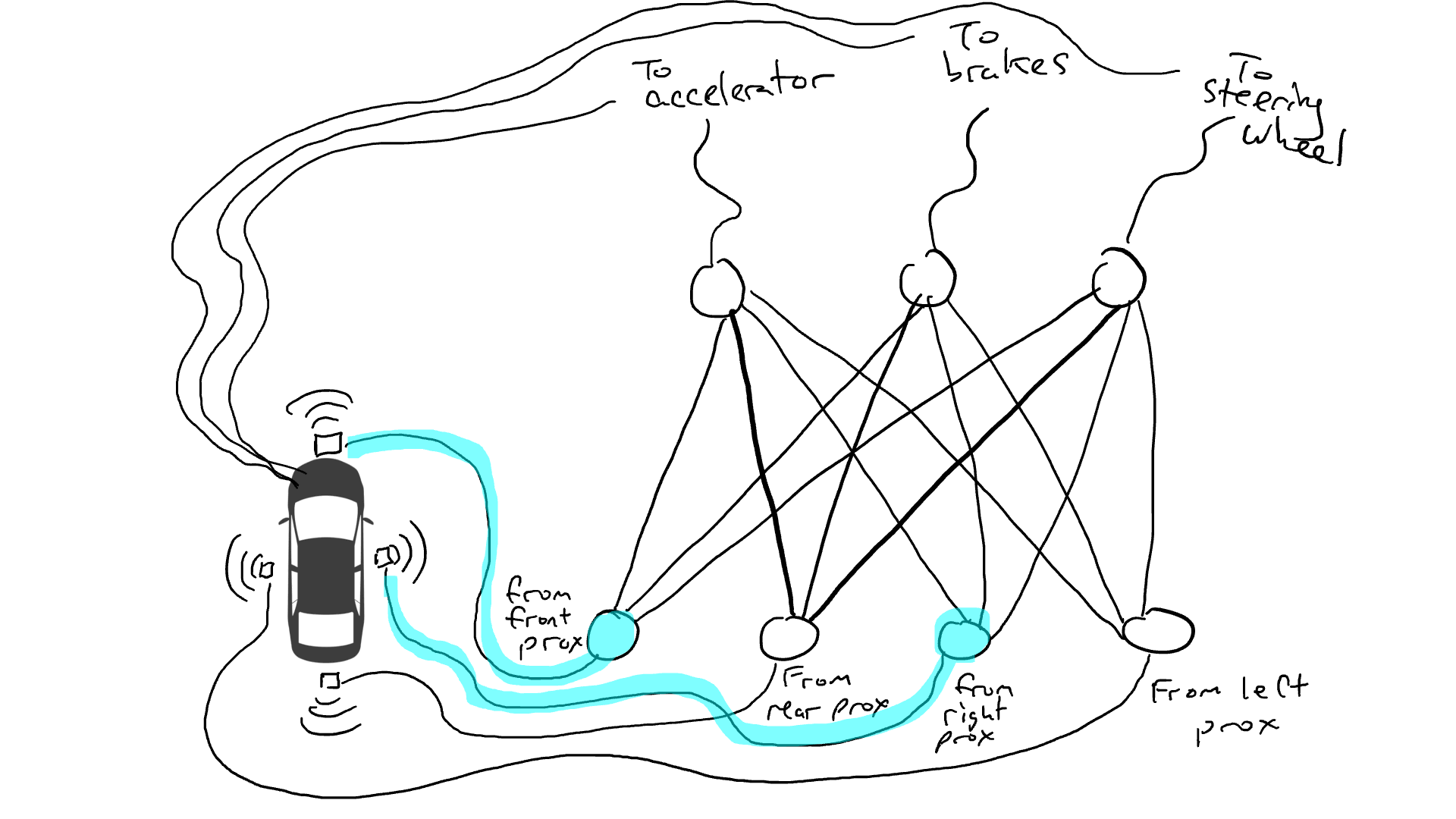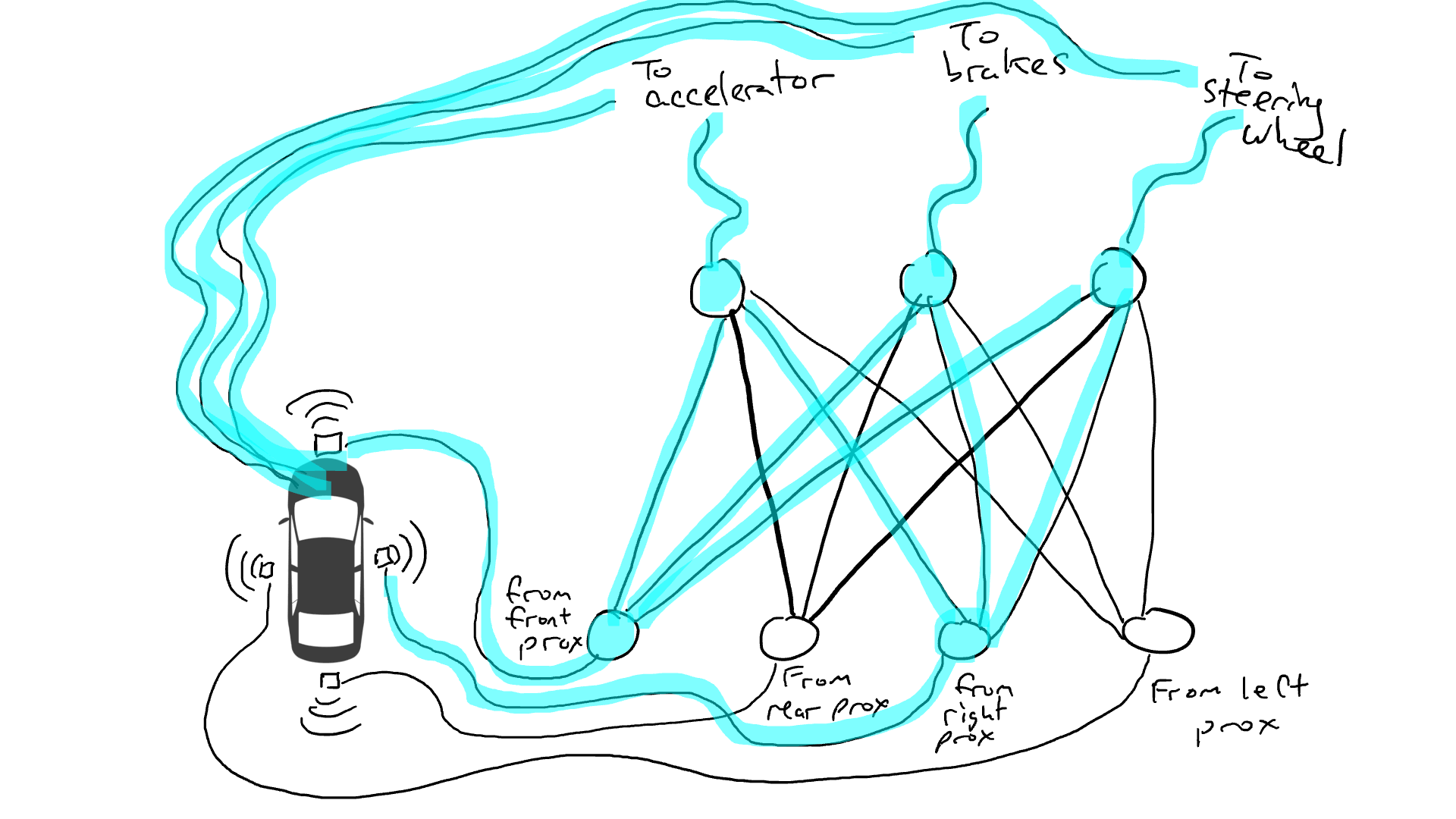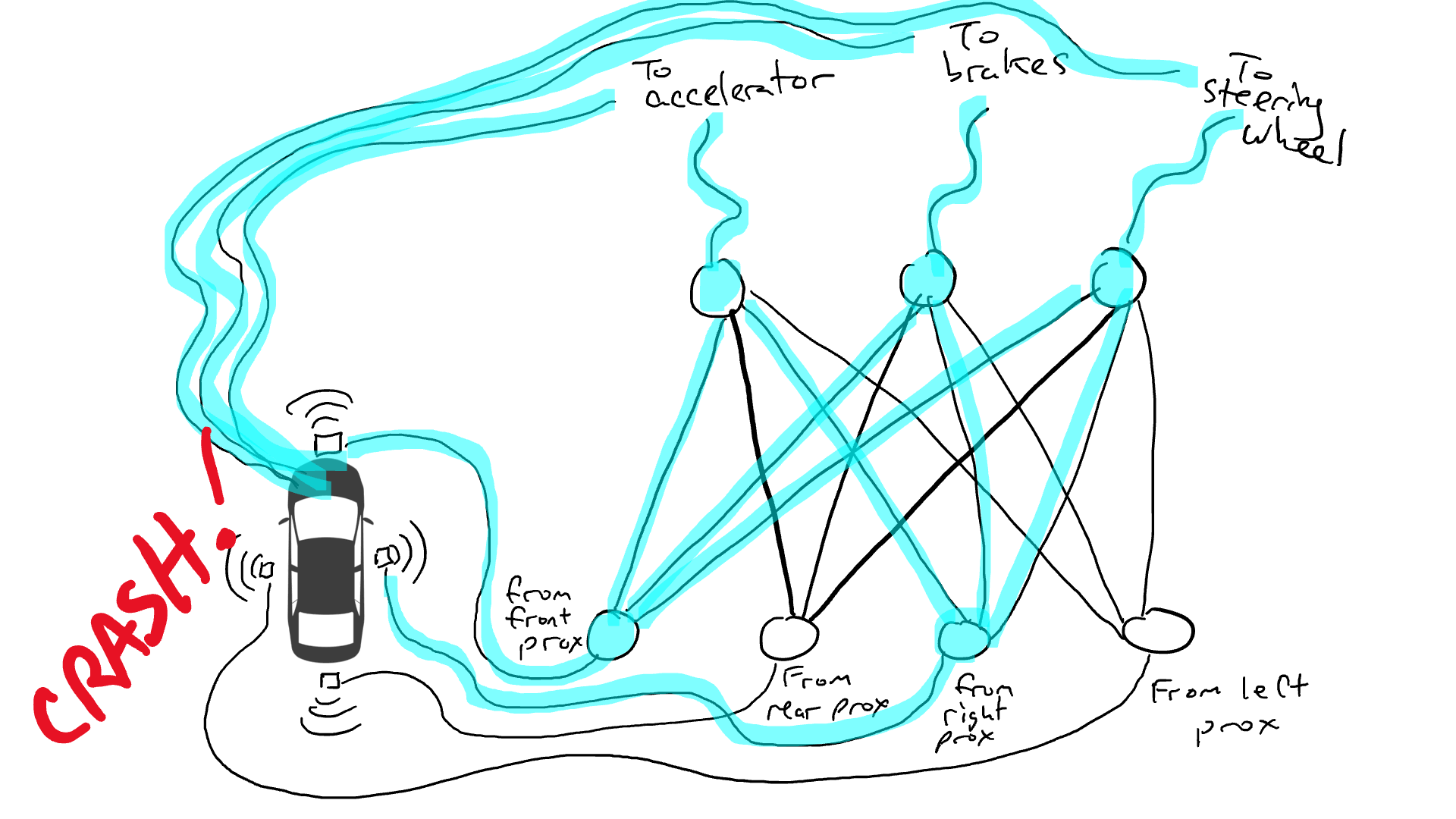
Eso no es bueno. Así que tomo mis resistencias y empiezo a colocarlas en diferentes partes de los circuitos para que la electricidad pueda fluir más libremente entre ciertos sensores y ciertos actuadores robóticos. Por ejemplo, quiero que la electricidad fluya más libremente desde los sensores de proximidad delanteros hacia los frenos y no hacia el volante. También coloco cosas llamadas compuertas, que detienen el flujo de electricidad hasta que se acumula suficiente electricidad para accionar un interruptor (solo permiten que la electricidad fluya cuando el sensor de proximidad delantero y el sensor de proximidad trasero informan números altos), o envían energía eléctrica hacia adelante solo cuando la potencia eléctrica de entrada es baja (envía más electricidad al acelerador cuando el sensor de proximidad delantero informa un valor bajo).
Pero, ¿dónde pongo estas resistencias y puertas? No sé. Empiezo a ponerlos al azar por todo el lugar. Entonces lo intento de nuevo. Tal vez esta vez mi coche conduce mejor, lo que significa que a veces frena cuando los datos indican que es mejor frenar y gira cuando los datos indican que es mejor conducir, etc. Pero no lo hace todo bien. Y algunas cosas las hace peor (acelera cuando los datos dicen que es mejor frenar). Así que sigo probando aleatoriamente diferentes combinaciones de resistencias y puertas. Eventualmente me toparé con una combinación que funcione lo suficientemente bien como para declarar el éxito. Tal vez se vea así:
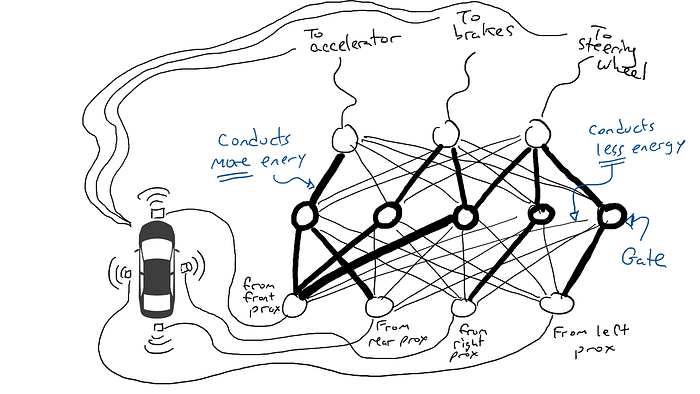
(En realidad, no agregamos ni restamos puertas, que siempre están ahí, sino que modificamos las puertas para que se activen con menos energía desde abajo o requieran más energía desde abajo, o tal vez liberen mucha energía solo cuando hay muy poca energía desde abajo. Los puristas del aprendizaje automático podrían vomitar un poco en la boca ante esta caracterización. Técnicamente, esto se hace ajustando algo llamado sesgo en las puertas, que normalmente no se muestra en diagramas como estos, pero en términos de la metáfora del circuito se puede considerar como un cable que entra en cada puerta conectado directamente a una fuente eléctrica, que luego se puede modificar como todos los demás cables).
¡Hagámoslo para una prueba de manejo!
Intentar cosas al azar apesta. Un algoritmo llamado retropropagación es razonablemente bueno para hacer conjeturas sobre cómo cambiar la configuración del circuito. Los detalles del algoritmo no son importantes, excepto para saber que realiza pequeños cambios en el circuito para que el comportamiento del circuito se acerque más a lo que sugieren los datos, y luego de miles o millones de ajustes, eventualmente puede llegar a algo cercano a estar de acuerdo con los datos.
Llamamos parámetros a las resistencias y puertas porque en realidad están en todas partes y lo que hace el algoritmo de propagación hacia atrás es declarar que cada resistencia es más fuerte o más débil. Así todo el circuito se puede reproducir en otros coches si conocemos el trazado de los circuitos y los valores de los parámetros.
4. ¿Qué es el aprendizaje profundo?
Deep Learning es un reconocimiento de que podemos poner otras cosas en nuestros circuitos además de resistencias y puertas. Por ejemplo, podemos tener un cálculo matemático en medio de nuestro circuito que suma y multiplica cosas antes de enviar electricidad. Deep Learning todavía usa la misma técnica incremental básica de adivinar parámetros.
5. ¿Qué es un modelo de lenguaje?
Cuando hicimos el ejemplo del automóvil, estábamos tratando de que nuestra red neuronal realizara un comportamiento que fuera consistente con nuestros datos. Estábamos preguntando si podíamos crear un circuito que manipulara los mecanismos del automóvil de la misma manera que lo haría un conductor en circunstancias similares. Podemos tratar el lenguaje de la misma manera. Podemos mirar un texto escrito por humanos y preguntarnos si un circuito podría producir una secuencia de palabras que se parezca mucho a las secuencias de palabras que los humanos tienden a producir. Ahora, nuestros sensores se disparan cuando vemos palabras y nuestros mecanismos de salida también son palabras.
¿Qué estamos intentando hacer? Estamos tratando de crear un circuito que adivine una palabra de salida, dado un montón de palabras de entrada. Por ejemplo:
«Erase una ____»
parece que debería llenar el espacio en blanco con «tiempo» pero no «armadillo».
Tendemos a hablar de modelos de lenguaje en términos de probabilidad. Matemáticamente escribiremos el ejemplo anterior como:
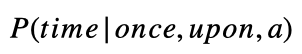
Si no está familiarizado con la notación, no se preocupe. Esto es solo una charla matemática que significa la probabilidad ( P ) de la palabra «tiempo» dado (el símbolo de la barra | significa dado ) un montón de palabras «una vez», «sobre» y «a». Esperaríamos que un buen modelo de lenguaje produjera una mayor probabilidad de la palabra «tiempo» que de la palabra «armadillo».
Podemos generalizar esto a:
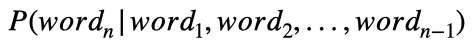
lo que simplemente significa calcular la probabilidad de la n -ésima palabra en una secuencia dadas todas las palabras que vienen antes (palabras en las posiciones 1 a n -1).
Pero retrocedamos un poco. Piensa en una máquina de escribir anticuada, de esas que tienen brazos percutores.

Excepto que en lugar de tener un percutor diferente para cada letra, tenemos un percutor para cada palabra. ¡Si el idioma inglés tiene 50,000 palabras, entonces esta es una gran máquina de escribir!
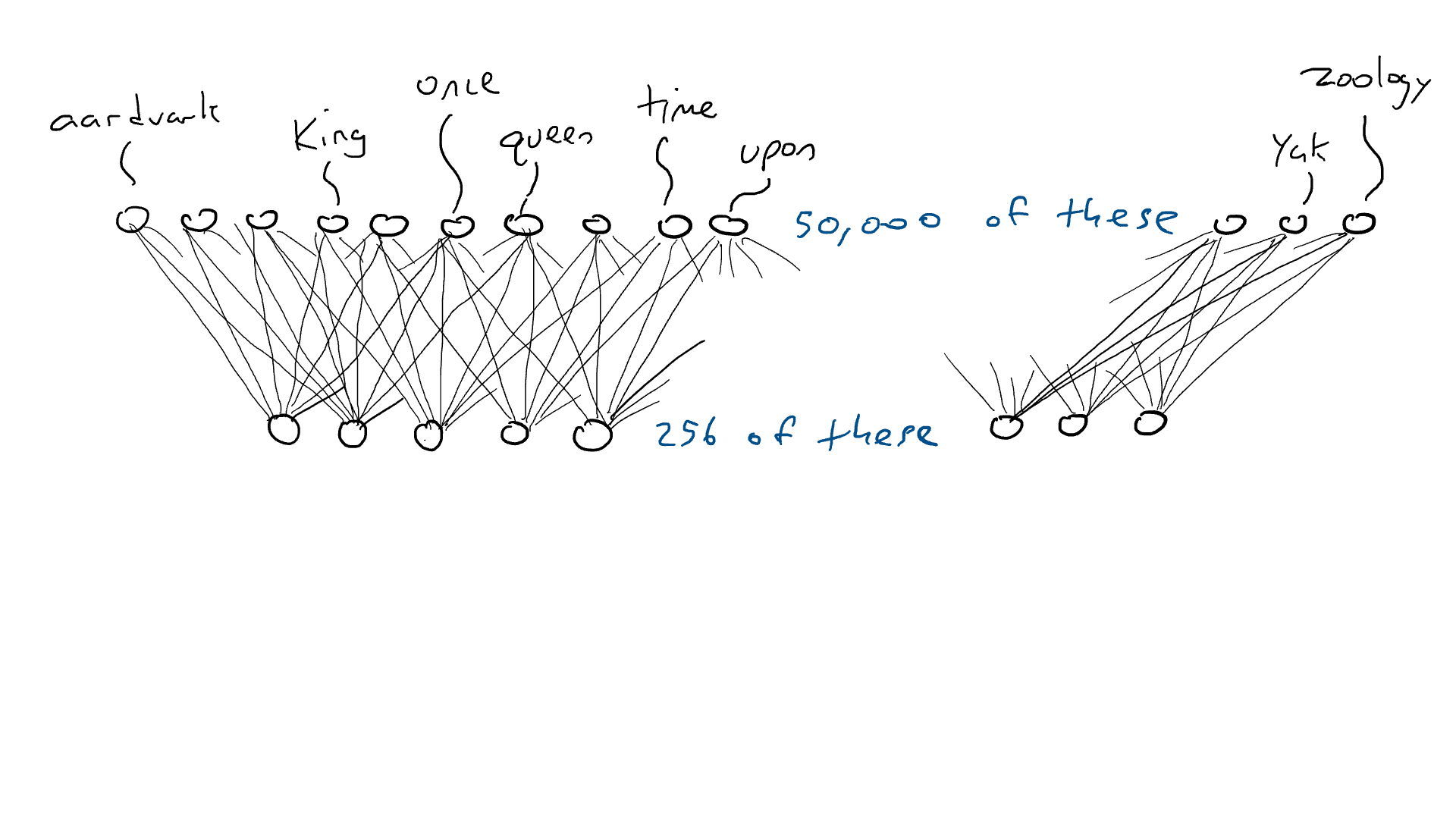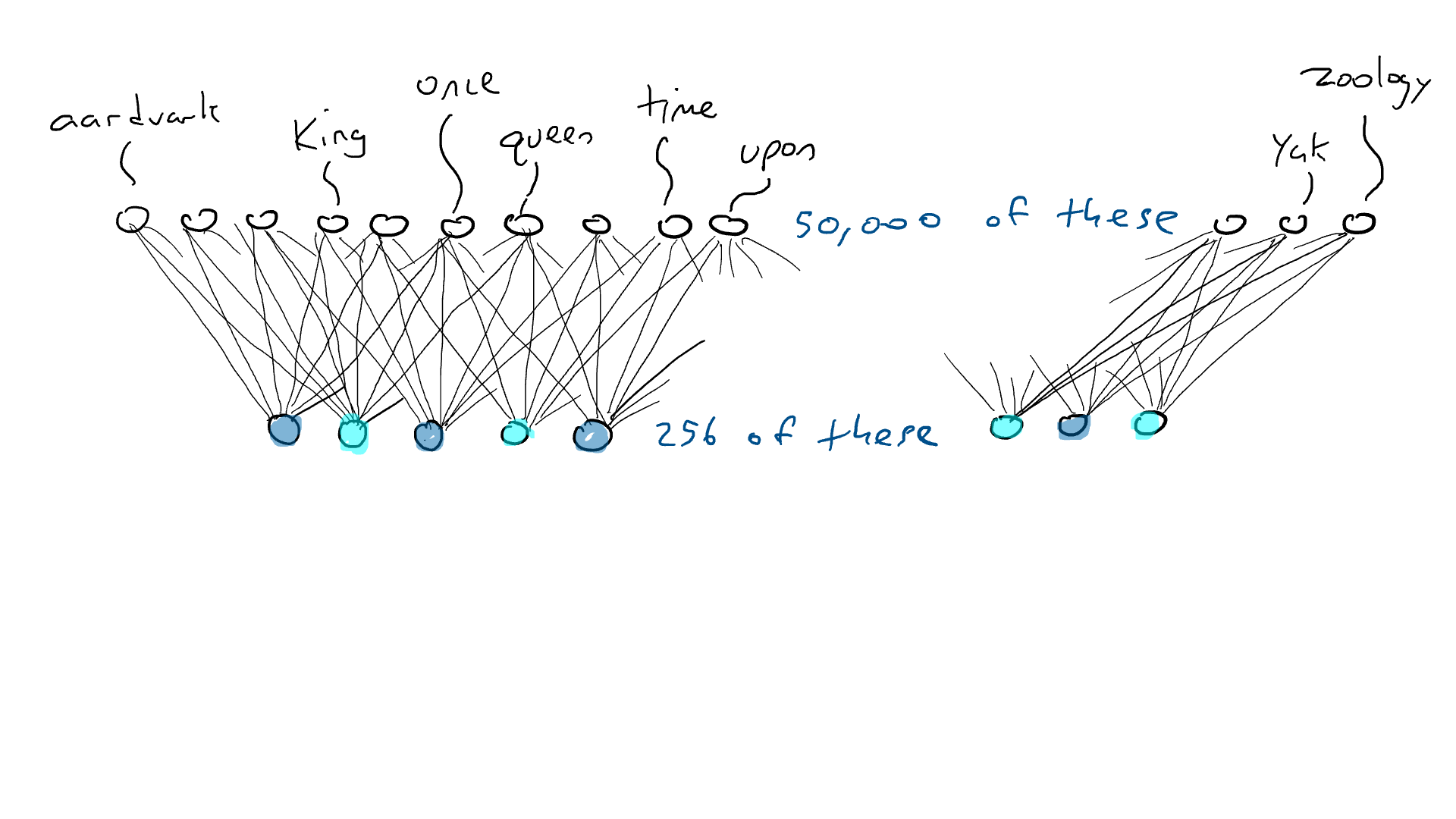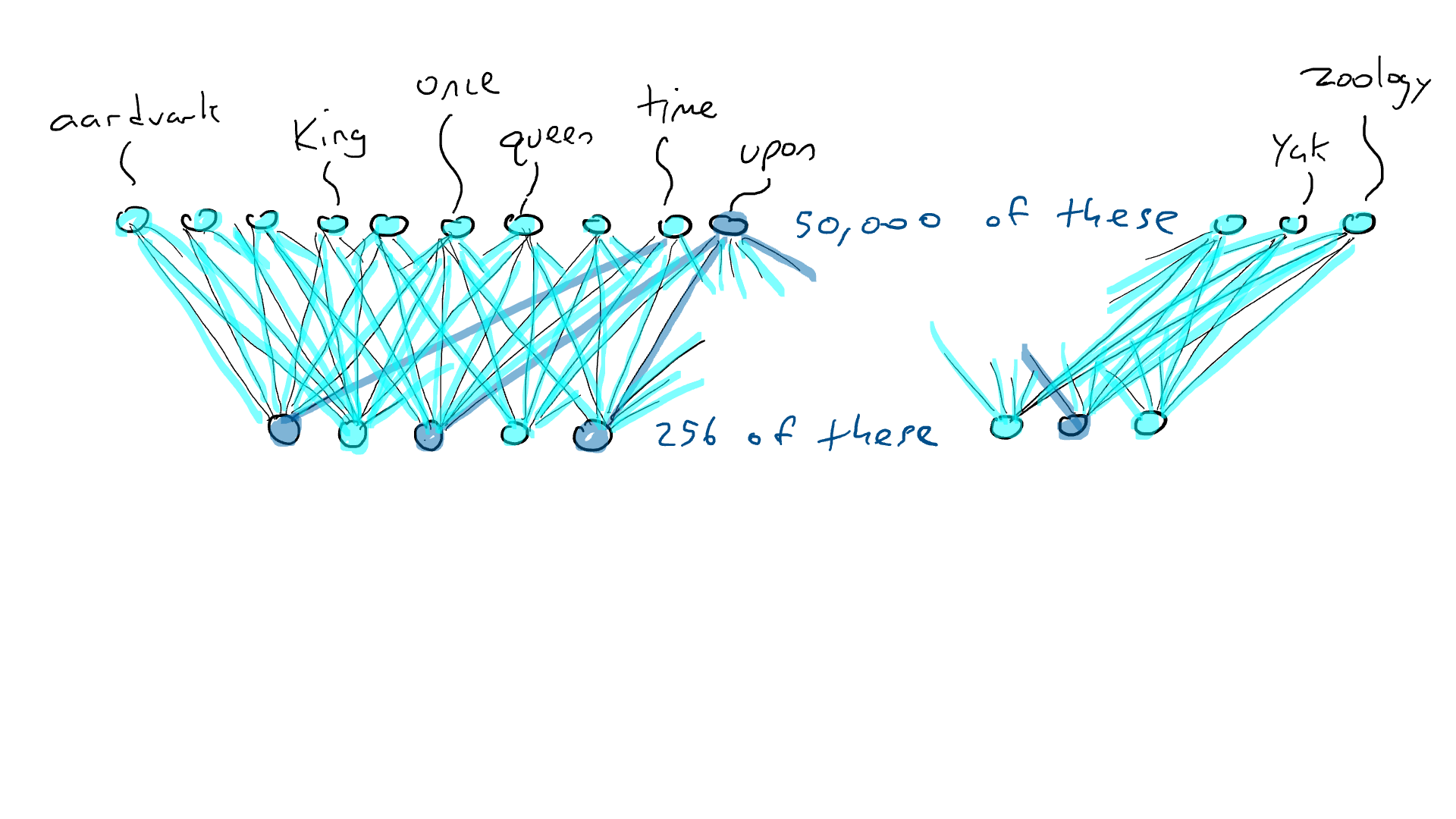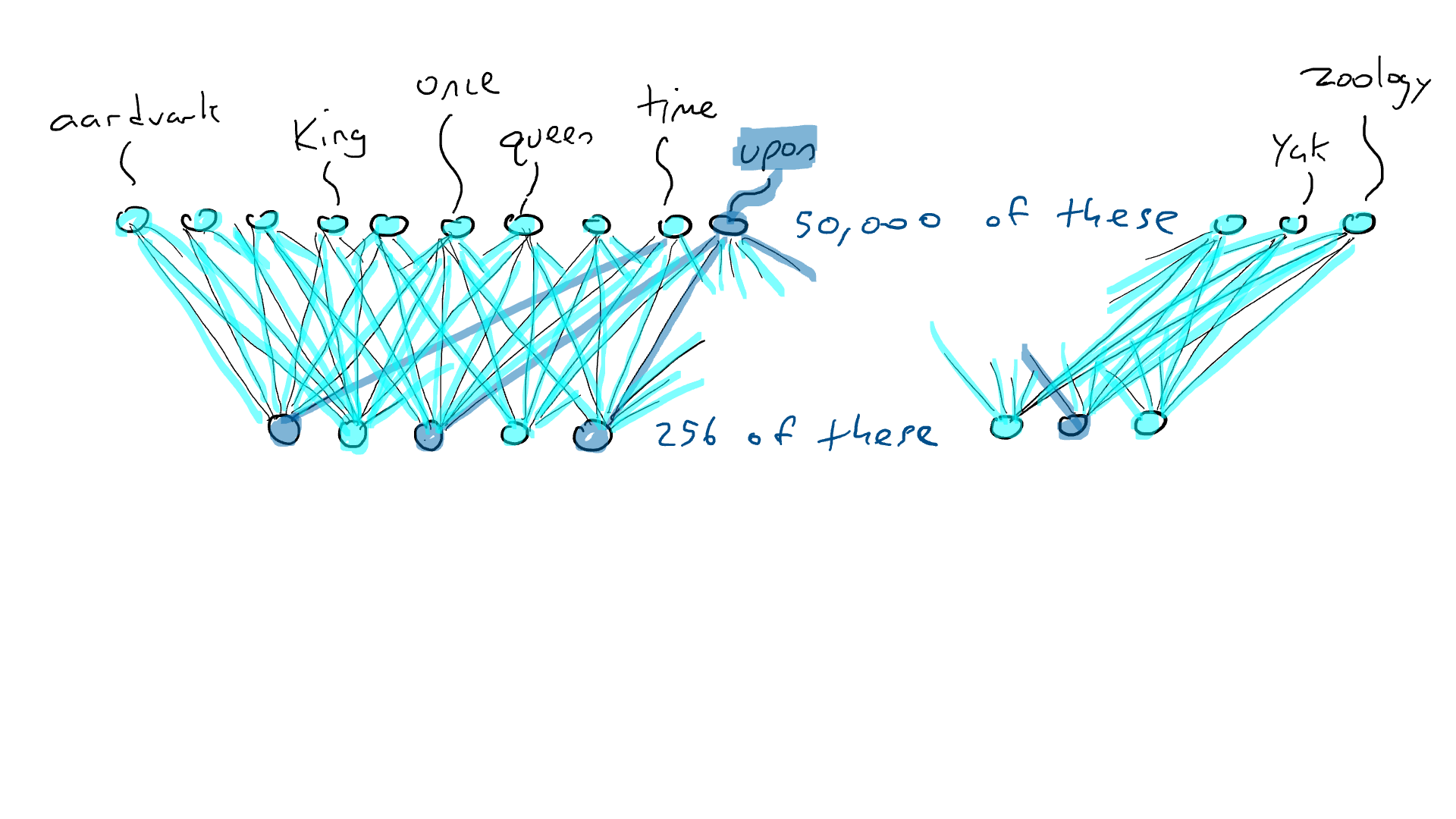
En lugar de la red para el automóvil, piense en una red similar, excepto que la parte superior de nuestro circuito tiene 50 000 salidas conectadas a los brazos delanteros, una para cada palabra. En consecuencia, tendríamos 50.000 sensores, cada uno detectando la presencia de una palabra de entrada diferente. Entonces, lo que estamos haciendo al final del día es elegir un solo brazo delantero que reciba la señal eléctrica más alta y esa es la palabra que va en el espacio en blanco.
Aquí es donde estamos: si quiero hacer un circuito simple que tome una sola palabra y produzca una sola palabra, tendría que hacer un circuito que tenga 50 000 sensores (uno para cada palabra) y 50 000 salidas (una para cada palabra). brazo delantero). Solo cablearía cada sensor a cada brazo delantero para un total de 50 000 x 50 000 = 2500 millones de cables.
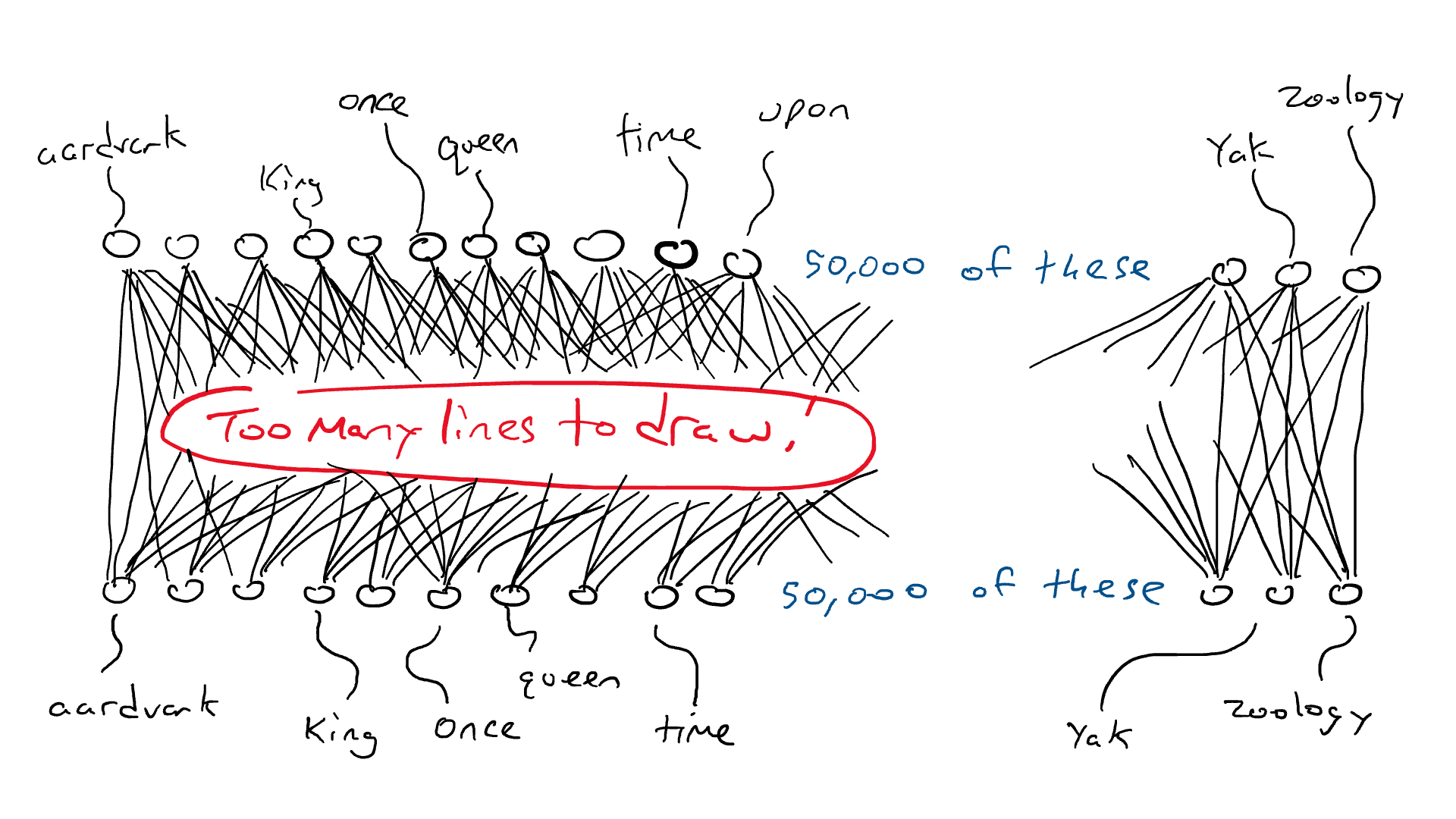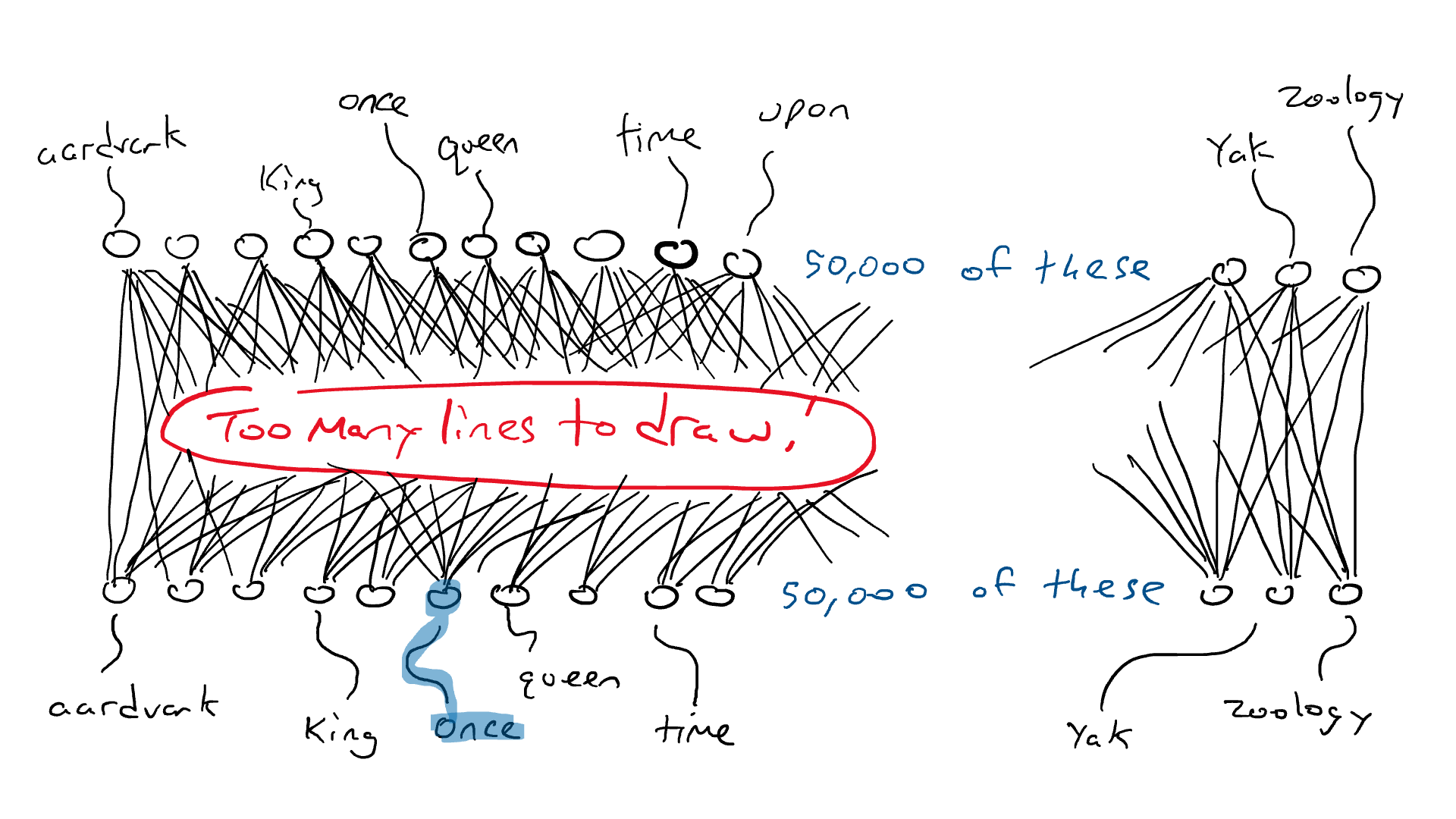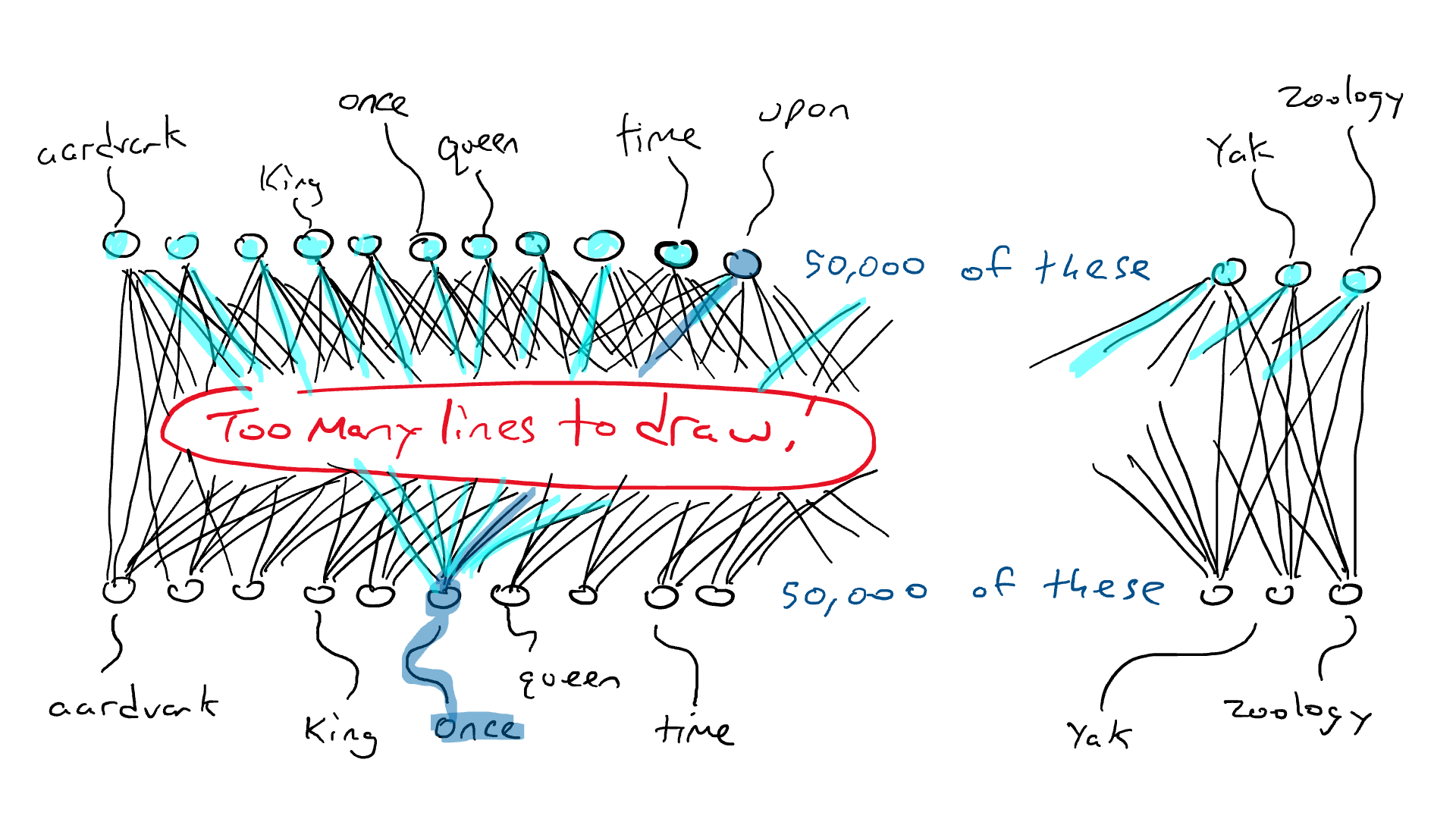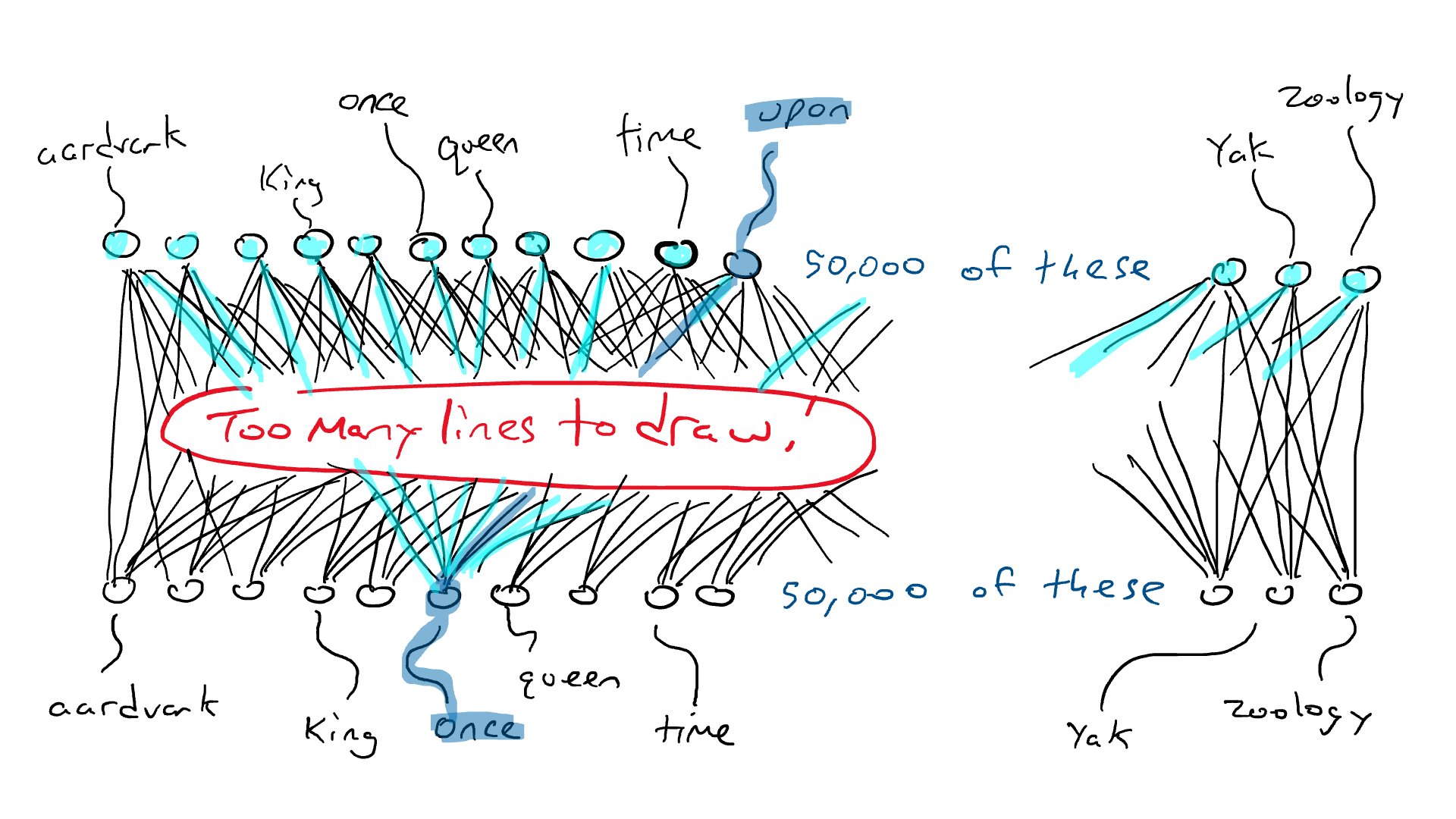
¡Esa es una gran red!
Pero se pone peor. Si quiero hacer el ejemplo de «Érase una vez ___», necesito sentir qué palabra está en cada una de las tres posiciones de entrada. Necesitaría 50.000 x 3 = 150.000 sensores. Cableado hasta 50 000 brazos delanteros me da 150 000 x 50 000 = 7500 millones de cables. A partir de 2023, la mayoría de los modelos de idiomas grandes pueden admitir 4000 palabras, y el más grande puede admitir 32 000 palabras. Mis ojos están llorosos.
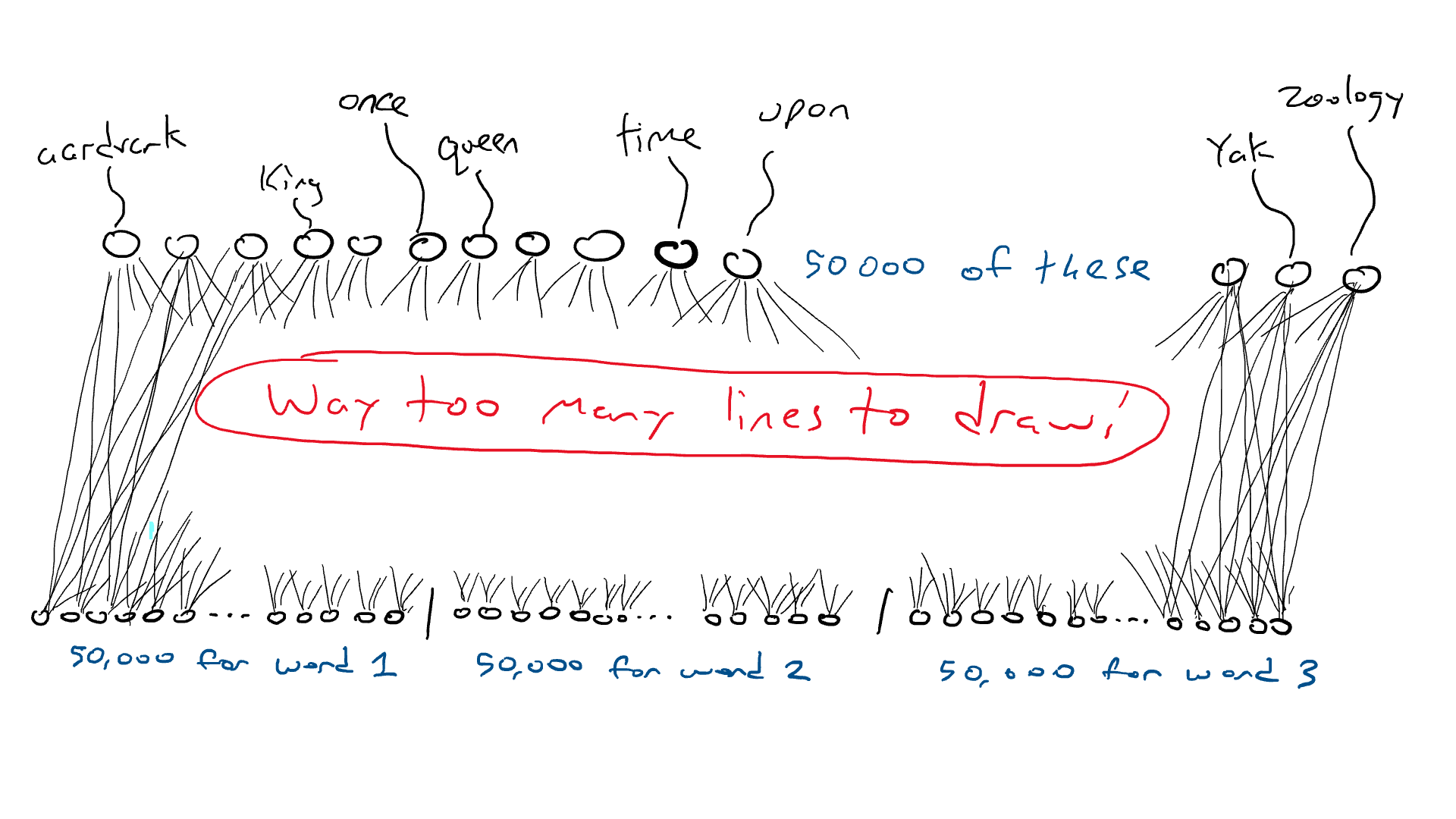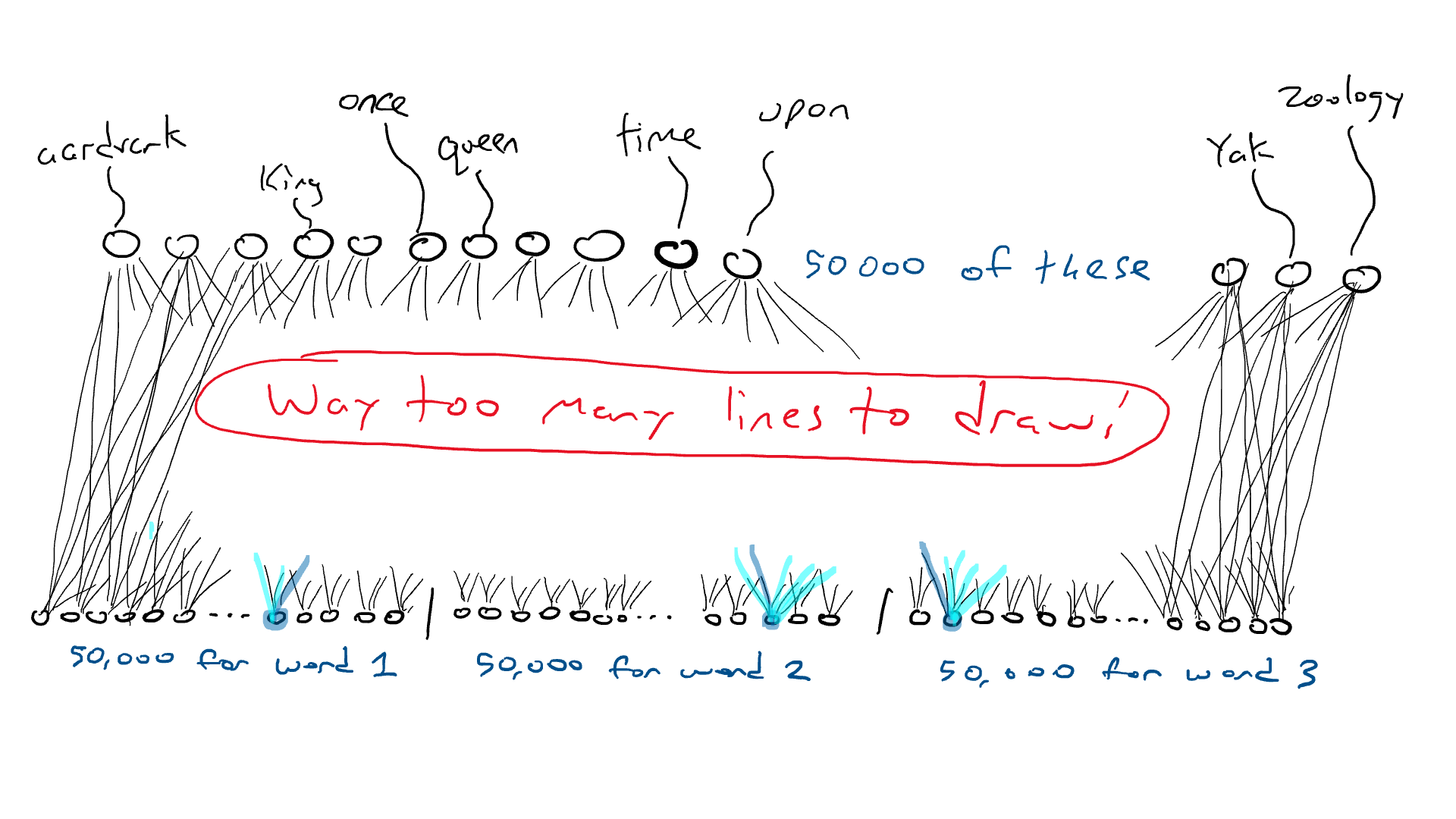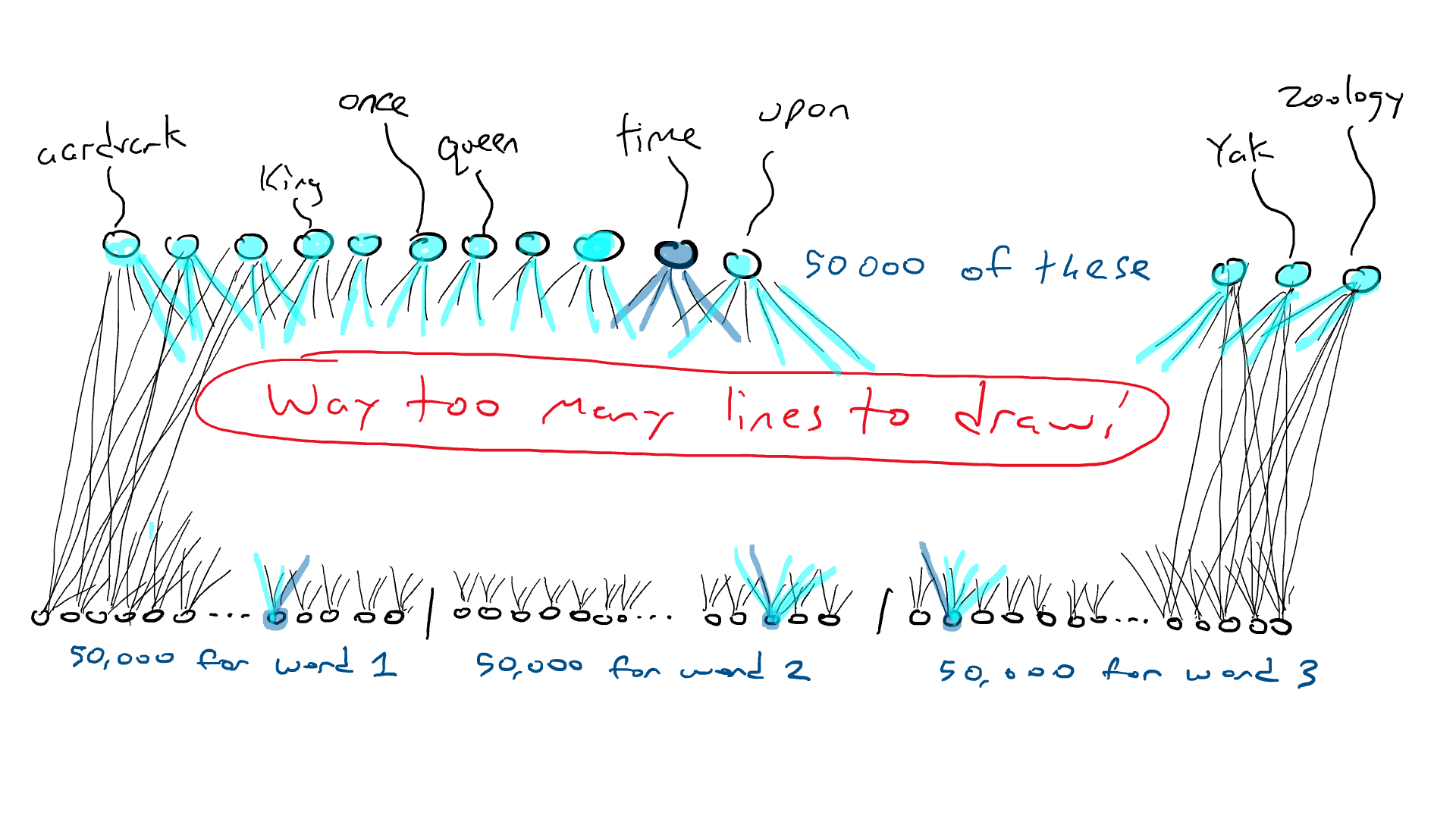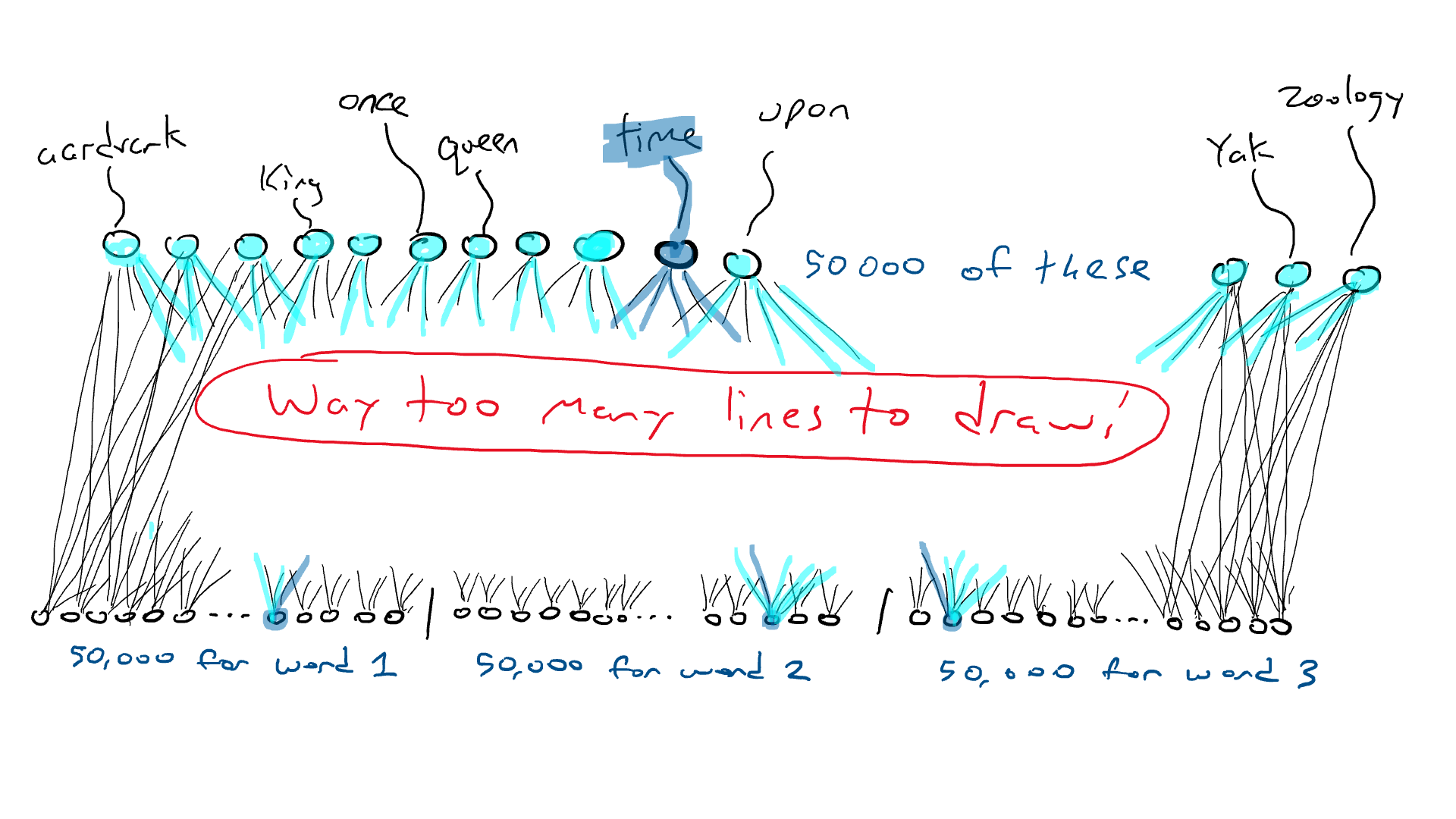
Vamos a necesitar algunos trucos para manejar esta situación. Tomaremos las cosas por etapas.
5.1 Codificadores
Lo primero que haremos será dividir nuestro circuito en dos circuitos, uno llamado codificador y otro llamado decodificador . La idea es que muchas palabras significan aproximadamente lo mismo. Considere las siguientes frases:
El rey se sentó en el ___La reina se sentó en el ___La princesa se sentó en el ___El regente se sentó en el ___
Una suposición razonable para todos los espacios en blanco anteriores sería «trono» (o tal vez «inodoro»). Lo que quiere decir que es posible que no necesite cables separados entre el «rey» y el «trono», o entre la «reina» y el «trono», etc. En cambio, sería genial si tuviera algo que significa aproximadamente realeza y cada vez que ver «rey» o «reina», yo uso esta cosa intermedia en su lugar. Entonces solo tengo que preocuparme de qué palabras significan aproximadamente lo mismo y luego qué hacer al respecto (enviar mucha energía a «trono»).
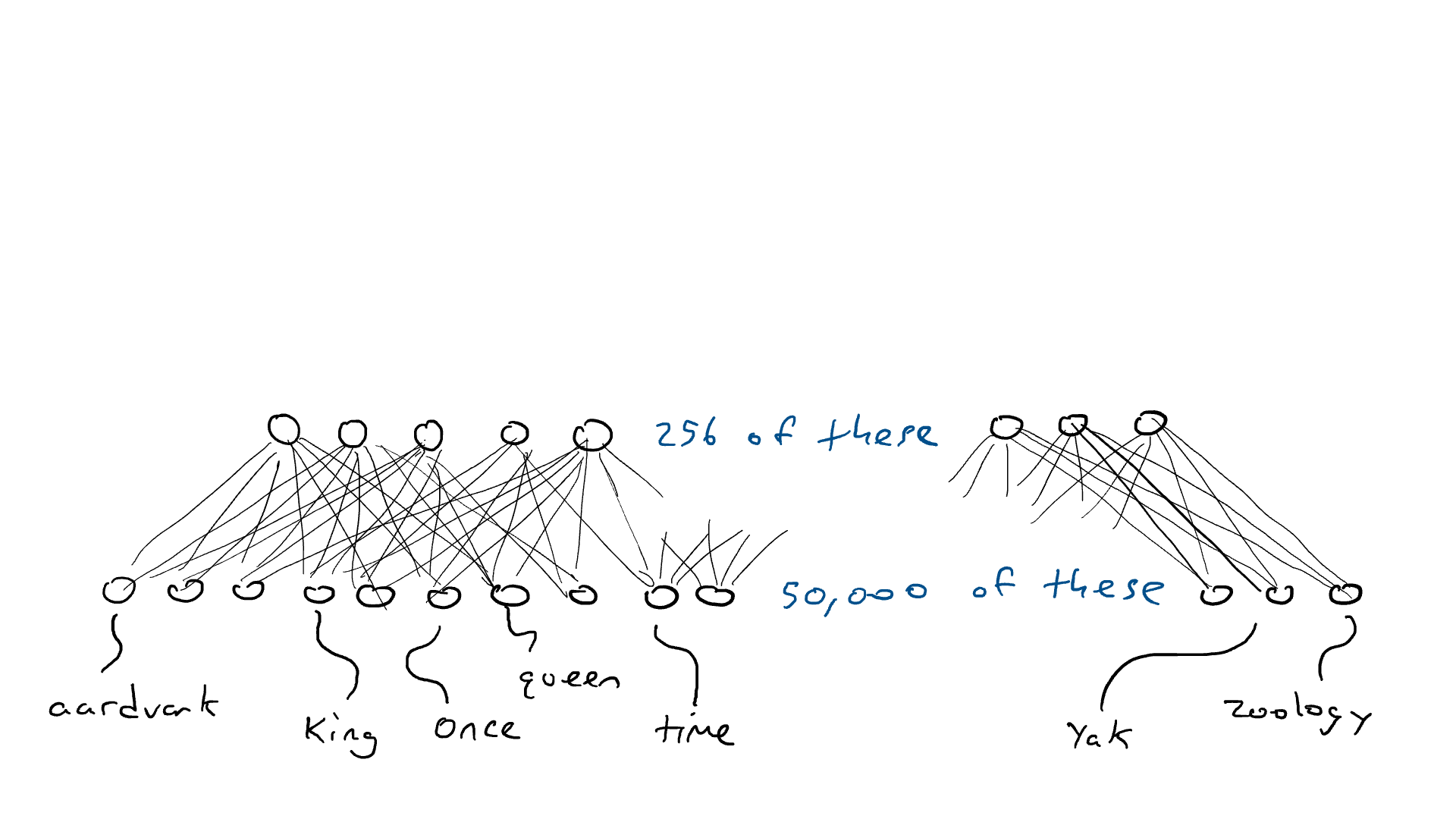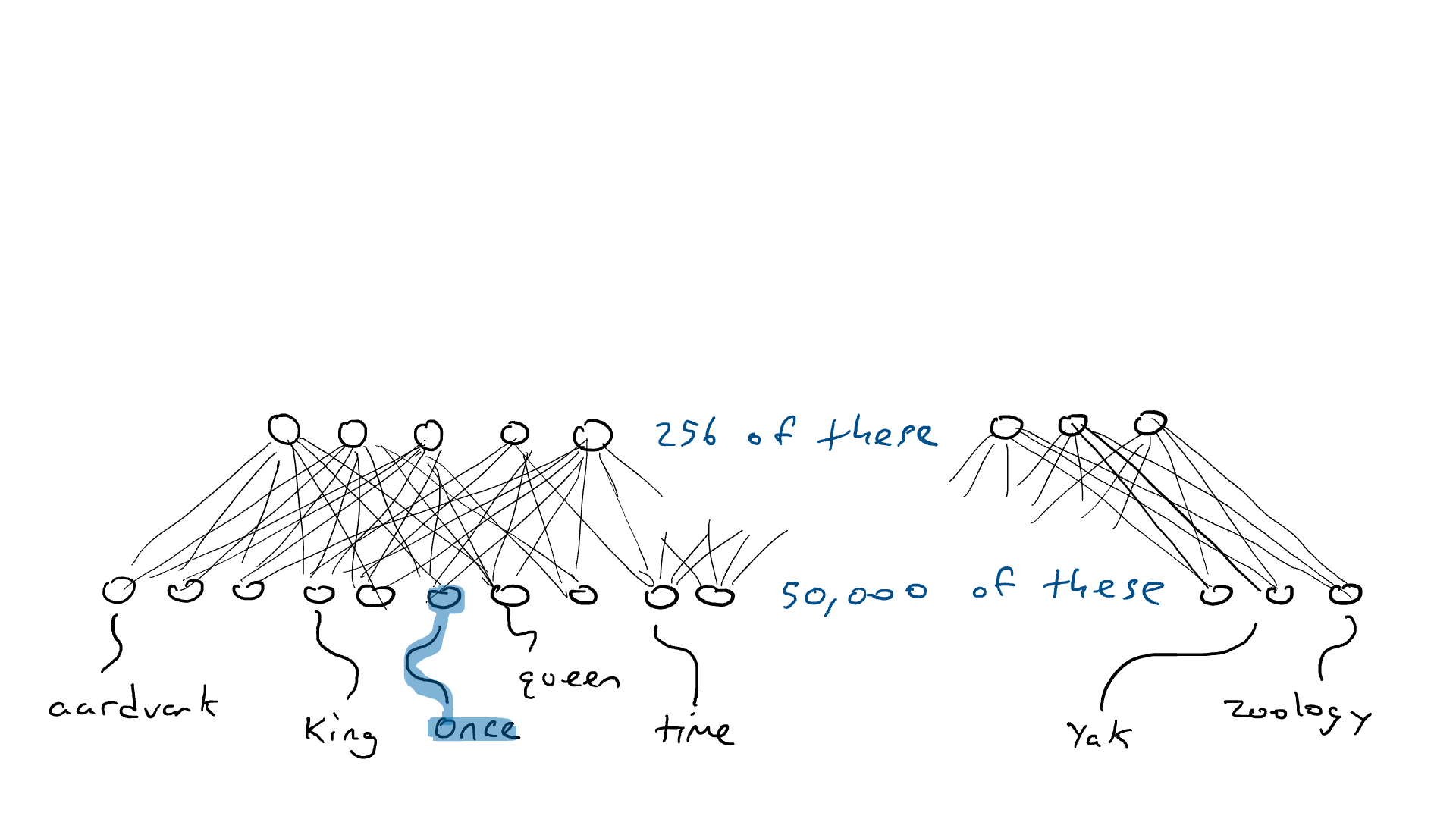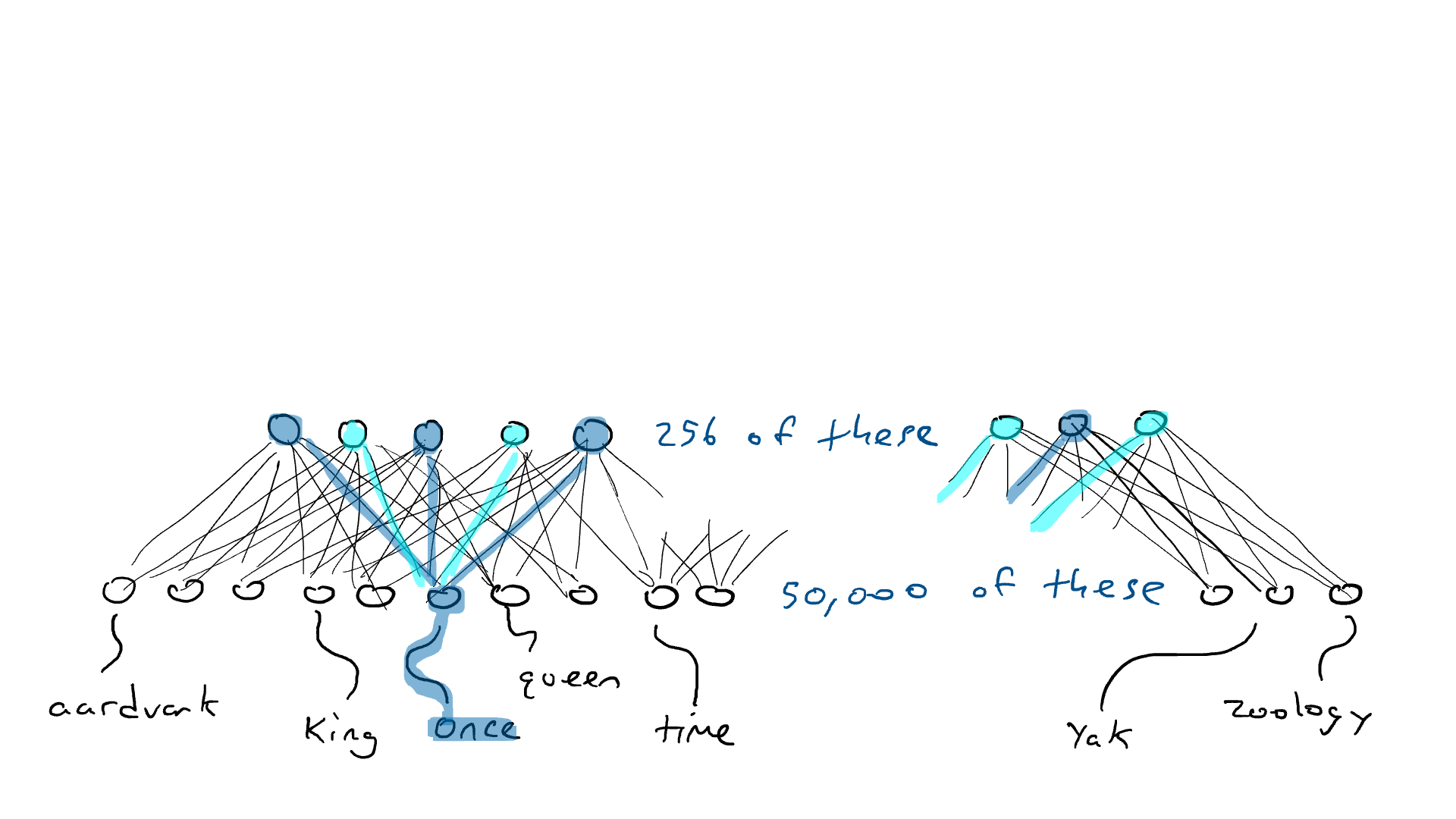
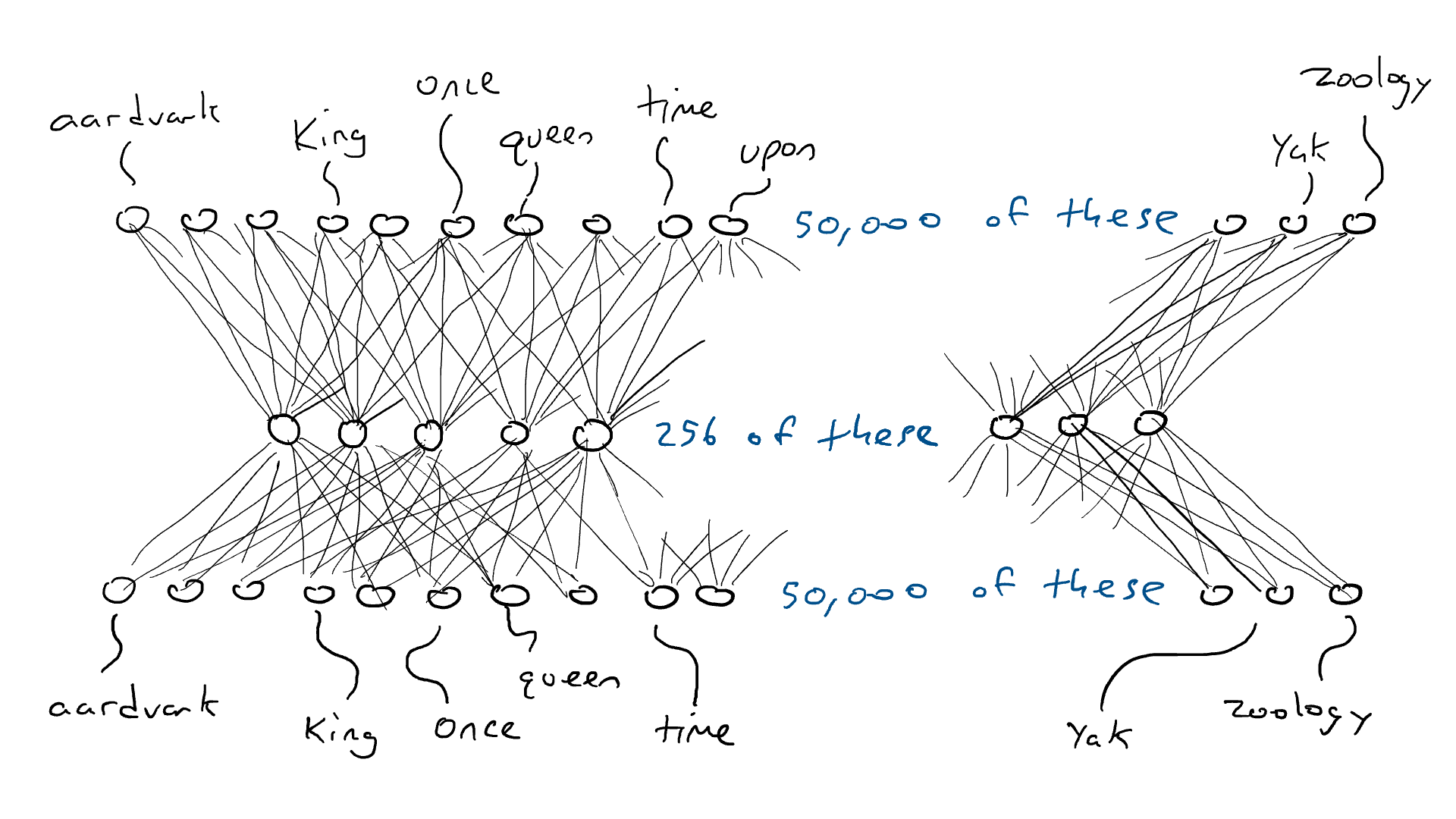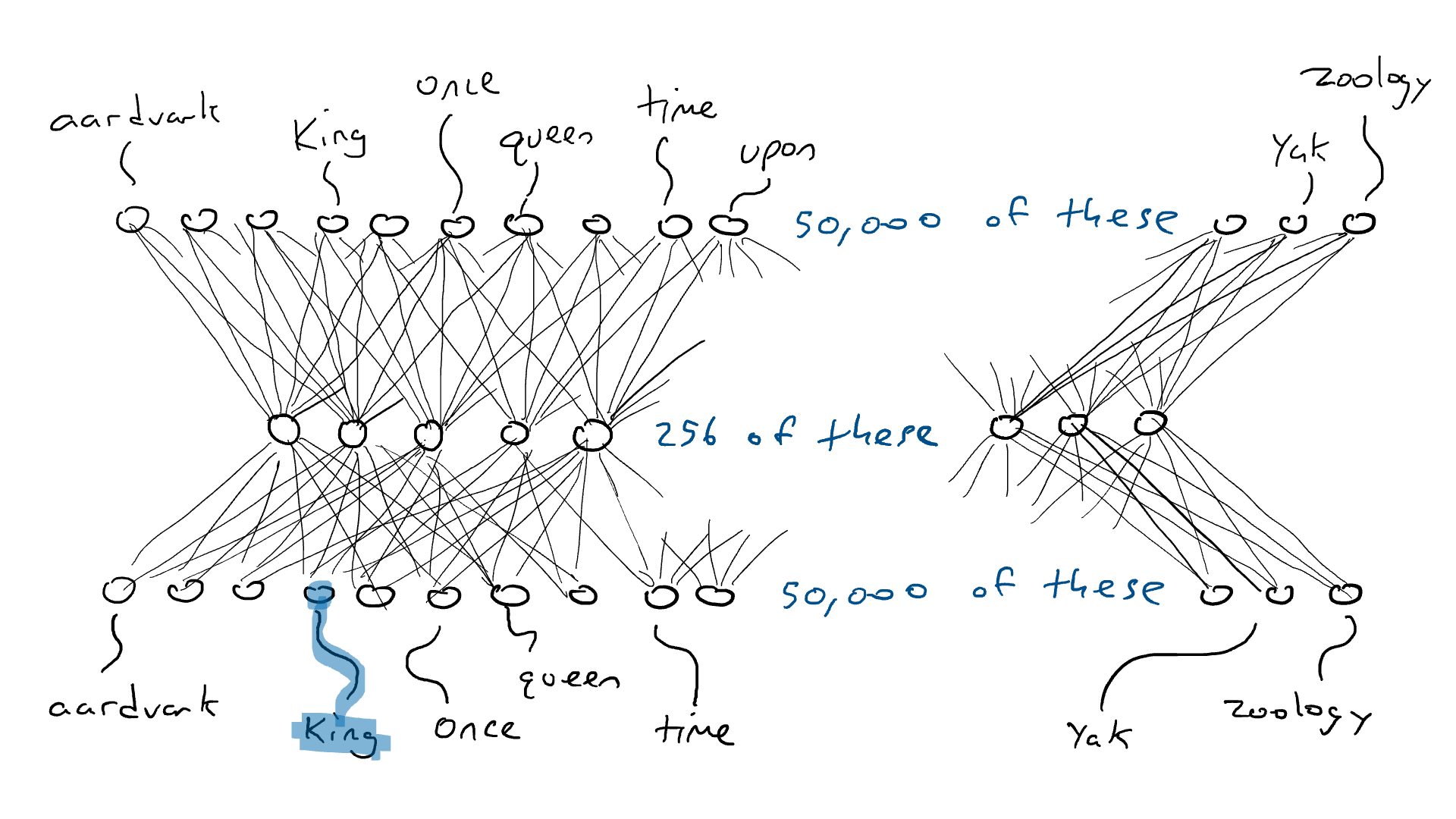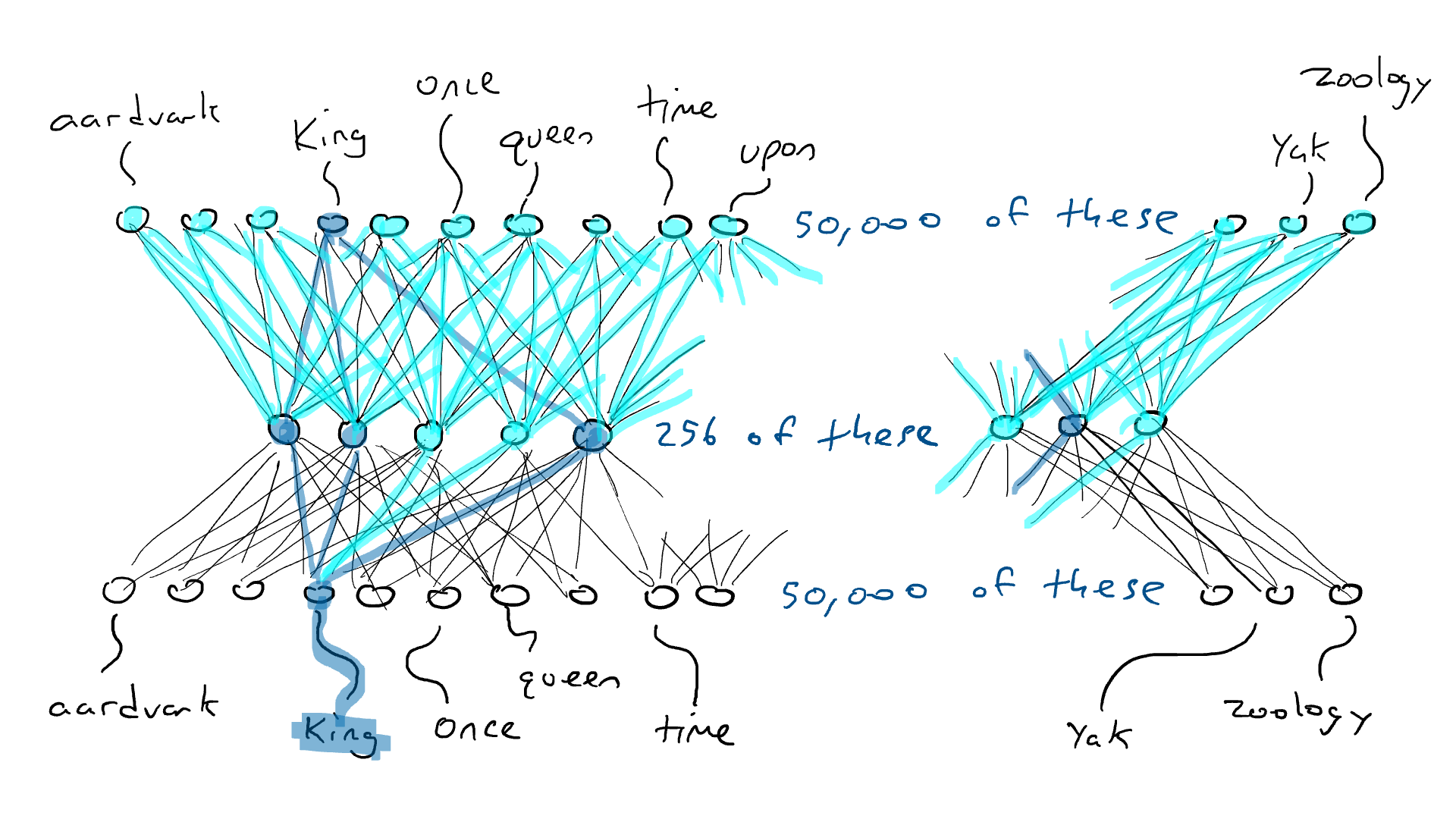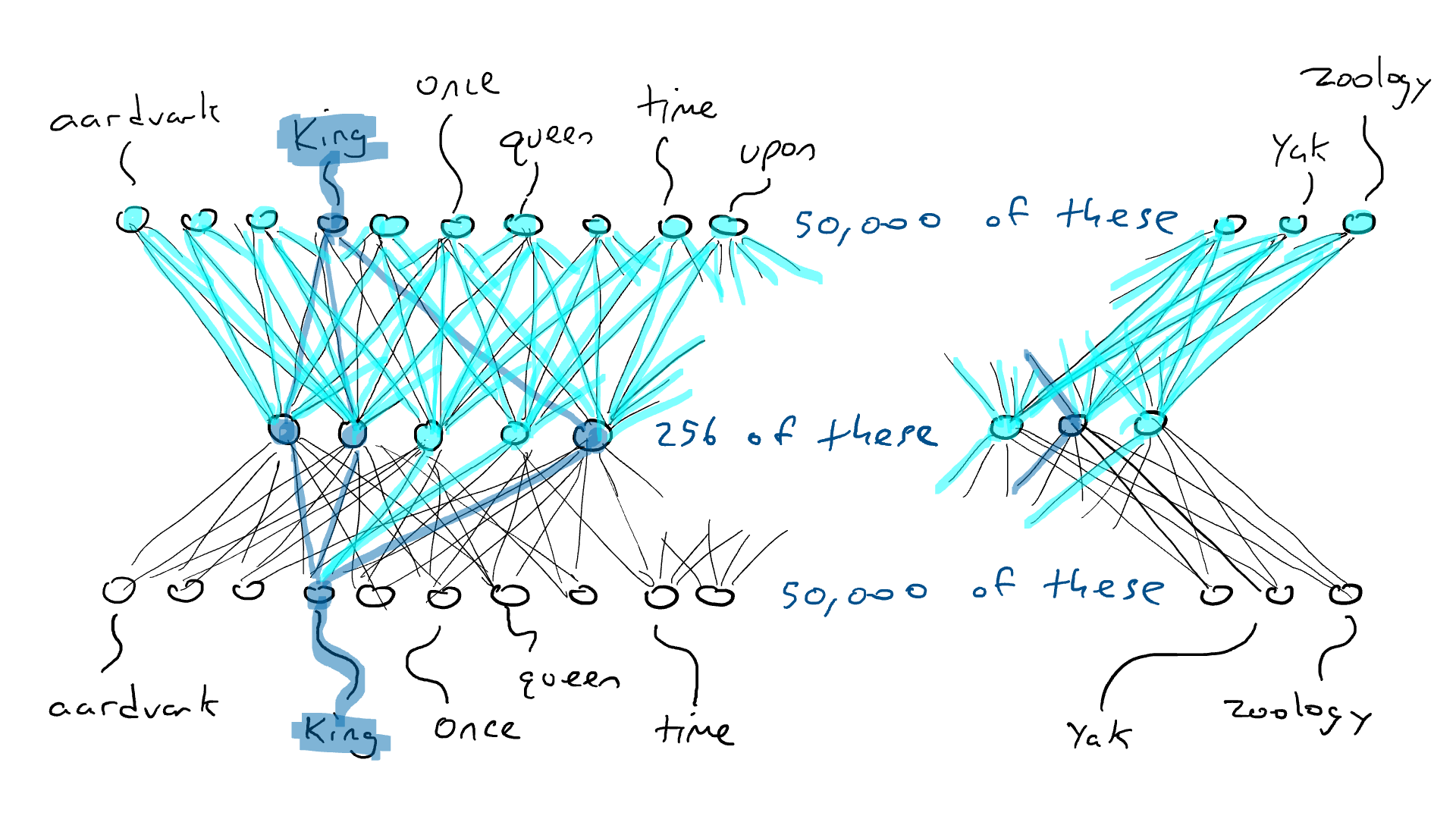
Así que esto es lo que vamos a hacer. Vamos a configurar un circuito que tome sensores de 50 000 palabras y se asigne a un conjunto más pequeño de salidas, digamos 256 en lugar de 50 000. Y en lugar de solo poder disparar un brazo delantero, podemos machacar un montón de brazos a la vez. Cada combinación posible de brazos delanteros podría representar un concepto diferente (como «realeza» o «mamíferos acorazados»). Estas 256 salidas nos darían la capacidad de representar 2²⁵⁶ = 1,15 x 10⁷⁸ conceptos. En realidad, es aún más porque, como en el ejemplo del automóvil, podemos presionar los frenos hasta la mitad, cada una de esas 256 salidas puede ser no solo 1.0 o 0.0, sino cualquier número intermedio. Entonces, tal vez la mejor metáfora para esto es que los 256 brazos del delantero se aplastan, pero cada uno se aplasta con una fuerza diferente.
De acuerdo… antes una palabra requería uno de los 50.000 sensores para disparar. Ahora hemos reducido un sensor activado y 49,999 sensores desactivados a 256 números. Entonces, «rey» podría ser [0.1, 0.0 , 0.9,…, 0.4] y «reina» podría ser [0.1, 0.1 , 0.9,…, 0.4], que son casi iguales entre sí. Llamaré a estas listas de codificaciones de números (también llamado estado oculto por razones históricas, pero no quiero explicar esto, así que nos quedaremos con la codificación). Llamamos codificador al circuito que comprime nuestros 50.000 sensores en 256 salidas . Se parece a esto:
5.2 Decodificadores
Pero el codificador no nos dice qué palabra debe venir a continuación. Así que emparejamos nuestro codificador con una red decodificadora . El decodificador es otro circuito que toma 256 números que componen la codificación y activa los 50.000 brazos delanteros originales, uno para cada palabra. Entonces elegiríamos la palabra con la salida eléctrica más alta. Así es como se vería:
5.3 Codificadores y decodificadores juntos
Aquí está el codificador y el decodificador trabajando juntos para crear una gran red neuronal:
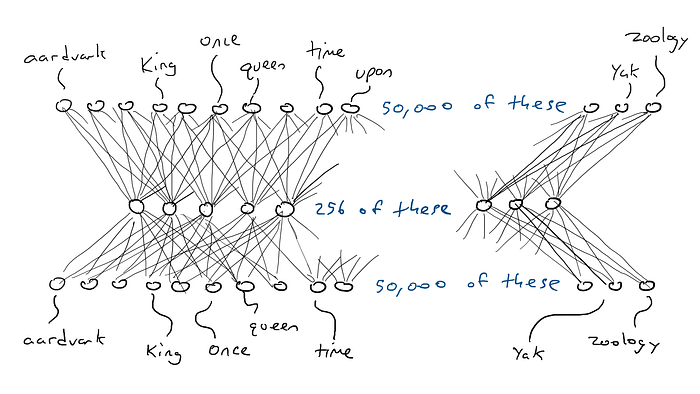
Y, por cierto, una sola palabra de entrada a una sola palabra de salida que pasa por la codificación solo necesita (50 000 x 256) x 2 = 25,6 millones de parámetros. Eso parece mucho mejor.
Ese ejemplo fue para la entrada de una palabra y la producción de una salida de palabra, por lo que tendríamos 50 000 x n entradas si quisiéramos leer n palabras y 256 x n para la codificación.
Pero, ¿por qué funciona esto? Al obligar a 50 000 palabras a encajar todas en un pequeño conjunto de números, forzamos a la red a hacer concesiones y agrupar palabras que podrían desencadenar la misma conjetura de palabras de salida. Esto es muy parecido a la compresión de archivos. Cuando comprime un documento de texto, obtiene un documento más pequeño que ya no se puede leer. Pero puede descomprimir el documento y recuperar el texto legible original. Esto se puede hacer porque el programa zip reemplaza ciertos patrones de palabras con una notación abreviada. Luego, cuando se descomprime, sabe qué texto cambiar para la notación abreviada. Nuestros circuitos codificadores y decodificadores aprenden una configuración de resistencias y puertas que comprimen y luego descomprimen palabras.
5.4 Autosupervisión
¿Cómo sabemos cuál es la mejor codificación para cada palabra? Dicho de otra manera, ¿cómo sabemos que la codificación de «rey» debe ser similar a la codificación de «reina» en lugar de «armadillo»?
Como experimento mental, considere una red de codificador-decodificador que debería tomar una sola palabra (50,000 sensores) y producir exactamente la misma palabra como salida. Esto es una tontería, pero es bastante instructivo para lo que vendrá después.
Pongo la palabra «rey» y un solo sensor envía su señal eléctrica a través del codificador y enciende parcialmente 256 valores en la codificación en el medio. Si la codificación es correcta, el decodificador enviará la señal eléctrica más alta a la misma palabra, «rey». Bien, ¿fácil? No tan rapido. Es probable que vea el brazo delantero con la palabra «armadillo» con la energía de activación más alta. Supongamos que el brazo delantero del «rey» recibe una señal eléctrica de 0,051 y el brazo delantero del «armadillo» recibe una señal eléctrica de 0,23. En realidad, ni siquiera me importa cuál es el valor de «armadillo». Solo puedo mirar la energía de salida para «rey» y saber que no era 1.0. La diferencia entre 1,0 y 0,051 es el error (también llamado pérdida) y puedo usar la propagación hacia atrás para hacer algunos cambios en el decodificador y el codificador para que se realice una codificación ligeramente diferente la próxima vez que veamos la palabra «rey».
Hacemos esto para todas las palabras. El codificador tendrá que comprometerse porque el 256 es mucho más pequeño que 50,000. Es decir, algunas palabras tendrán que usar las mismas combinaciones de energía de activación en el medio. Entonces, cuando se le dé la opción, querrá que la codificación de «rey» y «reina» sea casi idéntica y que la codificación de «armadillo» sea muy diferente. Esto le dará al decodificador una mejor oportunidad de adivinar la palabra simplemente mirando los 256 valores de codificación. Y si el decodificador ve una combinación particular de 256 valores y adivina «rey» con 0.43 y «reina» con 0.42, estaremos de acuerdo con eso siempre que «rey» y «reina» obtengan las señales eléctricas más altas y cada de los 49.998 brazos del delantero obtiene números que son más pequeños.
Decimos que la red neuronal se autosupervisa porque, a diferencia del ejemplo del automóvil, no tiene que recopilar datos separados para probar la salida. Simplemente comparamos la salida con la entrada; no necesitamos tener datos separados para la entrada y la salida.
5.5 Modelos de lenguaje enmascarado
Si el experimento mental anterior parece tonto, es un elemento básico para algo llamado modelos de lenguaje enmascarado . La idea de un modelo de lenguaje enmascarado es tomar una secuencia de palabras y generar una secuencia de palabras. Una de las palabras en la entrada y la salida están en blanco.
La [MASCARA] se sentó en el trono.
La red adivina todas las palabras. Bueno, es bastante fácil adivinar las palabras desenmascaradas. Realmente solo nos importa la conjetura de la red sobre la palabra enmascarada. Es decir, tenemos 50.000 brazos delanteros por cada palabra en la salida. Buscamos en los 50.000 brazos del delantero la palabra enmascarada.
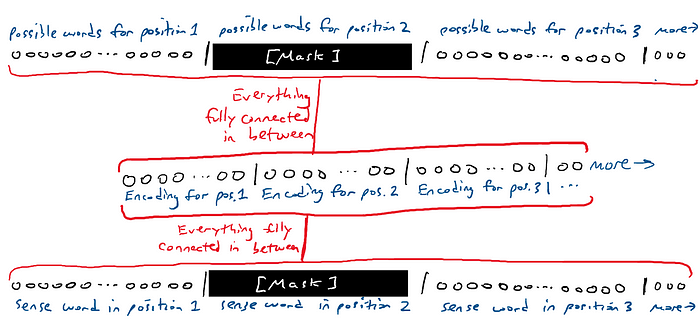
Podemos mover la máscara y hacer que la red adivine diferentes palabras en diferentes lugares.
Un tipo especial de modelo de lenguaje enmascarado solo tiene la máscara al final. Esto se denomina modelo generativo porque la máscara que adivina es siempre la siguiente palabra de la secuencia, lo que equivale a generar la siguiente palabra como si la siguiente palabra no existiera. Como esto:
La [MASCARA]La reina [MASCARA]La reina se sentó [MASCARA]La reina se sentó en [MASCARA]La reina se sentó en [MASCARA]
También llamamos a esto un modelo autorregresivo . La palabra regresivo no suena tan bien. Pero la regresión solo significa tratar de comprender la relación entre las cosas, como las palabras que se han ingresado y las palabras que deberían salir. Auto significa «uno mismo». Un modelo autorregresivo es autopredictivo. Predice una palabra. Luego, esa palabra se usa para predecir la siguiente palabra, que se usa para predecir la siguiente palabra, y así sucesivamente. Esto tiene algunas implicaciones interesantes a las que volveremos más adelante.
6. ¿Qué es un Transformador?
Al momento de escribir este artículo, escuchamos mucho sobre cosas llamadas GPT-3 y GPT-4 y ChatGPT. GPT es una marca particular de un tipo de modelo de lenguaje grande desarrollado por una empresa llamada OpenAI. GPT significa Transformador preentrenado generativo . Desglosemos esto:
- Generativo. El modelo es capaz de generar continuaciones a la entrada proporcionada. Es decir, dado un texto, el modelo trata de adivinar qué palabras vienen a continuación.
- Pre-entrenado . El modelo se entrena en un corpus muy grande de texto general y está diseñado para entrenarse una vez y usarse para muchas cosas diferentes sin necesidad de volver a entrenarse desde cero.
Más información sobre la capacitación previa… El modelo se entrena en un corpus muy grande de texto general que aparentemente cubre una gran cantidad de temas concebibles. Esto significa más o menos «extraído de Internet» en lugar de tomado de algunos repositorios de texto especializados. Al entrenar en texto general, un modelo de lenguaje es más capaz de responder a una gama más amplia de entradas que, por ejemplo, un modelo de lenguaje entrenado en un tipo de texto muy específico, como documentos médicos. En teoría, un modelo de lenguaje entrenado en un corpus general puede responder razonablemente a cualquier cosa que pueda aparecer en un documento en Internet. Podría funcionar bien con el texto médico. Un modelo de lenguaje entrenado solo en documentos médicos podría responder muy bien a entradas relacionadas con contextos médicos, pero ser bastante malo para responder a otras entradas como charlas o recetas.
O el modelo es lo suficientemente bueno en tantas cosas que uno nunca necesita entrenar su propio modelo, o uno puede hacer algo llamado ajuste fino , lo que significa tomar el modelo previamente entrenado y hacerle algunas actualizaciones para que funcione mejor. en una tarea especializada (como médica).
Ahora al transformador…
- Transformador. Un tipo específico de modelo de aprendizaje profundo codificador-decodificador autosupervisado con algunas propiedades muy interesantes que lo hacen bueno en el modelado de lenguaje.
Un transformador es un tipo particular de modelo de aprendizaje profundo que transforma la codificación de una manera particular que facilita adivinar la palabra en blanco. Fue presentado por un artículo llamado Attention is All You Need de Vaswani et al. en 2017. En el corazón de un transformador se encuentra la red clásica de codificador-decodificador. El codificador realiza un proceso de codificación muy estándar. Tan vainilla que te sorprendería. Pero luego agrega algo más llamado autoatención .
6.1 Autoatención
Aquí está la idea de la autoatención: ciertas palabras en una secuencia están relacionadas con otras palabras en la secuencia. Considere la oración «El extraterrestre aterrizó en la tierra porque necesitaba esconderse en un planeta». Si tuviéramos que enmascarar la segunda palabra, «alienígena», y pedirle a una red neuronal que adivine la palabra, tendría una mejor oportunidad debido a palabras como «aterrizado» y «tierra». Del mismo modo, si enmascaramos «eso» y le pedimos a la red que adivine la palabra, la presencia de la palabra «alienígena» podría hacer que sea más probable que prefiera «eso» sobre «él» o «ella».
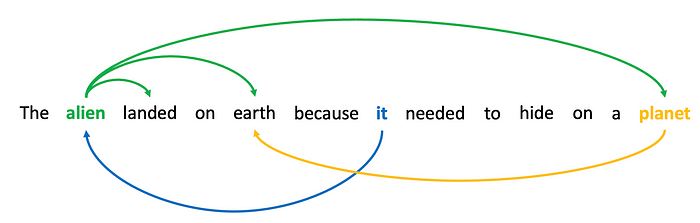
Decimos que las palabras en una secuencia atienden a otras palabras porque capturan algún tipo de relación. La relación no es necesariamente conocida. Podrían ser pronombres de resolución, podría ser una relación de verbo y sujeto, podrían ser dos palabras relacionadas con el mismo concepto («tierra» y «planeta»). Sea lo que sea, saber que existe algún tipo de relación entre las palabras es útil para la predicción.
La siguiente sección entrará en las matemáticas de la autoatención, pero la esencia principal es que un transformador aprende qué palabras en una secuencia de entrada están relacionadas y luego crea una nueva codificación para cada posición en la secuencia de entrada que es una fusión de todas las palabras. palabras relacionadas. Puede pensar en esto como aprender a inventar una nueva palabra que es una mezcla de «alien» y «landed» y «earth» (¿aliandetierra?). Esto funciona porque cada palabra está codificada como una lista de números. Si extranjero = [0.1, 0.2, 0.3, …, 0.4] y aterrizado = [0.5, 0.6, 0.7, …, 0.8] y tierra= [0.9, 1.0, 1.1, …, 1.2], entonces la posición de la segunda palabra podría codificarse como la suma de todas esas codificaciones, [1.5, 1.8, 2.1, …, 2.4], que en sí misma no corresponde a ninguna palabra pero captura pedazos de todas las palabras. De esa manera, cuando el decodificador finalmente ve esta nueva codificación para la palabra en la segunda posición, tiene mucha información sobre cómo se usó la palabra en la secuencia y, por lo tanto, adivina mejor las máscaras. (El ejemplo solo agrega la codificación, pero será un poco más complicado que eso).
6.2. ¿Cómo funciona la autoatención?
La autoatención es la mejora significativa con respecto a las redes de codificador-decodificador de vainilla, por lo que si desea saber más sobre cómo funciona, siga leyendo. De lo contrario, siéntete libre de saltarte esta sección. TL; DR: la autoatención es un nombre elegante de la operación matemática llamada producto punto .
La autoatención ocurre en tres etapas.
(1) Codificamos cada palabra en la secuencia de entrada como de costumbre. Hacemos cuatro copias de las codificaciones de palabras. A uno lo llamamos residual y lo reservamos para su custodia.
(2) Ejecutamos una segunda ronda de codificación (estamos codificando una codificación) en los otros tres. Cada uno se somete a un proceso de codificación diferente, por lo que todos se vuelven diferentes. A uno lo llamamos consulta ( q ), a uno clave ( k ) ya otro valor ( v ).
Quiero que pienses en una tabla hash (también llamada diccionario en python). Tienes un montón de información almacenada en una tabla. Cada fila de la tabla tiene una clave , un identificador único y el valor , los datos que se almacenan en la fila. Para recuperar información de la tabla hash, realiza una consulta. Si la consulta coincide con la clave, extrae el valor.
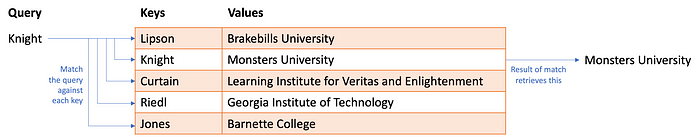
La autoatención funciona un poco como una tabla hash difusa . Usted proporciona una consulta y, en lugar de buscar una coincidencia exacta con una clave, encuentra coincidencias aproximadas en función de la similitud entre la consulta y la clave. Pero, ¿y si la combinación no es una combinación perfecta? Devuelve una fracción del valor. Bueno, esto solo tiene sentido si la consulta, las claves y los valores son todos numéricos. cuales son:
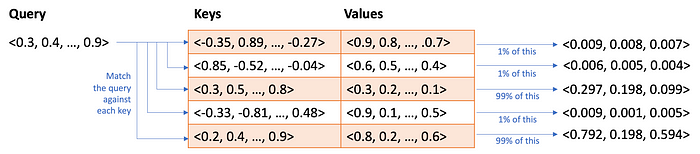
Así que eso es lo que vamos a hacer. Para cada posición de palabra en la entrada, vamos a tomar la codificación q y la codificación k y calcular la similitud. Usamos algo llamado producto escalar, también llamado similitud de coseno. No importante. El punto es que cada palabra es una lista de 256 números (basado en nuestro ejemplo anterior) y podemos calcular la similitud de las listas de números y registrar la similitud en una matriz. Llamamos a esta matriz las puntuaciones de autoatención . Si tuviéramos una secuencia de entrada de tres palabras, nuestros puntajes de atención podrían verse así:
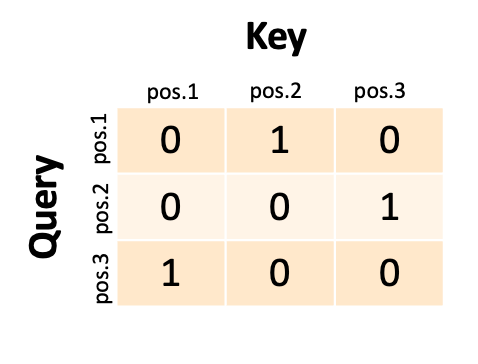
La red trata la primera palabra como una consulta y la compara con la segunda clave (podríamos decir que la primera palabra «atiende» a la segunda palabra). Si la segunda palabra fuera una consulta, coincidiría con la tercera clave. Si la tercera palabra fuera una consulta, coincidiría con la primera clave. En realidad nunca tendríamos unos y ceros como este; tendríamos coincidencias parciales entre 0 y 1 y cada consulta (fila) coincidiría parcialmente con varias claves (columnas).
Ahora, para seguir con la metáfora de la recuperación, multiplicamos esta matriz contra las codificaciones v y sucede algo interesante. Supongamos que nuestras codificaciones v se veían así:

Es decir, la primera palabra se codificó como una lista de números 0,10…0,19, la segunda palabra se codificó como una lista de números 0,20…0,29 y la tercera palabra se codificó como una lista de números 0,30…0,39. Estos números se inventaron con fines ilustrativos y nunca estarían tan ordenados.

La primera consulta coincide con la segunda clave y, por lo tanto, recupera la segunda palabra codificada. La segunda consulta coincide con la tercera clave y, por lo tanto, recupera la tercera palabra codificada. La tercera consulta coincide con la primera clave y, por lo tanto, recupera la primera palabra codificada. ¡Lo que efectivamente hemos hecho es intercambiar filas!

En la práctica, las puntuaciones no serían unos y ceros perfectos y el resultado será un poco de cada codificación mezclada (por ejemplo, el 97 % de la palabra uno más el 1 % o la palabra tres más el 2 % de la palabra dos). Pero esto ilustra cómo la atención propia es una mezcla y un intercambio. En esta versión extrema, la primera palabra se ha cambiado por la segunda, y así sucesivamente. Entonces, tal vez la palabra «tierra» se haya cambiado por la palabra «planeta».
¿Cómo sabemos que codificamos q , k y v correctamente? Si la capacidad general de la red para adivinar la mejor palabra para la máscara mejora, entonces estamos codificando q , k y v correctamente. Si no, cambiamos los parámetros para codificar un poco diferente la próxima vez.
(3) Lo tercero que hacemos es tomar el resultado de todas esas matemáticas y sumarlo al residuo. Recuerde esa primera copia de la codificación original que reservamos. Así es, le agregamos la versión mixta e intercambiada. Ahora, «tierra» no es solo una codificación de «tierra», sino una especie de palabra imaginaria que es una mezcla de «tierra» y «planeta»… ¿pearth? ealanet? Realmente no es así. De todos modos, esta es la codificación transformada final que se enviará al decodificador. Probablemente podamos estar de acuerdo en que tener una palabra falsa en cada posición que realmente codifique dos o más palabras es más útil para hacer predicciones basadas en una sola palabra por posición.
Luego haces esto varias veces más, una tras otra (múltiples capas).
Estoy omitiendo muchos detalles sobre cómo la codificación final del codificador ingresa al decodificador (otra ronda de atención, llamada atención de fuente donde las codificaciones del codificador de cada posición se usan como q y k para aplicarse contra otro versión diferente de v ), pero en este punto debería tener una idea general de las cosas. Al final, el decodificador, tomando la codificación del codificador, envía energía a los brazos del percutor para las palabras, y elegimos la palabra con mayor energía.
7. ¿Por qué los modelos de lenguaje grande son tan poderosos?
Entonces, ¿qué significa todo esto? Los modelos de idiomas grandes, incluidos ChatGPT, GPT-4 y otros, hacen exactamente una cosa: toman un montón de palabras e intentan adivinar qué palabra debe aparecer a continuación. Si esto es «razonar» o «pensar», entonces es solo una forma muy especializada.
Pero incluso esta forma especializada parece muy poderosa porque ChatGPT y similares pueden hacer muchas cosas aparentemente muy bien: escribir poesía, responder preguntas sobre ciencia y tecnología, resumir documentos, redactar correos electrónicos e incluso escribir código, por nombrar solo algunas cosas. ¿Por qué deberían funcionar tan bien?
La salsa secreta es doble. Ya hemos hablado del primero: el transformador aprende a mezclar contextos de palabras de una manera que lo hace realmente bueno para adivinar la siguiente palabra. La otra parte del ingrediente secreto es cómo se entrenan los sistemas. Los modelos de lenguaje grande se entrenan con cantidades masivas de información extraída de Internet. Esto incluye libros, blogs, sitios de noticias, artículos de wikipedia, discusiones de reddit, conversaciones en redes sociales. Durante el entrenamiento, alimentamos un fragmento de texto de una de estas fuentes y le pedimos que adivine la siguiente palabra. Recuerde: auto-supervisado. Si se equivoca, modificamos un poco el modelo hasta que acierta. Si tuviéramos que pensar en lo que un LLM está capacitado para hacer, es producir texto que podría haber aparecido razonablemente en Internet.No puede memorizar Internet, por lo que usa las codificaciones para hacer compromisos y se equivoca un poco, pero con suerte no demasiado.
Es importante no subestimar cuán diverso es el texto en Internet en términos de temas. Los LLM lo han visto todo. Han visto miles de millones de conversaciones sobre casi todos los temas. Entonces, un LLM puede producir palabras que parecen tener una conversación contigo. Ha visto miles de millones de poemas y letras de música en casi todo lo imaginable, por lo que puede producir texto que parece poesía. Ha visto miles de millones de asignaciones de tareas y sus soluciones, por lo que puede hacer conjeturas razonables sobre su tarea, incluso si es ligeramente diferente. Ha visto miles de millones de preguntas de exámenes estandarizados y sus respuestas.
¿Realmente creemos que las preguntas del SAT de este año son tan diferentes a las del año pasado? Ha visto a personas hablar sobre sus planes de vacaciones, por lo que puede adivinar palabras que parecen planes de vacaciones. Ha visto miles de millones de ejemplos de código haciendo todo tipo de cosas. Mucho de lo que hacen los programadores de computadoras es ensamblar piezas de código para hacer cosas muy típicas y bien entendidas en trozos de código más grandes. Por lo tanto, los LLM pueden escribir esos pequeños fragmentos comunes para usted. Ha visto miles de millones de ejemplos de código incorrecto y sus correcciones en stackoverflow.com.
Sí, para que pueda tomar su código roto y sugerir soluciones. Ha visto a miles de millones de personas twittear que tocaron una estufa caliente y se quemaron los dedos, por lo que los LLM saben algo de sentido común. Ha leído muchos artículos científicos, por lo que puede adivinar hechos científicos bien conocidos, incluso si usted no los conoce. Ha visto miles de millones de ejemplos de personas resumiendo, reescribiendo texto en viñetas, describiendo cómo hacer que el texto sea más gramatical, conciso o persuasivo.
Mucho de lo que hacen los programadores de computadoras es ensamblar piezas de código para hacer cosas muy típicas y bien entendidas en trozos de código más grandes. Por lo tanto, los LLM pueden escribir esos pequeños fragmentos comunes para usted. Ha visto miles de millones de ejemplos de código incorrecto y sus correcciones en stackoverflow.com.
Sí, para que pueda tomar su código roto y sugerir soluciones. Ha visto a miles de millones de personas twittear que tocaron una estufa caliente y se quemaron los dedos, por lo que los LLM saben algo de sentido común. Ha leído muchos artículos científicos, por lo que puede adivinar hechos científicos bien conocidos, incluso si usted no los conoce. Ha visto miles de millones de ejemplos de personas resumiendo, reescribiendo texto en viñetas, describiendo cómo hacer que el texto sea más gramatical, conciso o persuasivo.
Mucho de lo que hacen los programadores de computadoras es ensamblar piezas de código para hacer cosas muy típicas y bien entendidas en trozos de código más grandes. Por lo tanto, los LLM pueden escribir esos pequeños fragmentos comunes para usted. Ha visto miles de millones de ejemplos de código incorrecto y sus correcciones en stackoverflow.com. Sí, para que pueda tomar su código roto y sugerir soluciones. Ha visto a miles de millones de personas twittear que tocaron una estufa caliente y se quemaron los dedos, por lo que los LLM saben algo de sentido común. Ha leído muchos artículos científicos, por lo que puede adivinar hechos científicos bien conocidos, incluso si usted no los conoce. Ha visto miles de millones de ejemplos de personas resumiendo, reescribiendo texto en viñetas, describiendo cómo hacer que el texto sea más gramatical, conciso o persuasivo.
Este es el punto: cuando le pide a ChatGPT u otro modelo de lenguaje grande que haga algo inteligente, y funciona, hay una gran posibilidad de que le haya pedido que haga algo de lo que ha visto miles de millones de ejemplos. E incluso si se te ocurre algo realmente único como «dime qué haría Flash Gordon después de comerse seis burritos» (es esto único, ni siquiera lo sé), ha visto Fan Fiction sobre Flash Gordon y ha visto a personas hablando de comer demasiados burritos y puede, debido a la autoatención, mezclar y combinar partes y piezas para armar una respuesta que suene razonable.
Nuestro primer instinto al interactuar con un modelo de lenguaje grande no debería ser «wow, estas cosas deben ser realmente inteligentes o realmente creativas o realmente comprensivas». Nuestro primer instinto debería ser «Probablemente le he pedido que haga algo de lo que ha visto fragmentos antes». Eso podría significar que todavía es realmente útil, incluso si no es «pensar mucho» o «hacer un razonamiento realmente sofisticado».
No tenemos que usar la antropomorfización para entender lo que está haciendo para darnos una respuesta.
Una nota final sobre este tema: debido a la forma en que funcionan los modelos de lenguaje extenso y la forma en que se entrenan, tienden a brindar respuestas que son, en cierto modo, la respuesta promedio. Puede parecer muy extraño para mí decir que el modelo tiende a dar respuestas promedio después de pedir una historia sobre Flash Gordon. Pero en el contexto de una historia o un poema, se puede pensar que las respuestas son lo que muchas personas (escribiendo en Internet) pensarían si tuvieran que comprometerse. No estará mal. Podría ser bastante bueno para los estándares de una sola persona sentada tratando de pensar en algo por su cuenta. Pero tus historias y poemas probablemente también sean promedio (pero son especiales para ti). Lo siento.
8. ¿Qué debo tener en cuenta?
Hay algunas implicaciones realmente sutiles que surgen de cómo funcionan los transformadores y cómo se entrenan. Las siguientes son implicaciones directas de los detalles técnicos.
- Los modelos de lenguaje grande se entrenan en Internet. Eso significa que también se han entrenado en todas las partes oscuras de la humanidad. Los grandes modelos lingüísticos se han entrenado en diatribas racistas, diatribas sexistas, insultos de todo tipo contra todo tipo de personas, personas que hacen suposiciones estereotipadas sobre los demás, teorías de conspiración, desinformación política, etc. Esto significa que las palabras que un modelo lingüístico elige generar pueden regurgitar tal lenguaje.
- Los modelos de lenguaje grande no tienen «creencias centrales». Son adivinadores de palabras; están tratando de predecir cuáles serían las siguientes palabras si la misma oración apareciera en Internet. Por lo tanto, uno puede pedirle a un modelo de lenguaje grande que escriba una oración a favor de algo, o en contra de esa misma cosa, y el modelo de lenguaje cumplirá en ambos sentidos. Estos no son indicios de que crea una cosa u otra, o cambie sus creencias, o que una tenga más razón que otra. Si los datos de entrenamiento tienen más ejemplos de una cosa frente a otra cosa, entonces un modelo de lenguaje grande tenderá a responder de manera más consistente con lo que aparezca en sus datos de entrenamiento con más frecuencia, porque aparece en Internet con más frecuencia. Recuerde: el modelo se esfuerza por emular la respuesta más común.
- Los modelos de lenguaje grande no tienen ningún sentido de la verdad, del bien o del mal. Hay cosas que consideramos hechos, como que la Tierra sea redonda. Un LLM tenderá a decir eso. Pero si el contexto es correcto, también dirá lo contrario porque Internet tiene texto sobre que la Tierra es plana. No hay garantía de que un LLM proporcione la verdad. Puede haber una tendencia a adivinar palabras que acordamos que son verdaderas, pero eso es lo más cerca que podemos estar de hacer afirmaciones sobre lo que un LLM «sabe» sobre la verdad, lo correcto o lo incorrecto.
- Los modelos de lenguaje grande pueden cometer errores. Los datos de entrenamiento pueden tener mucho material inconsistente. Es posible que la atención propia no preste atención a todas las cosas que queremos que haga cuando hacemos una pregunta. Como adivinador de palabras, puede hacer conjeturas desafortunadas. A veces, los datos de entrenamiento han visto una palabra tantas veces que prefieren esa palabra incluso cuando no tiene sentido para la entrada. Lo anterior da lugar a un fenómeno que se denomina “ alucinación” .” donde se adivina una palabra que no se deriva de la entrada ni “correcta”. Los LLM tienen inclinaciones a adivinar números pequeños en lugar de números grandes porque los números pequeños son más comunes. Así que los LLM no son buenos en matemáticas. Los LLM tienen preferencia por el número «42» porque los humanos lo hacen debido a un libro famoso en particular. Los LLM tienen preferencias por nombres más comunes, por lo que pueden inventar los nombres de los autores.
- Los modelos de lenguaje grande son autorregresivos. Por lo tanto, cuando hacen conjeturas que podríamos considerar deficientes, esas palabras adivinadas se agregan a sus propias entradas para hacer que la siguiente palabra sea conjetura. Es decir: los errores se acumulan. Incluso si solo hay un 1% de probabilidad de error, entonces la autoatención puede atender esa elección equivocada y duplicar ese error. Incluso si solo se comete un error, todo lo que viene después puede estar relacionado con ese error. Entonces, el modelo de lenguaje podría cometer errores adicionales además de eso. Los transformadores no tienen una forma de «cambiar de opinión» o intentarlo de nuevo o autocorregirse. Van con la corriente.
- Uno siempre debe verificar los resultados de un modelo de lenguaje grande. Si le pide que haga cosas que usted mismo no puede verificar de manera competente, entonces debe pensar si está de acuerdo con actuar sobre los errores que se cometen. Para tareas de bajo riesgo, como escribir una historia corta, eso podría estar bien. Para tareas de alto riesgo, como tratar de obtener información para decidir en qué acciones invertir, tal vez esos errores puedan hacer que tome una decisión muy costosa.
- La autoatención significa que cuanta más información proporcione en el indicador de entrada, más especializada será la respuesta porque mezclará más de sus palabras en sus conjeturas. La calidad de la respuesta es directamente proporcional a la calidad del indicador de entrada. Mejores indicaciones producen mejores resultados. Pruebe varias indicaciones diferentes y vea cuál funciona mejor para usted. No asuma que el modelo de lenguaje «capta» lo que está tratando de hacer y dará lo mejor de sí la primera vez.
- No estás realmente “teniendo una conversación” con un modelo de lenguaje grande. Un modelo de lenguaje grande no “recuerda” lo que ha sucedido en el intercambio. Su entrada entra. La respuesta sale. El LLM no recuerda nada. Su entrada inicial, la respuesta y su respuesta a la respuesta entran. Por lo tanto, si parece que está recordando, es porque el registro de las conversaciones se convierte en una entrada nueva y fresca. Este es un truco de programación en el front-end para hacer que el modelo de lenguaje grande parezca estar teniendo una conversación. Probablemente se mantendrá en el tema debido a este truco, pero no hay garantía de que no contradiga sus respuestas anteriores. Además, hay un límite en la cantidad de palabras que se pueden introducir en el modelo de lenguaje grande (actualmente ChatGPT permite aproximadamente 4000 palabras y GPT-4 permite aproximadamente 32 000 palabras). Los tamaños de entrada pueden ser bastante grandes, por lo que la conversación a menudo parecerá coherente durante un tiempo. Eventualmente, el registro acumulado será demasiado grande y el comienzo de la conversación se eliminará y el sistema «olvidará» las cosas anteriores.
- Los modelos de lenguaje grande no solucionan problemas ni planifican. Pero puede pedirles que creen planes y resuelvan problemas. Voy a dividir algunos pelos aquí. La resolución de problemas y la planificación son términos reservados por ciertos grupos en la comunidad de investigación de IA para referirse a algo muy específico. En particular, significan tener una meta, algo que desea lograr en el futuro, y trabajar hacia esa meta eligiendo entre alternativas que probablemente lo acerquen a esa meta. Los modelos de lenguaje grande no tienen objetivos. Tienen un objetivo, que es elegir una palabra que probablemente aparezca en los datos de entrenamiento dada una secuencia de entrada. Son de coincidencia de patrones. La planificación, en particular, generalmente implica algo llamado anticipación. Cuando los humanos planifican, imaginan los resultados de sus acciones y analizan ese futuro con respecto a la meta. Si parece que te acerca a una meta, es un buen movimiento. Si no es así, podríamos intentar imaginar los resultados de otra acción. Hay mucho más que eso, pero los puntos clave son que los grandes modelos de lenguaje no tienen metas y no miran hacia el futuro.. Los transformadores miran hacia atrás. La autoatención solo se puede aplicar a las palabras de entrada que ya han aparecido. Ahora, los modelos de lenguaje grande pueden generar resultados que parecen planes porque han visto muchos planes en los datos de entrenamiento. Saben cómo son los planes, saben qué debe aparecer en los planes sobre ciertos temas que han visto. Va a hacer una buena conjetura sobre ese plan. El plan puede ignorar detalles particulares sobre el mundo y tender hacia el plan más genérico. Los modelos de lenguaje extenso ciertamente no han “pensado en las alternativas” o probado una cosa y retrocedido y probado otra cosa. No hay ningún mecanismo dentro de un transformador que uno pueda señalar que haga una consideración tan ida y vuelta del futuro. (Hay una advertencia a esto, que aparecerá en la siguiente sección.
9. ¿Qué hace que ChatGPT sea tan especial?
“Escuché que RLHF es lo que hace que ChatGPT sea realmente inteligente”.
“ChatGPT utiliza el aprendizaje por refuerzo y eso es lo que lo hace tan inteligente”.
Especie de.
En el momento de escribir este artículo, hay mucho entusiasmo por algo llamado RLHF, o Aprendizaje por refuerzo con retroalimentación humana . Hay un par de cosas que se hicieron para entrenar ChatGPT en particular (y cada vez más otros modelos de lenguaje grande). No son exactamente nuevos, pero se introdujeron ampliamente con gran efecto cuando se lanzó ChatGPT.
ChatGPT es un modelo de lenguaje grande basado en transformadores. ChatGPT se ganó la reputación de ser realmente bueno en la producción de respuestas a las indicaciones de entrada y por negarse a responder preguntas sobre ciertos temas que podrían considerarse tóxicos u obstinados. No hace nada particularmente diferente de lo que se describe arriba. De hecho, es bastante vainilla. Pero hay una diferencia: cómo fue entrenado. ChatGPT se entrenó con normalidad: raspando una gran parte de Internet, tomando fragmentos de ese texto y haciendo que el sistema prediga la siguiente palabra. Esto resultó en un modelo base que ya era un predictor de palabras muy poderoso (equivalente a GPT-3). Pero luego hubo dos pasos de entrenamiento adicionales. Ajuste de instrucciones y aprendizaje por refuerzo con retroalimentación humana.
9.1. Ajuste de instrucciones
Hay un problema particular con los modelos de lenguaje grandes: solo quieren tomar una secuencia de entrada de palabras y generar lo que viene a continuación. La mayoría de las veces, eso es lo que uno quiere. Pero no siempre. Considere la siguiente solicitud de entrada:
“Escribe un ensayo sobre Alexander Hamilton”.
¿Cuál crees que debería ser la respuesta? Probablemente estés pensando que debería ser algo como “Alexander Hamilton nació en Nevis en 1757. Fue estadista, abogado, coronel del ejército y primer secretario del Tesoro de los Estados Unidos…” Pero lo que en realidad podrías obtener es:
“Tu ensayo debe tener al menos cinco páginas, a doble espacio e incluir al menos dos citas”.
¿Lo que acaba de suceder? Bueno, el modelo de lenguaje podría haber visto muchos ejemplos de tareas de estudiantes que comienzan con «Escribe un ensayo sobre…» e incluye palabras que detallan la longitud y el formato. Por supuesto, cuando escribiste «Escribe un ensayo…», pensabas que estabas escribiendo instrucciones al modelo de lenguaje como si fuera un humano que entendiera la intención. Los modelos de lenguaje no entienden tu intención o no tienen sus propias intenciones; solo hacen coincidir las entradas con los patrones que han visto en sus datos de entrenamiento.
Para solucionar esto, se puede hacer algo llamado ajuste de instrucciones . La idea es bastante simple. Si obtiene una respuesta incorrecta, escriba cuál debería ser la respuesta correcta y envíe la entrada original y la nueva salida corregida a través de la red neuronal como datos de entrenamiento. Con suficientes ejemplos de la salida corregida, el sistema aprenderá a cambiar su circuito para que se prefiera la nueva respuesta.
Uno no tiene que hacer nada demasiado elegante. Simplemente haga que mucha gente interactúe con el modelo de lenguaje grande y pídale que haga muchas cosas y escriba las correcciones cuando no se comporte correctamente. Luego recopile todos esos ejemplos en los que cometió errores y los nuevos, corrija los resultados y haga más entrenamiento.
Esto hace que el modelo de lenguaje grande actúe como si entendiera la intención de las indicaciones de entrada y actúe como si estuviera siguiendo instrucciones. No está haciendo nada más que tratar de adivinar la siguiente palabra. Pero ahora los nuevos datos de entrenamiento lo tienen adivinando palabras que parecen responder mejor a la entrada.
9.2. Aprendizaje por refuerzo a partir de la retroalimentación humana
El siguiente paso en el entrenamiento es el aprendizaje por refuerzo a partir de la retroalimentación humana. Creo que esto va a requerir un poco de explicación.
El aprendizaje por refuerzo es una técnica de IA utilizada tradicionalmente en algunas investigaciones de robótica y también en agentes de juegos virtuales (piense en sistemas de IA que pueden jugar ajedrez, go o StarCraft). El aprendizaje por refuerzo es especialmente bueno para averiguar qué hacer cuando recibe algo llamado recompensa.. La recompensa es solo un número que indica qué tan bien se está haciendo (+100 por hacerlo muy bien; -100 por hacerlo muy mal). En el mundo real y en los juegos, la recompensa a menudo se otorga en raras ocasiones. En un juego, es posible que tengas que hacer muchos movimientos antes de obtener puntos. Tal vez solo obtienes puntos al final del juego. En el mundo real, simplemente no hay suficientes personas que le digan cuándo está haciendo un buen trabajo (lo está haciendo). A menos que seas un perro (todos son buenos niños y niñas). Lo único que realmente necesita saber es que los sistemas de aprendizaje por refuerzo intentan predecir cuánta recompensa futura obtendrán y luego eligen la acción que es más probable que obtenga más recompensa futura. No es del todo diferente a la forma en que uno podría usar golosinas para perros para enseñarle a comportarse.
De acuerdo, guarda todo eso y considera el siguiente aviso:
¿En qué es experto Mark?
Supongamos que la salida del modelo de lenguaje es:
Mark tiene muchas publicaciones en inteligencia artificial, gráficos e interacción humano-computadora.
Eso es solo parcialmente correcto. No publico en gráficos. Realmente me gustaría darle a esto un pulgar hacia abajo o una puntuación de -1. Pero solo una parte está mal: la palabra gráficos. Si le digo al sistema que toda la oración es incorrecta, el modelo de lenguaje podría aprender que todas esas palabras deben evitarse. Bueno, muchas de esas palabras son razonables.
Aquí es donde entra en juego el aprendizaje por refuerzo. El aprendizaje por refuerzo funciona al probar diferentes alternativas y ver qué alternativas obtienen la mayor recompensa. Supongamos que le pido que genere tres respuestas diferentes al aviso original.
Mark tiene muchas publicaciones en inteligencia artificial, gráficos e interacción humano-computadora.
Mark ha trabajado en inteligencia artificial, sistemas seguros de PNL e interacción humano-computadora.
Marque como investigación la inteligencia artificial, la IA del juego y los gráficos.
Podría dar un pulgar hacia abajo (-1) a la primera alternativa, un pulgar hacia arriba (+1) a la segunda alternativa y un pulgar hacia abajo (-1) a la tercera alternativa. Al igual que jugar un juego, un algoritmo de aprendizaje por refuerzo puede mirar hacia atrás y darse cuenta de que la única cosa en común que da como resultado un -1 es la palabra «gráficos». Ahora el sistema puede concentrarse en esa palabra y ajustar el circuito de la red neuronal para que no use esa palabra junto con esa indicación de entrada en particular.
Una vez más, conseguiremos que un grupo de personas interactúen con el modelo de lenguaje grande. Esta vez le daremos a la gente tres (o más) posibles respuestas. Podemos hacer esto pidiéndole al modelo de lenguaje grande que responda a un aviso varias veces e introduzca un poco de aleatoriedad en la selección de los brazos delanteros (no se olvidó de eso, ¿verdad?). En lugar de elegir el brazo delantero activado más alto, a veces podemos elegir el segundo o tercer brazo delantero activado más alto. Esto da diferentes respuestas de texto y le pedimos a las personas que elijan su primera respuesta favorita, la segunda favorita, y así sucesivamente. Ahora tenemos alternativas y tenemos números. Ahora podemos usar el aprendizaje por refuerzo para ajustar el circuito de la red neuronal.
[En realidad, usamos estos comentarios de pulgares hacia arriba y hacia abajo para entrenar una segunda red neuronal para predecir si las personas darán un pulgar hacia arriba o hacia abajo. Si esa red neuronal es lo suficientemente buena para predecir lo que preferirán las personas, entonces podemos usar esta segunda red neuronal para adivinar si las respuestas del modelo de lenguaje podrían obtener aprobación o desaprobación y usar eso para entrenar el modelo de lenguaje.]
Lo que hace el aprendizaje por refuerzo es tratar la generación de texto como un juego donde cada acción es una palabra. Al final de una secuencia, se le dice al modelo de lenguaje si ganó o perdió algunos puntos. El modelo de lenguaje no hace exactamente una búsqueda anticipada como se discutió en la sección anterior, pero en cierto sentido ha sido entrenado para predecir qué palabras obtendrán el visto bueno. El modelo de lenguaje extenso todavía no tiene un objetivo explícito, pero tiene un objetivo implícito de «obtener aprobación» (o también podríamos decir que tiene el objetivo implícito de «satisfacer a la persona promedio») y ha aprendido a correlacionar ciertas respuestas a ciertas indicaciones con obtener pulgares hacia arriba. Esto tiene muchas cualidades de planificación, pero sin un mecanismo de anticipación explícito. Más bien tiene estrategias memorizadas para obtener recompensas que tienden a funcionar en muchas situaciones.
En cuanto a si RLHF hace que ChatGPT sea más inteligente… hace que ChatGPT sea más probable que produzca el tipo de respuestas que esperábamos ver. Parece más inteligente porque sus salidas parecen transmitir la sensación de que comprende las intenciones de nuestras entradas y tiene sus propias intenciones de responder. Esto es una ilusión porque sigue siendo solo codificar y decodificar palabras. Pero, de nuevo, ahí es donde comenzamos este artículo 😉.
El ajuste de instrucciones y RLHF también hacen que el uso de ChatGPT sea resistente a ciertos tipos de abusos, como la generación de contenido racista, sexista o políticamente cargado. Todavía se puede hacer y, en cualquier caso, las versiones anteriores de GPT-3 siempre han podido hacerlo. Sin embargo, como un servicio público gratuito, la fricción que crea ChatGPT contra ciertos tipos de abuso transmite una sensación de seguridad. También es resistente a proporcionar una opinión como un hecho, lo que también elimina una forma de daño potencial para el usuario.
[El uso del aprendizaje por refuerzo para modificar un modelo de lenguaje previamente entrenado no es nuevo. Se remonta al menos a 2016 y se ha utilizado para hacer que los modelos de lenguaje grandes sean más seguros. La mayoría de los ajustes basados en el aprendizaje por refuerzo de modelos de lenguaje grandes utilizan un segundo modelo para proporcionar una recompensa, que también se hace con ChatGPT. ChatGPT se destaca por la escala del sistema que se ajusta con el aprendizaje por refuerzo y el esfuerzo de recopilación de comentarios humanos a gran escala.]
10. Conclusiones
Necesito dormir más. Eso es lo que concluyo de todo esto.



